I spent time working with Andrej and the rest of the FSD team back in 2020/2021, and we had plenty of conversations on how human visual processing maps onto our neural network architectures.
Our approach—transformer-based attention blocks, multi-scale feature extraction, and temporal fusion—mirrors elements of the biological visual cortex (retina → LGN → V1 → V2 → V4 → IT) which break down raw inputs and integrate them over time. It’s amazing how closely this synthetic perceptual pipeline parallels the way our own brains interpret the world.
The key insight we discovered was that explicitly enforcing brain-like topographic organization (as some academic work attempts - such as this one here) isn't necessary - what matters is having the right functional components that parallel biological visual processing. Our experience showed that the key elements of biological visual processing - like hierarchical feature extraction and temporal integration - emerge naturally when you build architectures that have to solve real visual tasks.
The brain's organization serves its function, not the other way around. This was validated by the real-world performance of our synthetic visual cortex in the Tesla FSD stack.
We can think of a solution space, with potentially many good solutions to the vision problem, and we can, in science fiction-like speculation, that the other solutions will be very different and surprise us.
Then this experiment shows its solution is the same we already knew, and that's it.
Then there aren't many good potential solutions, there is only one, and the ocean of possibilities becomes the pond of this solution.
The convolutional kernels in the first levels do converge to Gabors like the ones in V1 (and there were math works in the 90-ies, in neuro research, about optimality of such kernels) so it wouldn't be surprising if higher levels would converge to something that is similar to the higher levels of visual cortex (like hierarchical feature aggregation that is nicely illustrated by deep dreaming and also feels like it can be optimal under reasonable conditions and thus would be expected to emerge).
Did you read the part where he explicitly mentioned that they discovered how enforcing that architecture was not necessary, as it would emerge on its own?
Unlike neural networks the brain contains massive numbers of lateral connections. This, combined with topographical organization, allows it to do within layer temporal predictions as activations travel across the visual field, create active competition between similarly tuned neurons in a layer (forming natural sub networks), and quite a bit more. So, yeah, the brain's organisation serves it's function, and it does so very very well.
They probably don’t. They’re very different. LLM’s seem to be based on pragmatic, mathematical techniques developed over time to produce patterns from data.
There’s at least three fields in this:
1. Machine learning using non-neurological techniques (most stuff). These use a combination of statistical algorithms stitched together with hyperparameter tweaking. Also, usually global optimization by heavy methods like backpropagation.
2. “Brain-inspired” or “biologically accurate”algorithms that try to imitate the brain. They sometimes include evidence their behavior matches experimental observations of brain behavior. Many of these use complex neurons, spiking nets, and/or local learning (Hebbian).
(Note: There is some work on hybrids such as integrating hippocampus-like memory or doing limited backpropagation on Hebbian-like architectures.)
3. Computational neuroscience which aims to make biologically-accurate models at various levels of granularity. Their goal is to understand brain function. A common reason is diagnosing and treating neurological disorders.
Making an LLM like the brain would require use of brain-inspired components, multiple systems specialized for certain tasks, memory integrated into all of them, and a brain-like model for reinforcement. Imitating God’s complex design is simply much more difficult than combining proven algorithms that work well enough. ;)
That said, I keep collecting work on both efficient ML and brain-inspired ML. I think some combination of the techniques might have high impact later. I think the lower, training costs of some brain-inspired methods, especially Hebbian learning, justify more experimentation by small teams with small, GPU budgets. Might find something cost-effective in that research. We need more of it on common platforms, too, like HughingFace libraries and cheap VM’s.
The main reason topography emerges in physical brains is because spatially distant connections are physically difficult and expensive in biological systems. Artificial neural nets have no such trade-off. So what's the motivation here? I can understand this might be a very good regularizer, so it could help with generalization error on small-data tasks. But hard to see why this should be on the critical path to AGI. As compute and data grows, you want less inductive bias. For example, CNN will beat ViT on small data tasks, but that flips with enough scale because ViT imposes less inductive bias. Or at least any inductive bias should be chosen because it models the structure of the data well, such as with causal transformers and language.
Locality of data and computation is very important in neural nets. It's the number one reason why training and inference are as slow as they are. It's why GPUs need super expensive HBM memory, why NVLink is a thing, why Infiniband is a thing.
If the problem of training and inference on neural networks can be optimized so that a topology can be used to keep closely related data together, we will see huge advancements in training and inference speed, and probably in model size as a result.
And speed isn't just speed. Speed makes impossible (not enough time in our lifetime) things possible.
A huge factor in Deepseek being able to train on H800 (half HBM bandwith as H100) is that they used GPU cores to compress/decompress the data moved around between the GPU memory and the compute units. This reduces latency in accessing data and made up for the slower memory bandwith (which translates in higher latency when fetching data). Anything that reduces the latency of memory accesses is a huge accelerator for neural nets. The number one way to achieve this is to keep related data next to each other, so that it fits in the closest caches possible.
It's true, but isn't OP also correct? Ie. it's about speed, which implies locality, which implies approaches like MoE which does exactly that and it's unlike physical brain topology?
Having said that it would be fun to see things like rearrangement data moves based on temerature of silicon parts after training cycle.
Well, locality and the global nature of pre-training methods. The brain mostly uses local learning (Hebbian learning) which requires less, data movement. AI firms putting as much money into making that scale as they did on backpropagation might drop costs a lot.
Unless GPUs work markedly differently somehow or there’s been some fundamental shift in computer architecture I’m not aware of, spatial locality is still a factor in computers.
Aside from HW acceleration today, designs like Cebras would benefit heavily by reducing the amount of random access from accessing the weights (and thus freeing up cross-chip memory bandwidth for other things).
This makes me remember game developers back when games could still be played directly from the physical disc. They would often duplicate data to different parts of the disc, knowing that certain data would often be streamed from disc together, so that seek times were minimized.
But those game devs knew where everything was spatially on the disc, and how the data would generally be used during gameplay. It was consistent.
Do engineers have a lot of insight into how models get loaded spatially onto a given GPU at run time? Is this constant? Is it variable on a per GPU basis? I would think it would have to be.
Right now models have no structure so that access is random but you definitely know where the data is located in memory since you put it there. It doesn’t matter about the physical location - it’s all through a TLB but if you ask the GPU for a contiguos memory allocation it gives it to you. This is probable the absolute easiest thing to optimize for if your data access pattern is amenable to it.
Haven’t read the paper but my guess around that is that the same reason sparse attention networks (where they 0 out many weights) just have the sparse tensors be larger.
> The main reason topography emerges in physical brains is because spatially distant connections are physically difficult and expensive in biological systems.
The brain itself seems to have bottlenecks that aren't distance related, like hemispheres and the corpus callosum that are preserved over all placental mammals and other mammalian groups have something similar and still hemispheres. Maybe it's just an artifact of bilateral symmetry that is stuck in there from path dependence, or forcing a redundancy to make damage more recoverable, but maybe it has a big regularizing or alternatively specializing effect (regularization like dropout tends to force more distributed representations which seems kind of opposite to this work and other work like "Seeing is Believing: Brain-Inspired Modular Training for Mechanistic Interpretability," https://arxiv.org/abs/2305.08746 ).
> CNN will beat ViT on small data tasks, but that flips with enough scale because ViT imposes less inductive bias
any idea why this is the case? CNN have the bias that neighbouring pixels are somehow relevant - they are neighbours. ViTs have to re-learn this from scratch. So why do they end up doing better than CNN?
The motivation was to induce structure in the weights of neural nets and see if the functional organization that emerges aligns with that of the brain or not. Turns out, it does -- both for vision and language.
The gains in parameter efficiency was a surprise even to us when we first tried it out.
Indeed. What's cool is that we were able to localize literal "regions" in the GPTs which encoded toxic concepts related to racism, politics, etc. A similar video can be found here: https://toponets.github.io
My understanding coming from mechanistic interpretability is that models are typically (or always) in superposition, meaning that most or all neurons are forced to encode semantically unrelated concepts because there are more concepts than neurons in a typical LM. We train SAEs (where we apply L1 reg and a sparsity penalty to “encourage” the encoder output latents to yield sparse representations of the originating raw activations), to hopefully disentangle these features, or make them more monosemantic.This allows us to use the SAE as a sort of microscope to see what’s going on in the LM, and apply techniques like activation patching to localize features of interest, which sounds similar to what you’ve described. I’m curious what this work means for mech interp. Is this a novel alternative to mitigating polysemanticity? Or perhaps neurons are still encoding multiple features, but the features tend to have greater semantical overlap? Fascinating stuff!
Was it toxicity though as understood by the model, or just a cluster of concepts that you've chosen to label as toxic?
I.e., is this something that could (and therefore, will) be turned towards identifying toxic concepts as understood by the chinese or us government, or to identify (say) pro-union concepts so they can be down-weighted in a released model, etc?
We localized "toxic" neurons by contrasting the activations of each neuron for toxic v/s normal texts. It's a method inspired by old-school neuroscience.
I imagine it could be easier to make sense of the 'biological' patterns that way? like, having bottlenecks or spatially-related challenges might have to be simulated too, to make sense of the ingested 'biological' information.
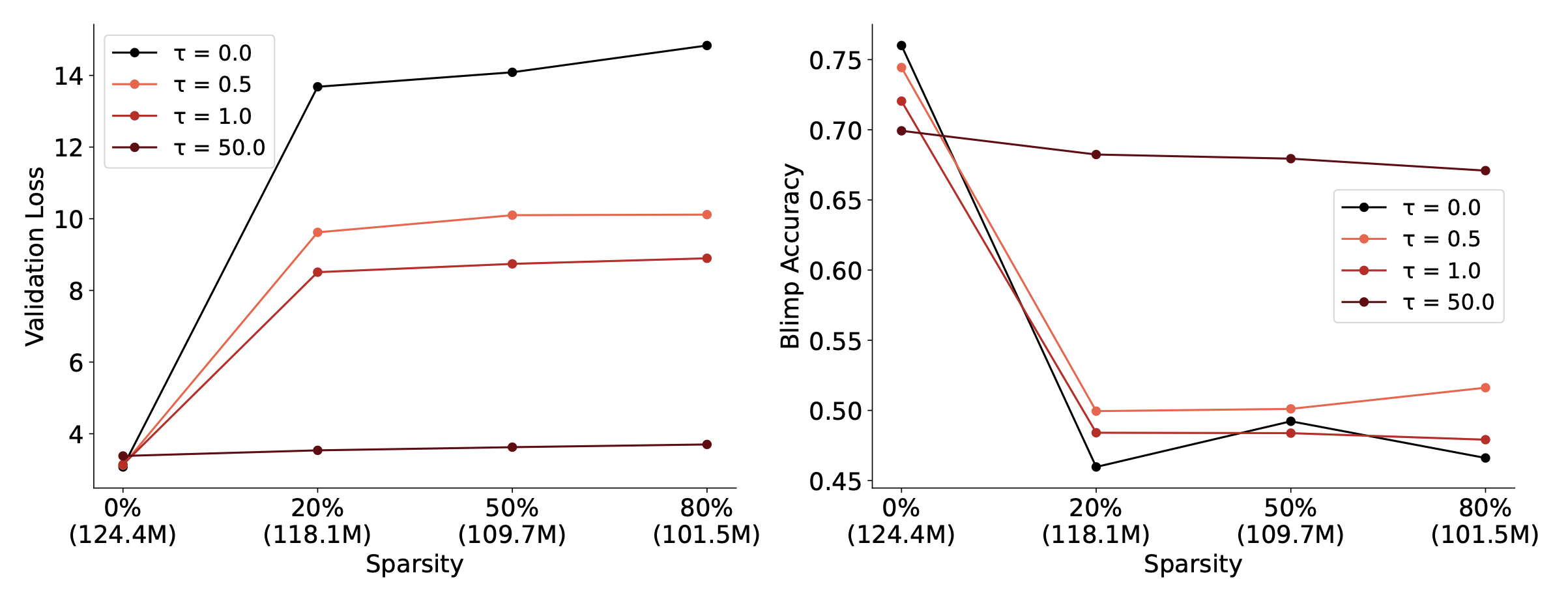
Yep. That is exactly the idea here. Our compression method is super duper naive. We literally keep every n-th weight column and discard the rest. Turns out that even after getting rid of 80% of the weight columns in this way, we were able to retain the same performance in a 125M GPT.
If you have things organized neatly together, you can also use pre-existing compression algorithms, like JPEG, to compress your data. That's what we're doing in Self-Organizing Gaussians [0]. There we take an unorganised (noisy) set of primitives that have 59 attributes and sort them into 59 2D grids which are locally smooth. Then we use off-the-shelf image formats to store the attributes. It's an incredibly effective compression scheme, and quite simple.
This paper imports an arbitrarily-chosen aspect of cortical architecture — topological maps of function — and ignores every other aspect of biological neural tissue. The resulting models show lower performance for the same number of parameters — not surprising, since they are more constrained compared with baseline. They may be slightly more robust against pruning — not surprising, since they are more regularised.
The figures show individual seeds, presumably, with no statistical analysis in the performance or pruning comparisons, so the null hypothesis is there is no difference between toponets and baseline. I would never let this paper be submitted by my team.
We haven't learned anything about the brain, or about ANNs.
If by popular fantasy you mean replicating the functional profiles of the visual and language cortex of the brain, then yes. These ideas in neuroscience are popular, but not fantasy. I encourage you to read up on functional organization in the brain, it's very fascinating.
> it’s not scientifically useful
Having structured weights in GPTs enables us to localize and control various concepts and study stuff like polysemanticity, superposition, etc. Other scientific directions include sparse inference (already proven to work) and better model editing. Turns out, topographic structure also helps these models better predict neural data, which is yet another direction we're exploring in computational neuroscience.
I love the paper - don't read into the negative comments. I find that a lot of online feedback (more so on Reddit and much less so on HN (usually)) tends to be opinionated and misinformed by quite a bit these days. Fantastic work and fantastic read.
I probably came in too hot on that (dealing with some personal stuff). Although I disagree with purported the impact of the paper, I don’t think this is fundamentally incorrect or bad science and I wish you the best on future research.
Submitted title was "Inducing brain-like structure in GPT's weights makes them parameter efficient". We've reverted it now in keeping with the site guidelines (https://news.ycombinator.com/newsguidelines.html).
Since the submitter appears to be one of the authors, maybe they can explain the connection between the two titles? (Or maybe they already have! I haven't read the entire thread)
I hate to dog on research papers. They’re work to write. That said, I think this paper is not likely to be of interest to AI researchers — instead it may be of interest to Neuroscience folks or other brain research types.
The lede — adding topography worsens networks at similar weights — is not only buried, it’s obscured with statements claiming that topo networks show less upheaval when scaled down, e.g. they are more efficient than similar weight networks.
It’s hard for me to see how both these things can be true — the graphs show the more topography is added, the worse the networks perform at the trained model sizes.
To have the second statement “They compress better and are therefore more efficient” also be true, I think you’d need to show a pretty remarkable claim, which is that while a model trained at the same scale as a llama architecture is worse, when you scale them both down, this model becomes not only better than the scaled down llama, but also better than a natively trained model at the new smaller scale.
There is no proof of this in the paper, and good reason to be skeptical of this idea based on the data presented.
That said, like a lot of ideas in AI, this .. works! You can train a model successfully imposing these outside structures on it, and that model doesn’t even suck very much. Which is a cool statement about complexity theory and the resilience of these architectures, in my opinion. But I don’t think it says much else about either the brain or underlying AI ‘truths’.
Indeed. The problem with most AI research today is they simply do trial and error with large amounts of compute. No room for taking inspiration from nature, which is requires more thought and less FLOPS.
1. Significantly lower dimensionality of internal representations
2. More interpretable (see: https://toponets.github.io)
> 7B model down to 6B
We remove ~80% of the parameters in topographic layers and retain the same performance in the model. The drop in parameter count is not significant because we did not experiment with applying TopoLoss in all of the layers of the model (did not align with the goal of the paper)
We are currently performing those strong sparsity experiments internally, and the results look very promising!
Our goal was never to optimize for performance. There's a long standing hypothesis that topographic structure in the human brain leads to metabolic efficiency. Thanks to topography in ANNs, we were able to test out this hypothesis in a computational setting.
> sketchy story this is "brain like".
we reproduce the hallmarks of functional organization seen in the visual and language cortex of the brain. I encourage you to read the paper before making such comments
I did read the paper. I really hope I don't get assigned to be a reviewer for it.
You don't reproduce anything about the functional organization of the visual or language cortex. You make a pretty picture with blobs in it. And one that's trivial to get from current methods. If you think "the functional organization of the visual or language system" means random blobs of activation/connectivity, well, then it's time for a class on neuroscience. I cannot imagine what neuroscientist would let this fly reviewing the paper.
The whole "we don't optimize for performance" is nonsense. Take any modern method that prunes weights and beats your approach with ease. Then smooth its output a bit to make nice blobs. The performance loss from smoothing will still beat your method and look "brain-like" by your definition. There you go. Your experiments don't show anything at all aside from the fact that a bad method performs poorly.
You didn't think through controls or alternative hypotheses. You didn't take into account a decade of research on methods to prune networks. You don't take seriously what we know about functional organization in the brain.
All sorts of bad papers make it through reviewing these days. But.. you can definitely do better. Good luck!
Is this "brain-like" in any functional way, or "brain-like" in the same way that a tall rectangle is "door-like" even if it doesn't share any functions with a door?
I know quite a bit about machine learning, but very little to nothing about neuroscience and human cognition, so I am curious how an expert (that didn't work on the paper) would describe it.
(Forgive me for the pre-emptive negativity but I am so utterly exhausted by dishonest comparisons to sapient thought in the field of artificial intelligence that it has nearly drained me of the incredible amount of enthusiasm I used to carry for it.)
It is indeed brain-like in a functional way. Topographic structure is what enables the brain to have low dimensionality and metabolic efficiency. We find that inducing such structure in neural nets made them have significantly lower dimensionality and also more parameter efficient (After training, we could take advantage of the structure to remove ~80% of the weights in topographic layers without sacrificing performance)
>After training, we could take advantage of the structure to remove ~80% of the weights in topographic layers without sacrificing performance
This is really interesting to me. Is it that the structure clustered the neurons in such a way that they didn't need to be weighted because their function were grouped by similar black box properties?
> Is it that the structure clustered the neurons in such a way that they didn't need to be weighted
Yep. Because of the structure, we did not have to compute the output of each weight column and simply copied the outputs of nearby weight columns whose outputs were computed.
{kind=link}
The key insight we discovered was that explicitly enforcing brain-like topographic organization (as some academic work attempts - such as this one here) isn't necessary - what matters is having the right functional components that parallel biological visual processing. Our experience showed that the key elements of biological visual processing - like hierarchical feature extraction and temporal integration - emerge naturally when you build architectures that have to solve real visual tasks.
The brain's organization serves its function, not the other way around. This was validated by the real-world performance of our synthetic visual cortex in the Tesla FSD stack.
Link to the 2021 Tesla AI day talk: https://www.youtube.com/live/j0z4FweCy4M?t=3010s