> > I would love some logarithmic y axes on these plots.
> I experimented with using the matplotlib `plt.xscale("log")` function, but because the x axis already distributed by powers of 2, [...]
I said y, not x ;)
Also, the x axis is not distributed by powers of 2, right? I see 0 through roughly 2.7*10^8 — either that or the axis is confusingly labeled. :)
I would want two graphs here:
1. High-res linear-linear to show the expected logarithmic behaviour (surely binary search is logarithmic, right?), as well as possibly some performance cliff as you run out of cache and start hitting RAM for a decent part of the search.
2. Linear x but logarithmic y, on which you compare the various implementations. The point is that because all implementations presumably have the same complexity, and furthermore probably have caching issues starting from similar (though not necessarily equal) points, the most interesting point of info is their _ratio_. And since log(2*f(x)) = log(2) + log(f(x)), the ratio between two functions is simply their _distance_ on an yscale("log") plot. Much easier to see, especially if the ratio is like 100x.
Perhaps you'll even see that for sufficiently large inputs, the ratio shrinks because the search becomes memory-bound. :)
Ah, that is fair. I misinterpreted your point. The reason I say the x axis is distributed by powers of two is because it is only evaluated at powers of two:
sizes = [2**i for i in range(1, 29)]
The limits that matplotlib fills in are largely superficial, the benchmarks and the x axis are only being evaluated at powers of two.
Your points about the other two graphs though is very good. I think my graphs could use some clarity.
The main reason why I didn't use a log scale and compute on much much larger inputs is mainly because it would just take too long for my laptop to compute.
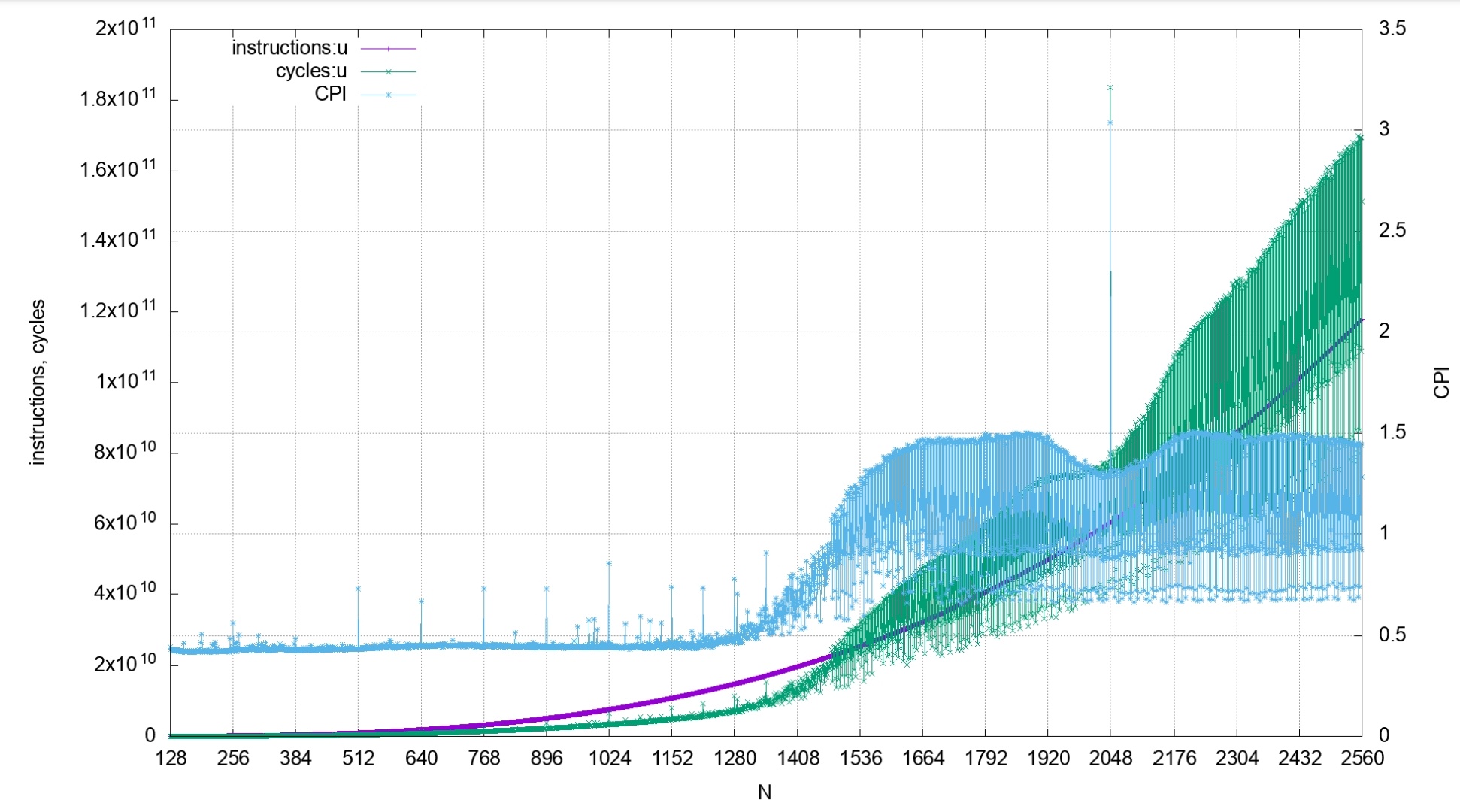
Oh I see! That makes sense, but is also quite dangerous: caching issues tend to result in fascinating effects around powers of two. I once benchmarked a fairly naive matrix multiplication algorithm on almost every size between 1 and 2100, and the powers of 2, especially 2048, had the most amazing non-monotonic effects around and on them. Even sizes also strongly differed from odd sizes.
Now for binary search that effect will be smaller, but still, at powers of two you might more quickly get that consecutive probes have the same remainder modulo the number of cache sets, meaning they get put in the same cache set and hence conflict much harder than one might expect.
All that to say: more samples, in between the ones you already have, would be quite nice. Especially on random input sizes (but _also_ on round numbers!), just to rule out any of the above-mentioned shenanigans. (I particularly suspect the large 2^28 sample as perhaps falling prey to this, but perhaps not.)
That makes a lot of sense to me--I added another graph to the README which shows the performance at every size between 0 and 2*15, rather than just powers of two :). It is in images as "4.jpeg".
{kind=link}
> I experimented with using the matplotlib `plt.xscale("log")` function, but because the x axis already distributed by powers of 2, [...]
I said y, not x ;)
Also, the x axis is not distributed by powers of 2, right? I see 0 through roughly 2.7*10^8 — either that or the axis is confusingly labeled. :)
I would want two graphs here: 1. High-res linear-linear to show the expected logarithmic behaviour (surely binary search is logarithmic, right?), as well as possibly some performance cliff as you run out of cache and start hitting RAM for a decent part of the search. 2. Linear x but logarithmic y, on which you compare the various implementations. The point is that because all implementations presumably have the same complexity, and furthermore probably have caching issues starting from similar (though not necessarily equal) points, the most interesting point of info is their _ratio_. And since log(2*f(x)) = log(2) + log(f(x)), the ratio between two functions is simply their _distance_ on an yscale("log") plot. Much easier to see, especially if the ratio is like 100x.
Perhaps you'll even see that for sufficiently large inputs, the ratio shrinks because the search becomes memory-bound. :)