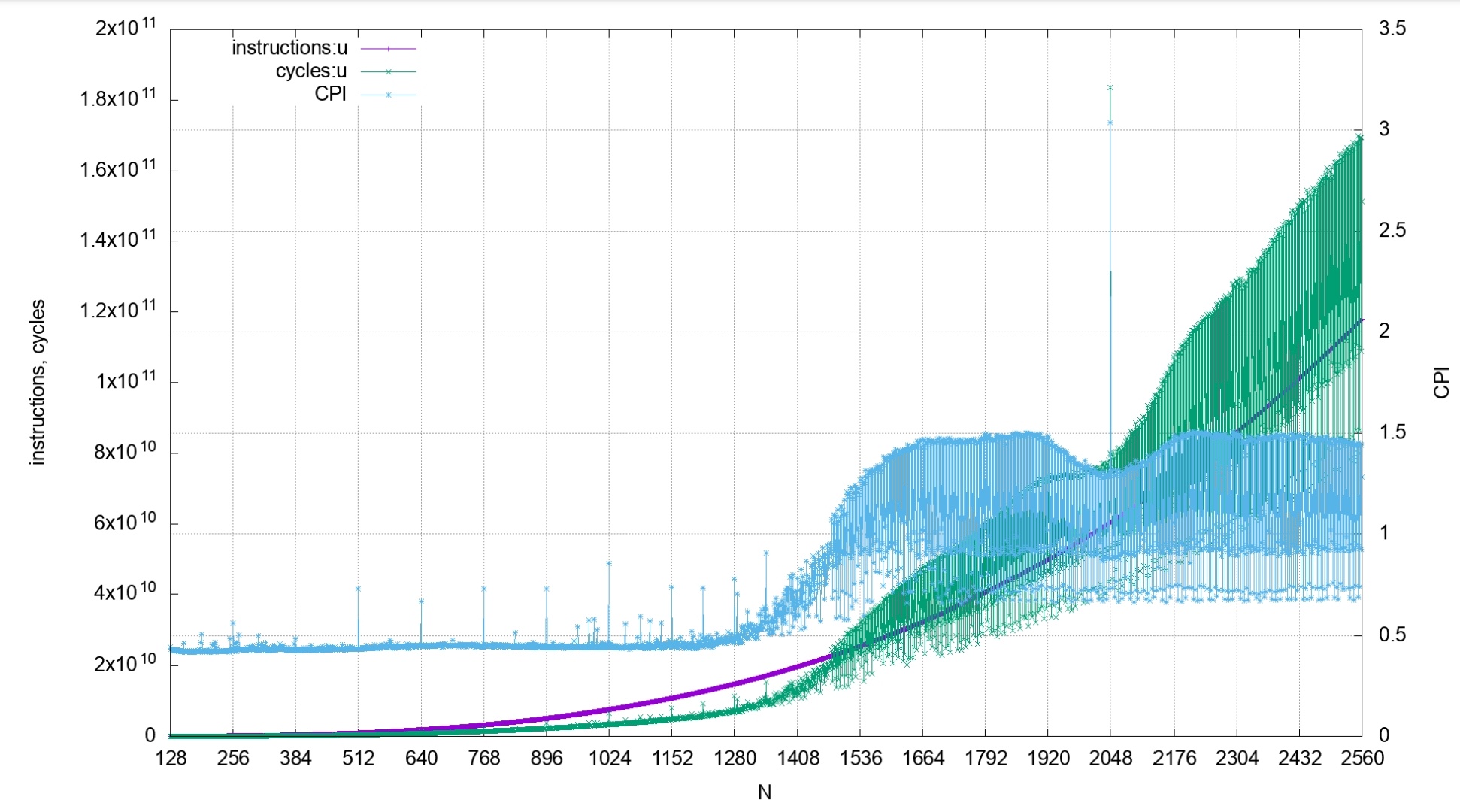
I would love some logarithmic y axes on these plots. As is, the faster versions are basically horizontal lines, making one think whether perhaps something might be wrong with the benchmark and the compiler just optimised everything away to an empty function.
Sinilarly, what's going on with the performance of bisect_left_c? (Second graph.) Why is the graph completely flat at first, only to then ramp up with a perfectly straight line? If you add some measurement points in between, will it turn out the high measurement on the right of the graph is actually a measurement error?
Thanks for the feedback! I experimented with using the matplotlib `plt.xscale("log")` function, but because the x axis already distributed by powers of 2, it to some extent is already a log axis (unless I'm making a very wrong assumption). I was curious about the behavior of the lines, and how they seem to ramp up in weird ways. I tried to mitigate by increasing the number of samples in the benchmark, but I haven't been able to get graphs that look as nice as the original article. I think to some extent though, that is because the `sortedcontainers` implementation is so bad. If the `y` axis was scaled better, you would be able to see a more linear increase in execution time.
Also, if you want to, the repo provides a build script for the C-extension so you can mess around with the benchmarks. I would love for you to find some bugs in my implementation :).
> > I would love some logarithmic y axes on these plots.
> I experimented with using the matplotlib `plt.xscale("log")` function, but because the x axis already distributed by powers of 2, [...]
I said y, not x ;)
Also, the x axis is not distributed by powers of 2, right? I see 0 through roughly 2.7*10^8 — either that or the axis is confusingly labeled. :)
I would want two graphs here:
1. High-res linear-linear to show the expected logarithmic behaviour (surely binary search is logarithmic, right?), as well as possibly some performance cliff as you run out of cache and start hitting RAM for a decent part of the search.
2. Linear x but logarithmic y, on which you compare the various implementations. The point is that because all implementations presumably have the same complexity, and furthermore probably have caching issues starting from similar (though not necessarily equal) points, the most interesting point of info is their _ratio_. And since log(2*f(x)) = log(2) + log(f(x)), the ratio between two functions is simply their _distance_ on an yscale("log") plot. Much easier to see, especially if the ratio is like 100x.
Perhaps you'll even see that for sufficiently large inputs, the ratio shrinks because the search becomes memory-bound. :)
Ah, that is fair. I misinterpreted your point. The reason I say the x axis is distributed by powers of two is because it is only evaluated at powers of two:
sizes = [2**i for i in range(1, 29)]
The limits that matplotlib fills in are largely superficial, the benchmarks and the x axis are only being evaluated at powers of two.
Your points about the other two graphs though is very good. I think my graphs could use some clarity.
The main reason why I didn't use a log scale and compute on much much larger inputs is mainly because it would just take too long for my laptop to compute.
Oh I see! That makes sense, but is also quite dangerous: caching issues tend to result in fascinating effects around powers of two. I once benchmarked a fairly naive matrix multiplication algorithm on almost every size between 1 and 2100, and the powers of 2, especially 2048, had the most amazing non-monotonic effects around and on them. Even sizes also strongly differed from odd sizes.
Now for binary search that effect will be smaller, but still, at powers of two you might more quickly get that consecutive probes have the same remainder modulo the number of cache sets, meaning they get put in the same cache set and hence conflict much harder than one might expect.
All that to say: more samples, in between the ones you already have, would be quite nice. Especially on random input sizes (but _also_ on round numbers!), just to rule out any of the above-mentioned shenanigans. (I particularly suspect the large 2^28 sample as perhaps falling prey to this, but perhaps not.)
That makes a lot of sense to me--I added another graph to the README which shows the performance at every size between 0 and 2*15, rather than just powers of two :). It is in images as "4.jpeg".
Hey if you take your dataframe or Python object and print it to the console and throw it in a gist, folks in this convo could give you some great charts.
The python objects are all created on demand by the benchmarking code in the repository—changing the “sizes” object will change the number of samples/etc.
> This is the second time that I came across an algorithm in Knuth’s books that is brilliant and should be used more widely but somehow was forgotten. Maybe I should actually read the book… It’s just really hard to see which ideas are good and which ones aren’t. For example immediately after sketching out Shar’s algorithm, Knuth spends far more time going over a binary search based on the Fibonacci sequence. It’s faster if you can’t quickly divide integers by 2, and instead only have addition and subtraction. So it’s probably useless, but who knows? When reading Knuth’s book, you have to assume that most algorithms are useless, and that the good things have been highlighted by someone already. Luckily for people like me, there seem to still be a few hidden gems.
If "execution time (s)" reads 0 for one of your measured cases, I become extremely skeptical of your measurements. I get that the measurement probably just rounded down but that alongside a perfectly straight horizontal line just makes me go "what's going on here? What conclusion can I draw from this other than that the algorithm is somehow O(1)?"
Is the value being plotted the average time per execution? You ran each test scenario for a while, not once, I assume.
It's also worth considering whether you should measure against the same dataset and value every time, or have a bunch of different ones. If it's the same dataset and value it's possible you're priming the branch predictor tables, or worse, favoring one algorithm by accident due to the layout of the data.
Yeah it’s difficult because all the times are by default in seconds from ‘timeit’. I think the sortedcontainers impl is just really, really bad, and that’s why that graph looks so flat in comparison. The datasets and search values are generated on each loop in the benchmark, so hopefully no priming issues.
If anyone has the time & energy to put into figuring out a production quality open source version of this, one place that could benefit is numpy's searchsorted function
I am very confused why am I am unable to solve the problem, but I added all of the images to a folder in the repo so you can take a look at them there. Still unable to resolve the error on Chrome on my machine.
I also can't load the images. I get a "image can't be loaded because it contains errors" error on Firefox mobile nightly and and just a failure on brave on mobile.
Besides that error; the images are each above 1mb and very low quality. I believe if you just save them as pngs you should get much more quality at 20% the size.
There are some provisos to the “Branchless” tag that are covered in the article I drew inspiration from. One of which is that a “CMOVE” is not technically a branch :)
I was considering doing it all in a ternary statement, but I feel that the current form is also branchless because it is simply a multiply and add. The extra bounds-checking condition can probably be omitted, but I haven't tested that.
for (step >>= 1; step != 0; step >>=1) {
if ((next = begin + step) < size) {
begin += PyObject_RichCompareBool(PyList_GetItem(list_obj, next), value, Py_LT) * step;
}
}
Ah, yeah I see what you mean. If I'm understanding you correctly, the fact that we are calling the Python interpreter internal functions during that calculation makes it branch because it is not pre-calculated?
Except that arr[...] - value may overflow, and is UB in C.
Even removing the UB with something like __builtin_sub_overflow(), if arr[...] is INT_MAX and value is -2, then the difference will have the high bit set!
I haven't tried it, but this should compile to a cmove or seta, not a jump:
int cond = arr[step+begin] < value;
begin += step & -cond;
{kind=link}
{kind=link}
Sinilarly, what's going on with the performance of bisect_left_c? (Second graph.) Why is the graph completely flat at first, only to then ramp up with a perfectly straight line? If you add some measurement points in between, will it turn out the high measurement on the right of the graph is actually a measurement error?
If this works it would make a nice python lib.