Normal SSDs have more throughput than Optane. Image reads, stats, logs, and checkpoints can all be done asynchronously, so I think a high end flash SSD could very likely perform better for you.
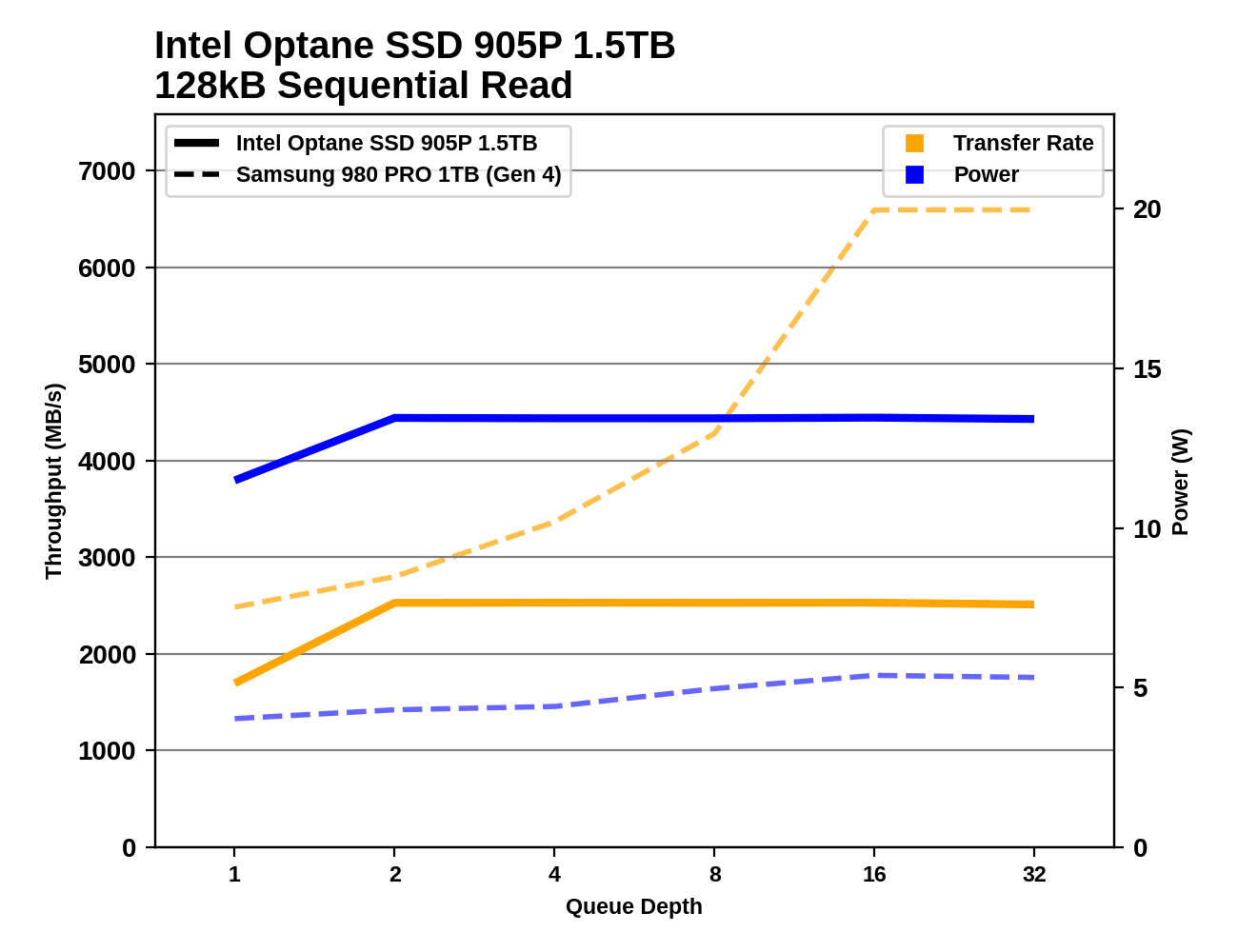
According to benchmarks [1] the older 905p destroys the best "normal" SSD (980 Pro) - it's more than 3 times faster in random reads. As I showed above, in the worst case I'm trying to get up to 2,000MB/s of random reads from my drive. How can you possibly believe a flash SSD can be a better drive for this use case?
Unfortunately I am stuck doing them one at a time, and every image is located in a different folder. At least that’s how the official Pytorch Imagenet dataloader is reading images for training.
You do make a good point though: my reads are not 4k, they closer to 256k on average, but still, they are random reads. I’m not sure how much faster those get with size.
And I’m pretty sure doing writes in parallel with those random reads makes things worse, but ok, let’s ignore that.
> At least that’s how the official Pytorch Imagenet dataloader is reading images for training.
Well, something to keep in mind if you want to optimize it later.
> still, they are random reads. I’m not sure how much faster those get with size.
The second image I linked should demonstrate that pretty well.
> And I’m pretty sure doing writes in parallel with those random reads makes things worse
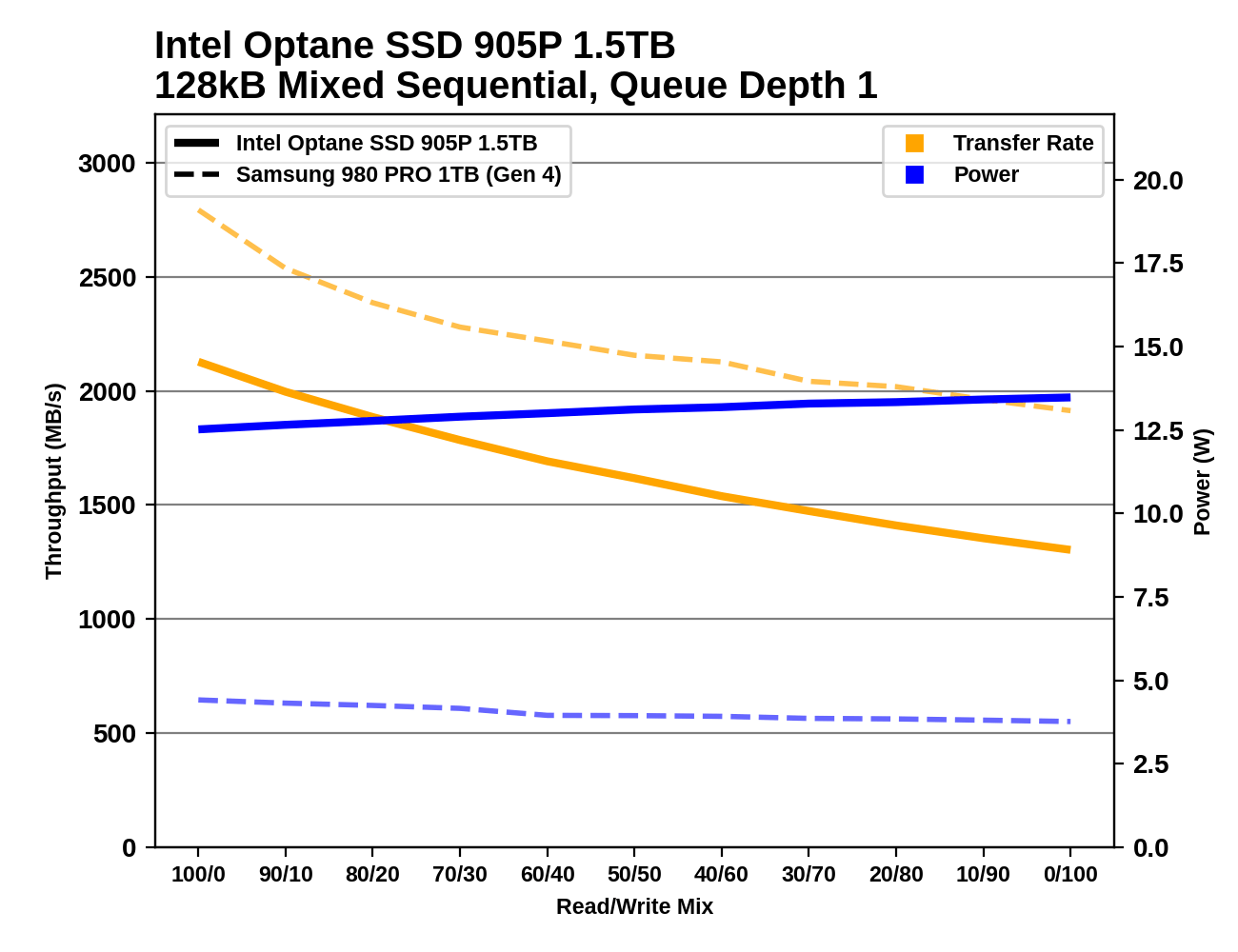
It looks like both models handle a mixed workload acceptably. Writing 128KB chunks is somewhat slower than reading, and mixing them gives you a speed somewhere in between. http://images.anandtech.com/doci/16087/sm-s-905p-1500.png
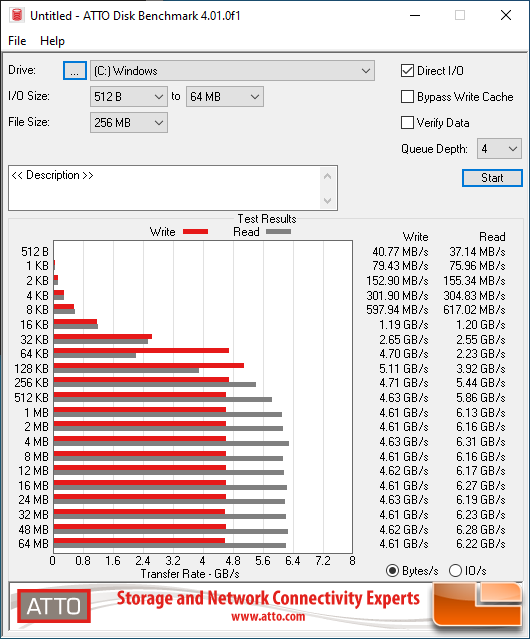
I'm not sure the second image directly answers my question though. It appears it shows a transfer of a 256MB file using different block sizes. Is this accurate? In my case, I'm transferring a 256KB file. And we want to know how much faster it is to transfer a 256KB file compared to transferring a 4KB file. Would it be the same as comparing how much faster it is to transfer a 256MB file than transferring a 4MB file on that plot? Because if so, there's no improvement shown. And it's clearly not the same as comparing the transfer of 256MB file using 256KB blocks vs 4KB blocks, because in both cases the block size is much smaller than the file size.
You should mostly ignore the 256MB number, that's just how big the testing arena is on the drive and barely affects the numbers.
The chart is showing how fast it is to load random chunks of data with different sizes. When you load image files, you're effectively loading random chunks of data. So if you want to figure out how fast this drive could load images for you, look at the line that best represents the size of your images.
> Would it be the same as comparing how much faster it is to transfer a 256MB file than transferring a 4MB file on that plot?
No, because the relationship is non-linear. If you want to compare 4KB and 256KB you have to look at the numbers for 4KB and 256KB. 256KB random reads are 15x faster than 4KB random reads.
The point is that when you initially linked the data for 4KB random reads, you were effectively worrying about how fast the drive would be at loading 4KB files. That number doesn't matter. You want to know how fast it is at loading 128KB or 256KB files. So look at a chart that's measuring random reads of the correct size.
If the question you want answered is the one implied by "still, they are random reads. I’m not sure how much faster those get with size.", then the answer is: That is literally the point of the ATTO chart. It shows how much faster random reads get with size. The relationship is a curve, so it's best to just look at the chart for your specific size. (And also keep in mind that this particular benchmark always had 4 IOs pending at once. And with real files, there will be a minor speed impact because they're not aligned as nicely.)
{kind=link}
{kind=link}
{kind=link}