Few notable things that I didn't realise with Modern SSD.
1. Extremely Power Efficient. They have come a long way with idle power and power management. Even on the Desktop where Energy efficiency isn't much of a concern. There used to be a time where SSD are 1W+ even when idling.
2. The amount of idle time, so these IO traces shown most of the time SSD isn't doing anything at all.
3. Read Latency are now extremely good. We are talking about sub 100us and sub 200us in 99th percentile. To the point Optane doesn't provide any meaningful differences in consumer usage. We will find out soon when Billy mentioned he will be testing Optane PX5800, I cant wait to see that. I should also note before someone jump in about Optane's Random Read Write advantage in QD1, I still dont believe it matters in consumer usage beyond the current NAND SSD performances.
I think with coming PCI-E 5.0 Drive we have a roadmap that has pretty much "solved" the performance category if we haven't already done so. What I want to see is slower, but large capacity SSD that is more affordable. But apart from some unforeseeable market condition, I dont see anything on the roadmap or forecast that could bring us 4TB SSD for sub $200 within the next 4 years. We seems to be entering the end of the S Curve where improvement ( cost reduction ) will be slower.
Regarding Optane and "consumer" usage: If you're talking about a typical PC usage, like browsing, using MS Office, and playing games, then sure, there's absolutely no perceptible difference between Optane and any other SSD, even a SATA SSD. But that's not what people buy Optane for, so it doesn't make much sense testing such an expensive drive on regular "consumer" PC tasks.
I train deep learning models, so I read random images from disk to feed data loader pipelines, and I also write back stats, logs, and model checkpoints. I frequently use 8 GPUs, each running a separate experiment, with its own data pipeline. This means every GPU is reading 1.2M jpg images in a random manner, every 30 minutes. I haven't actually tested if the disk reads are a bottleneck, but I'm guessing random reads of 20M images per hour would stress any drive, so I'd rather not risk it and get the best money can buy.
Normal SSDs have more throughput than Optane. Image reads, stats, logs, and checkpoints can all be done asynchronously, so I think a high end flash SSD could very likely perform better for you.
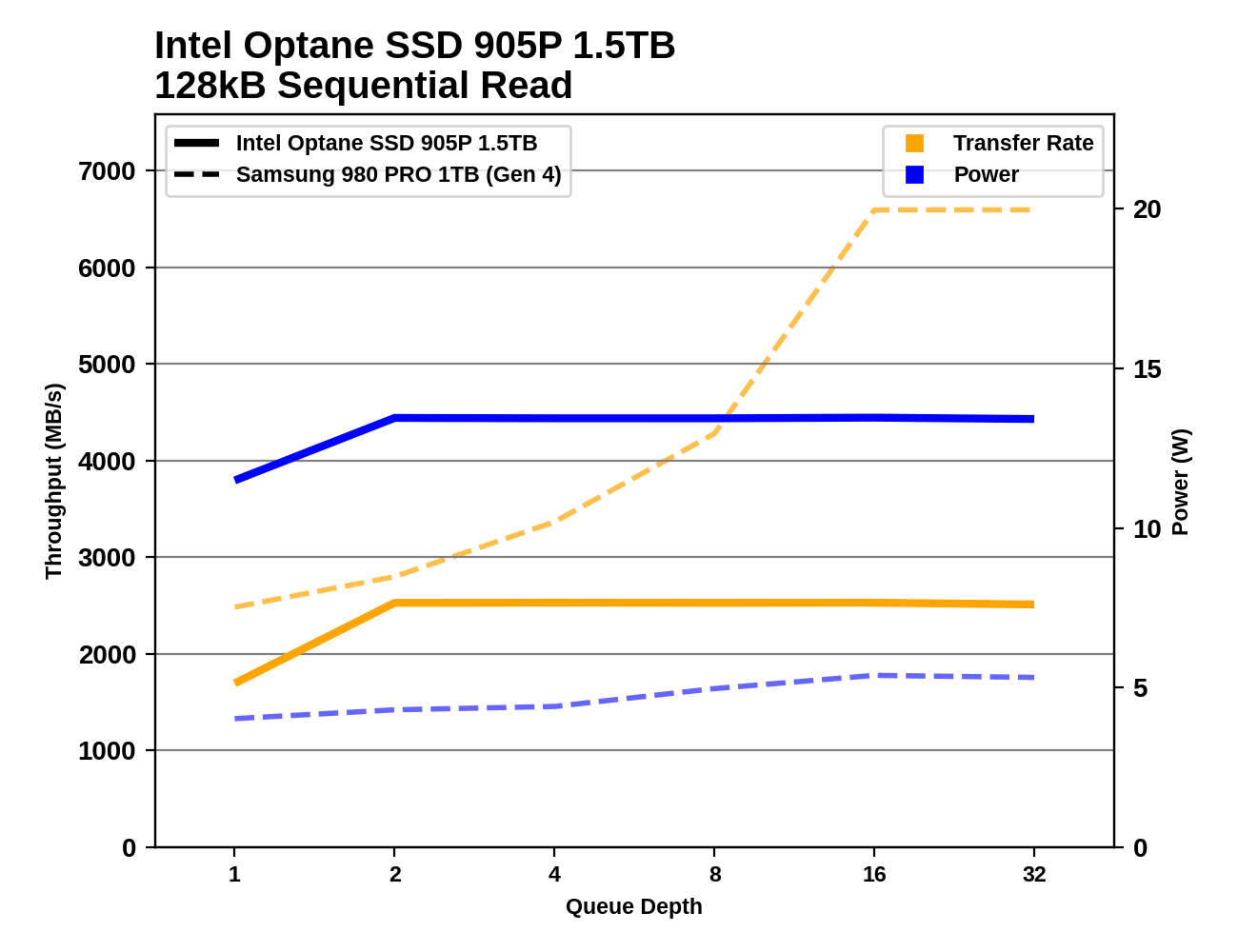
According to benchmarks [1] the older 905p destroys the best "normal" SSD (980 Pro) - it's more than 3 times faster in random reads. As I showed above, in the worst case I'm trying to get up to 2,000MB/s of random reads from my drive. How can you possibly believe a flash SSD can be a better drive for this use case?
Unfortunately I am stuck doing them one at a time, and every image is located in a different folder. At least that’s how the official Pytorch Imagenet dataloader is reading images for training.
You do make a good point though: my reads are not 4k, they closer to 256k on average, but still, they are random reads. I’m not sure how much faster those get with size.
And I’m pretty sure doing writes in parallel with those random reads makes things worse, but ok, let’s ignore that.
> At least that’s how the official Pytorch Imagenet dataloader is reading images for training.
Well, something to keep in mind if you want to optimize it later.
> still, they are random reads. I’m not sure how much faster those get with size.
The second image I linked should demonstrate that pretty well.
> And I’m pretty sure doing writes in parallel with those random reads makes things worse
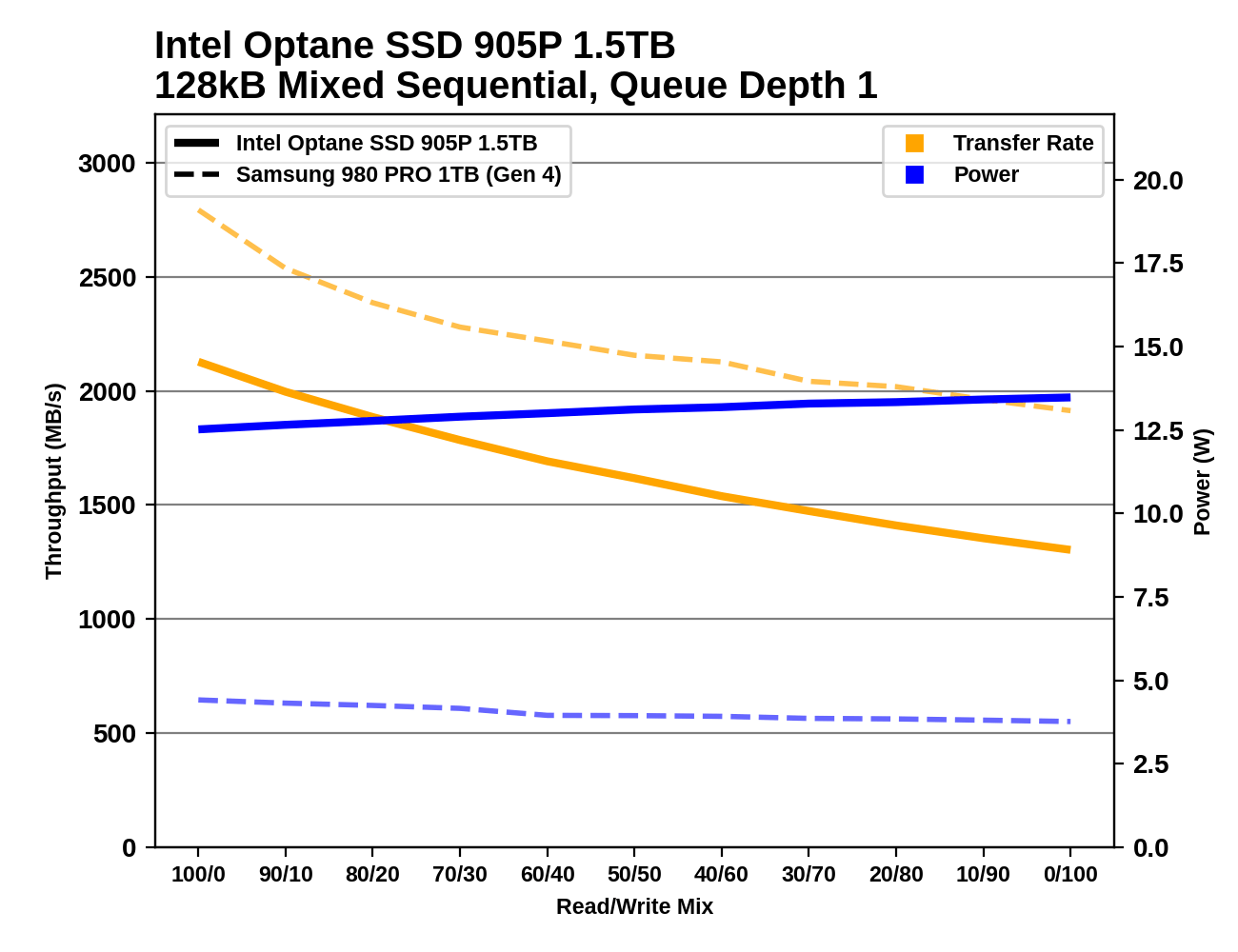
It looks like both models handle a mixed workload acceptably. Writing 128KB chunks is somewhat slower than reading, and mixing them gives you a speed somewhere in between. http://images.anandtech.com/doci/16087/sm-s-905p-1500.png
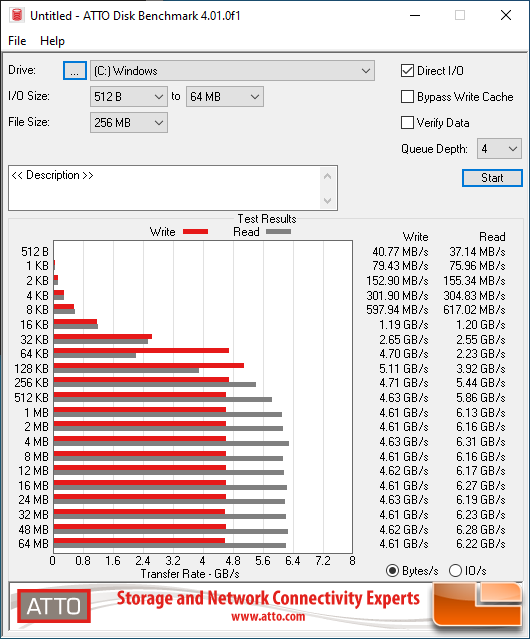
I'm not sure the second image directly answers my question though. It appears it shows a transfer of a 256MB file using different block sizes. Is this accurate? In my case, I'm transferring a 256KB file. And we want to know how much faster it is to transfer a 256KB file compared to transferring a 4KB file. Would it be the same as comparing how much faster it is to transfer a 256MB file than transferring a 4MB file on that plot? Because if so, there's no improvement shown. And it's clearly not the same as comparing the transfer of 256MB file using 256KB blocks vs 4KB blocks, because in both cases the block size is much smaller than the file size.
You should mostly ignore the 256MB number, that's just how big the testing arena is on the drive and barely affects the numbers.
The chart is showing how fast it is to load random chunks of data with different sizes. When you load image files, you're effectively loading random chunks of data. So if you want to figure out how fast this drive could load images for you, look at the line that best represents the size of your images.
> Would it be the same as comparing how much faster it is to transfer a 256MB file than transferring a 4MB file on that plot?
No, because the relationship is non-linear. If you want to compare 4KB and 256KB you have to look at the numbers for 4KB and 256KB. 256KB random reads are 15x faster than 4KB random reads.
The point is that when you initially linked the data for 4KB random reads, you were effectively worrying about how fast the drive would be at loading 4KB files. That number doesn't matter. You want to know how fast it is at loading 128KB or 256KB files. So look at a chart that's measuring random reads of the correct size.
If the question you want answered is the one implied by "still, they are random reads. I’m not sure how much faster those get with size.", then the answer is: That is literally the point of the ATTO chart. It shows how much faster random reads get with size. The relationship is a curve, so it's best to just look at the chart for your specific size. (And also keep in mind that this particular benchmark always had 4 IOs pending at once. And with real files, there will be a minor speed impact because they're not aligned as nicely.)
Just to clarify: Intel hasn't actually promised me a P5800X yet. But I think it's pretty likely they'll sample it for review eventually. For the P4800X, they initially offered us remote access to test in one of their servers, and later provided a server with a P4800X to keep as my new enterprise SSD testbed. Since I already have some decently powerful PCIe 4.0 machines, I'm not sure I want them to offer another rackmount server that would be too loud to make good use of in the home office.
I like notebookcheck's reviews as well. Very thorough, consistent over the years, everything is inttheir database and it's easy to make comparisons, they not only do objective measurements of brightness, noise, temperature and bunch of other things but also write down how they measured and with what. The only thing missing are confidence intervals
I recommend gamers nexus as well. It’s mainly YouTube content but they do very in-depth benchmarking and some innovative visualization on how uniform the cooling surfaces of a certain cooler are and things like that
gamers nexus is one of few very rare places where they actually dont do the manufacturer "recommended set of tests", aka dont buy marketing bullshit. They are run for the users, not for selling advertisement.
Absolutely. They are on fire lately, burning bridges with certain manufacturers who are now on my do not buy list. Won't name who here, best to leave his lawyers to deal with the flak, but it's definitely great to see those refusing to become sellouts!
Oh, thanks Anandtech indeed! Finally a proper test of PCIE4 NVMEs - I'm very happy with my choice of the 1TB 980 Pro now. I mean, I was always happy with it, but I've now got that validation one tends to seek, showing that it was a solid choice.
It is no surprise though, as my 980 Pro comes from a long series of Samsung drive purchases including 970 EVO 2TB (in same system) and others going back, having chosen Samsung after they did seriously good on some of the earlier SSD torture tests.
I left that one out of this initial batch because it's not really representative of anything on the market these days. But I am also curious to see how it scores, especially because it's one of the few recent consumer SSDs that doesn't rely on SLC caching.
Its not that simple, often thorough benchmarks will be the ones suggested by manufacturer, or even designed and written by manufacturer.
As it happens this is precisely Anandtech problem. They have a long legacy of printing whatever toiled paper manufacturers/vendors ship them https://news.ycombinator.com/item?id=22241800
>Intel tactic was manufacturing facts and positive press stories, something we now call fake news.
...
Intel version:
"At the time, I was working for Intel and was involved in the launch of the Pentium 3, aka Katmai.
We _engaged_ a number of games manufacturers to provide demos showcasing not only Screaming Sindy's Extensions, but the arcane and mysterious Katmai New Instructions.
One such outfit was Rage Software, now sadly deceased. Rage provided demos of Incoming and an early prototype of a game called Dispatched, which as far as I know never actually saw the light of day. Dispatched featured a strangely-arousing cat riding a jet powered motorcycle. The first version I saw was running on a 400MHz Katmai and was still in wireframe. It was bloody impressive."
Reality, according to hardware.fr:
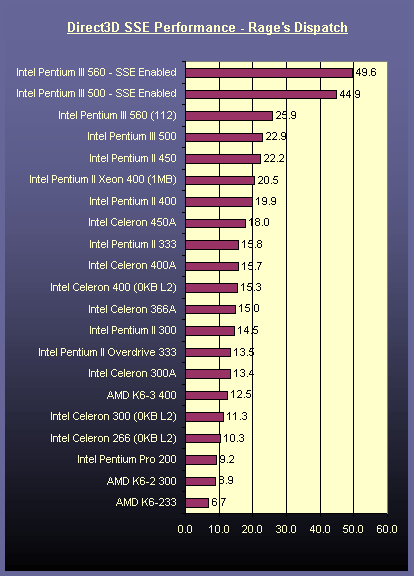
"Let's start with Dispatched first. This is actually a Rage Software game that should come out late 99, which Intel showed the demo at Comdex Fall to highlight the benefits of the SSE. Big interest, it is possible to enable or disable the use of SSE instructions at any time.
Nothing to say in terms of speed, it goes squarely faster once the SSE activated, + 50% to + 100% depending on the scenes! But looking closely at the demo, we notice - as you can see on the screenshots - that the _SSE version is less detailed_ than the non-SSE version (see the ground). Intel would you try to roll the journalists in the flour?"
SSE version is less detailed? How convenient! Rage Software Dispatched never came out. The only outfit, other than Intel, in possession of this software was Anandtech. They used this exclusive press access to pimp out Pentium 3 benchmarks manufacturing fiction like this https://images.anandtech.com/old/cpu/intel-pentium3/Image94....
>so it was pretty much an Intel commissioned demo piece to showcase P3 during Comdex Fall, and was cheating with details. Two other SSE patched games mentioned on hardware.fr actually ran slower with SSE
Anandtech used Intel commissioned piece of fake software to lie to its readers about SSE for couple of years during the time Intel was getting kicked by AMD and paying bribes to vendors.
>Update: As our readers were quick to pick up on from Intel's full press release, Intel is using faster LPDDR4X on their Ice Lake-U system. This is something that was not disclosed directly by Intel during their pre-Computex presentation.
Anandtech is perfectly happy to print Intel PR without trying to verify or make common sense assertions.
for anyone that has a very new motherboard/chipset with proper PCI-E 4.0 support, and wants to add a lot of NVME M.2 format storage (in addition to the on-motherboard M.2 slots), take a look at this:
Just curious for my own sake—is there a board out there with two electrically PCIe 4.0 x16 slots? I was under the impression that Ryzen Zen 3 has just 24 PCIe lanes, and usually four are split out for the chipset, so how could you run both your x16 video card and x16 M.2 carrier simultaneously without linking one at a lower rate?
Yes yes yes this you're absolutely right. Virtually every motherboards has two "x16" slots but only the first x16 is actually x16, one on the far side from CPU is electrically just x4 and is mutually exclusive with first M.2 slot. Unless you're building Threadripper/EPYC or Xeon HEDT/server. I didn't realize any of that and am enjoying free salt.
It's not quite that bad. Lots of motherboards connect the primary x16 to two slots, which can either be used as x16+empty or x8+x8. And x8 is quite a lot at 4.0 speeds.
The chipset's only fed by 4 lanes, so while it technically could be fully connected to a second x16 slot it would be kind of crazy for a motherboard maker to actually do that since the chipset only supplies 16 lanes total.
Realistically you need to give this card your main slot and your GPU can get an x4 connection and lose a few fps.
Fortunately, AMD seems willing to enable bifurcation on all their desktop platforms instead of using Intel's strategy of treating it as a product segmentation thing. Quad M.2 risers work in both my B550 and X570 system.
Artificial "product segmentation" is such nonsense. If you're able to put in the extra effort of disabling features that you just get for free otherwise, and make more profit by doing so that's just a sign that the market you're operating in is severely lacking in competition. It's good to finally see AMD giving Intel a run for their money.
Eh, it's like how non-K intel processors technically can be overclocked* in that less features can mean you get the same CPU but cheaper.
*: I know there are other reasons for non-K processors (binning might actually mean your non-K CPU can't overclock), but it's largely just a way to move more product and sell at a lower price point to those who can't afford unlocked or otherwise wouldn't have overclocked.
If Intel can disable a feature and sell something at a lower price, then they could also sell the same thing at that lowered price without the feature disabled. The only reason they don't is because they exist in a patent encumbered, (very) competition light environment.
(Binning because of imperfect production yields is different though and I don't have a problem with that. It's hard to tell how much of the K/non-K split is legitimate binning, and how much is just a bool in the microcode).
Didnt stop AMD from disabling PCI Express Resizable BAR support, hidden behind AMD marketing wank "smart access memory (TM)" name, on older "chipsets" despite both memory and PCIE controllers being build INTO THE CPU ....
I'm concerned about heat if that little fan goes. I know the storage throttles, but I would imagine 90C+ flash memory is not good for it's long term durability.
I'd like to see a complete fin heatsink that benefits from case flow.
I think the fan and enclosure are a bad idea personally, you'd achieve better cooling on the M.2 cards by leaving it off and having a case that has sufficient airflow front to rear in it. And possibly gluing your own small aluminum heatsinks onto the M.2 cards (which are cheap and easy to do), if they don't come with their own heatsinks.
It depends. Because NAND flash storage relies on electron tunneling, you actually need high temps for the mechanism to work well. Too much cooling and you'd be increasing the wear levels prematurely.
Not sure if this thing is smart enough to know when to kick the fans on and when to keep the temps "high". That is something worth noting though.
There was even technology announced for self healing NAND flash - drives that could cook itself to 800C to heal worn out cells. Never materialized tho :(
I found this here that says lower temperatures are better for storage but higher temperatures are better for writes. I'm not sure how accurate that all is though
Not really. Each card would only get 8 lanes. Then no more then two NVME drives will work in the storage card and that only if the board has bifurcation support.
Not sure why this is downvoted. Almost all (if not all?) consumer motherboards will drop the 2 x16 slots to x8 mode if you insert anything in the second slot. So using a PCIe riser for NVME SSDs means your GPU will get less bandwidth. This may or may not be noticeable, if you are running PCIe 4 the x8 will definitely not bottleneck the GPU, but x8 PICe 3 lanes probably will, especially for cards with less VRAM.
Part of my goal with this article was to take a fresh look at drives that had been through the old test suite, and be able to refer to the older results as a sanity check for the new results. (I found at least two bugs in FIO and one in Windows while working on this.) I have tested the SN850 on the new suite, but haven't written up a proper review yet: https://www.anandtech.com/bench/product/2732 I should also be getting an equivalent to the Sabrent Rocket 4 Plus soon.
Love it, thank you — the article already had my upvote! In particular SLC cache-aware tests and the inclusion of latency information (both average and 99th percentile) were both heartening to see. Too much crappy storage benchmarking these days.
Looking forward to seeing what you pick in terms of application benchmarks. I think application benchmarks help to keep us honest in terms of real-world impact of storage upgrades. LTT seeing if people could tell the difference between SATA and NVMe for games was great. I'm interested in database workloads, and the reason I was asking about the SN850 is that in Postgres benchmarks I've seen it has smoked the 980 Pro.
The original Corsair MP600 is equivalent to the Silicon Power US70 in the article, plus a heatsink: Phison E16 controller with TLC NAND. Corsair's newer MP600 PRO with the Phison E18 controller has been announced but isn't quite available yet.
It's been a while I bought a motherboard. Sata (6gb/sec?) was godsend at the time. Smaller cables and connectors and nicer to keep tidy. Pet peeve of mine to keep it looking nice especially with some stacked hard-drives in the bay. Back then it was pretty clear what you might do with the slots available.
Could someone fill me in with PCIe. What slots are available and are these mainly used now for graphics and SSD? SSD in slots is new to me which I haven't gotten around to yet.
PCIe slots come either from the CPU or the Chipset.
Typically, there are 16 lanes used per GPU and 4 per M.2 SSD.
With older CPUs, you had to either reduce the lanes assigned to the GPU to connect an SSD to the CPU, or go through the chipset.
With newer CPUs (newest intel or AMD Zen), the CPU provides 20 Lanes (16+4) for general use and in the case of AMD, 4 additional lanes for the chipset.
If you want more lanes connected directly to the CPU, you have to go to HEDT or Server Chips with up to 128 lanes available.
See this article for a typical block diagram of a AM4 system.
The block diagram helped! Great summary. Did some additional readings as I forgot all about PCH and came across south bridge / north bridge which were familiar sounding. As I understand, please correct me, summarizing parts what you wrote. So 16 lanes for GPU and the 4 (usually to PCH), which can be thought of as an extension? I'm not sure the right term but I guess this provides bus sharing through some mechanism so it does not affect the GPU lanes.
I recently got the Asus Hyper and 4 Sabrent Rocket NVMe disks and had them in RAID0. The speeds were just stunning to say the least at 15GB/s. Getting the drivers to work for the boot drive on Windows 10 was a pain though. AMD's RaidXpert requires you to do manually install the drivers in a specific order while installing Windows to recognize it.
> The speeds were just stunning to say the least at 15GB/s.
That is amazing. That is around DDR4-1866 speeds, and not far from DDR4-2666 (~21 GB/s). At those speeds I would happily work with dataframes sitting on the disk rather than in memory [1, 2]. Did you benchmark RAID 0 with less than four disks?
You're welcome to try, but remember that getting any specific piece of data takes a thousand times longer. Some workloads can handle that, and some can't.
I threw these on a PCIe 2.0 x16 port, and I get 3GB/s, as expected. There isn't anything in between 500MB/s SATA 3 SSDs and multi-gigabyte high capacity NVMe SSDs.
I'm blown away, so what are you all using the even greater throughput for?
The utility is quite slim as is, because of the networking limitations and other I/O. Only certain internal processing and parsing can take advantage of this.
Right now, very few programs take advantage of the speed. Things are just mildly smoother. But soon you should see lots of videogames that can dynamically load massive amounts of data, letting you switch levels in a second or have highly detailed levels that don't need to worry about fitting into memory all at once. (Presumably the latter will be optional for most titles.)
I wish some of these tests tested the performance of durable writes (via FUA writes or cache flush). Some otherwise fast drives are just ridiculously slow for those.
The PCMark 10 Storage tests do include some cache flushes in their traces. I haven't started extracting and graphing those stats, so I don't know if it's enough to say anything meaningful about how a drive would perform on sync-heavy workloads like a database.
Maybe someone can accurately give me a good guesstimate here. With the new direct memory access to GPUs (like RDMA) is there a big advantage to using PCIe 4.0 storage systems? I saw on a LTT episode that for the most part gamers didn't notice a difference using PCIe 4.0 (though RDMA wasn't out yet) but I'm wondering if there will be a bigger performance boost to more computational workloads.
tldr: if I'm buying a new machine doing a lot of GPU work, do I get a PCIe 4.0 storage system or 3.0?
For existing software, there is little to no difference.
Both Sony and Microsoft are talking big about the storage subsystems of their new consoles, and how it's going to enable entirely new things, such as low-latency direct requests to the flash from the GPU. for gaming in the future. This is likely to spill into the PC ecosystem during this console generation, both for games and gpu compute.
Personally, I would not purchase a motherboard that didn't support PCIe 4.0 anymore, but I would not worry about getting the fastest possible drive to plug into it. The idea behind this being that I am almost certainly going to expand/replace the drive before it matters, but I'm quite likely to still be using the motherboard at that time.
In my experience, on most SSDs/NVMEs, the firmware GC destroys performance under a heavy read/write load to the point of being no better than a mechanical HD of yore. Except Samsung and Intel. But Intel SSDs have bricked on me a lot. So now I just use Samsung NVMEs exclusively.
The version of explanation I have read is that it's SLC cache getting saturated(same deal as CMR cache region in DM-SMR except read/write can parallelize), and that it won't happen with enough cache amount and fast, parallel writes, so explanation differs but solution sounds right
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Extremely Power Efficient. They have come a long way with idle power and power management. Even on the Desktop where Energy efficiency isn't much of a concern. There used to be a time where SSD are 1W+ even when idling.
2. The amount of idle time, so these IO traces shown most of the time SSD isn't doing anything at all.
3. Read Latency are now extremely good. We are talking about sub 100us and sub 200us in 99th percentile. To the point Optane doesn't provide any meaningful differences in consumer usage. We will find out soon when Billy mentioned he will be testing Optane PX5800, I cant wait to see that. I should also note before someone jump in about Optane's Random Read Write advantage in QD1, I still dont believe it matters in consumer usage beyond the current NAND SSD performances.
I think with coming PCI-E 5.0 Drive we have a roadmap that has pretty much "solved" the performance category if we haven't already done so. What I want to see is slower, but large capacity SSD that is more affordable. But apart from some unforeseeable market condition, I dont see anything on the roadmap or forecast that could bring us 4TB SSD for sub $200 within the next 4 years. We seems to be entering the end of the S Curve where improvement ( cost reduction ) will be slower.