I use LLMs to answer certain questions, but those are often questions that I wouldn't have bothered using a search engine for in the past, rather I would have asked a colleague or just thought through the question on my own. And when I try to ask an LLM questions that search engines are good at, I'm most often disappointed.
In other words, it's not clear to me LLMs are going to eat into the market share of search engines, rather than just providing a tool with largely orthogonal use cases. But we'll see how the tech develops from here.
I strongly disagree. As a simple example, just this week I was looking for ice breaker questions for a work team event. I started with Google and was wading through a myriad of pages stuffed with ads and noise. I happened to have Claude open for an unrelated work experiment and thought to ask Claude for ice breaker questions. It provided 10 good questions and I selected the first two. It’s just a matter of time until we retrain our brains to first use LLMs before Google and then Google’s usage is going to drop like a rock. LLMs for many use cases is simply better, providing better results with far less noise.
That's pretty much the ideal use case for LLMs, as a tool for creative brainstorming where the question of accuracy is irrelevant. I've used them like that frequently for help in writing/worldbuilding.
But I think it's safe to say that the vast majority of Google searches are looking for factual information of some kind. I can see LLMs as an interface on top of search, but not replacing it.
As a person with reading comprehension skills, I'm still not sure what a use case is for LLMs for me. Everything I try feels like outsourcing a homework problem to a middle schooler.
There is so much more you can pick up by reading a text yourself, even quickly, than comes through when an LLM summarizes a text or answers a complicated question. The way the text is written, the language chosen, the punctuation, the sources chosen, etc.
"When asked to draw circles representing themselves and friends or family, for example, people tend to self-inflate their own circle but they self-inflate more in individualist cultures."
This sort of methodology sounds sketchy to me - how much can we really learn from this? Does it reproduce? If it does, how do we know there isn't some other cause?
While other methodological aspects may be more doubtful, in the paper of Talhelm of Dong there was no "ideographic vs alphabetic" problem.
That paper compared Chinese people with Chinese people, where both groups had been assigned randomly and forcibly by the communist authorities to become agricultural workers in wheat-cultivating regions or in rice-cultivating regions.
The only confounding factors could be other geographic differences besides their major crops.
The point of the paper was to exploit this unusual historical fact as a social experiment that has eliminated most confounding factors that exist in other comparisons, like the factor mentioned by you.
It does sound kinda sketchy, but the preceding sentence to your quote mentions it 'has been shown in earlier work' so presumably there are some studies somewhere showing the experiment, links and how much we can learn from it etc.
It still might have flaws, but it's not like they just got people to draw charts and interpreted it as 'collectivist' and 'individualist' for the first time in this study.
> ... Other kinds of errors are more characteristic of poor science. When I was at Cornell [1945–1950], I often talked to the people in the psychology department. One of the students told me she wanted to do an experiment that went something like this—I don’t remember it in detail, but it had been found by others that under certain circumstances, X, rats did something, A. She was curious as to whether, if she changed the circumstances to Y, they would still do, A. So her proposal was to do the experiment under circumstances Y and see if they still did A. I explained to her that it was necessary first to repeat in her laboratory the experiment of the other person—to do it under condition X to see if she could also get result A—and then change to Y and see if A changed. Then she would know that the real difference was the thing she thought she had under control. She was very delighted with this new idea, and went to her professor. And his reply was, no, you cannot do that, because the experiment has already been done and you would be wasting time. This was in about 1935 or so, and it seems to have been the general policy then to not try to repeat psychological experiments, but only to change the conditions and see what happens.
It is not so anymore, psychologists are taught to design experiments showing that changes in an independent variable correlate with a dependent variable. I'm not sure when the change came, but I'd guess that in 1970s it was so already.
*taps finger to forehead* You can't have a replication crisis if every paper is a new thing without retesting old conclusions. :p
From my brain's obsessive make-a-fun-analogy circuit:
1. Our research shows we can count umbrellas in aerial photos to predict future rainfall. This Predictive Aggregate Umbral Coverage will revolutionize climatology!
2. Our new research using PAUC [1] shows the country of Elbonia will become a desert in a decade.
Their first paper on rice theory was cited like 2000 times, so you can check if anybody debunked this theory. I haven't.
I was also surprised to see that this theory has been published in reputable journals (like Science and Nature Communications). So, odds are that critics haven't made strong arguments on this theory so far.
The average income of FT readers is £221k [0] and the average income of WSJ readers is $234k [1]. I'm guessing the average reader of most online only newspapers is closer to the US median of $74k [2]. These readers belong to different economic classes with different financial interests, so the agenda divide is not surprising!
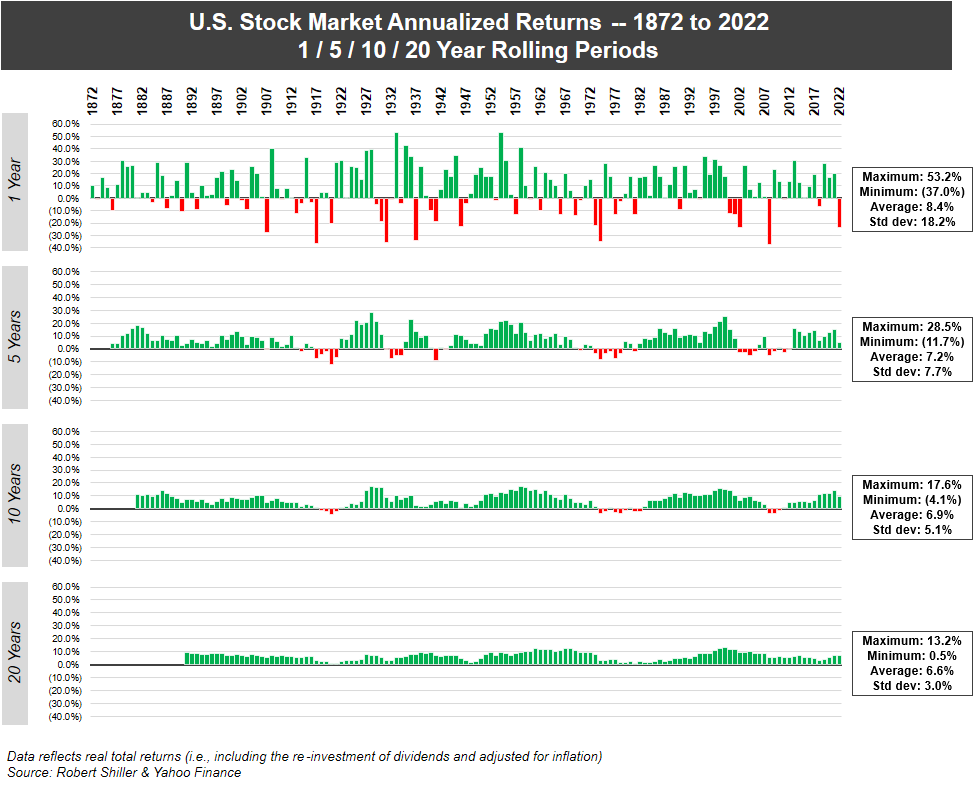
The geometric mean (6.9) is all that really matters for investors, not the arithmetic mean (8.4) - the arithmetic mean under-weights the importance of negative years to long term performance.
For example, if the market is down 20% one year and up 20% the next year, the arithmetic mean will be 0%, but you'll be down 4% (0.8*1.2 = 0.96), which is reflected in the geometric mean of (about) -2%.
Depends, dollar cost averaging shifts things around. For a typical 401k style investor having down years mid career improves returns at retirement, but then increases risks in retirement.
The “average” investor gets paid cash and not in stock.
The public tech company employee has less to invest because a large portion of their income is in stock.
The private tech company employee is screwed because statistically, they have equity that won’t amount to shit in a bull market let alone a bear market.
The "average" investor is in jobs less hit by typical recession/down market impacts, since the odds of a hospitality worker or barista having a retirement account in the first place is much lower than the odds of a white collar employee.
The point of comparison would be average reduction in investment vs average reduction in stock price. It’s true people invest less, but stocks take much larger drops than the reduction in the workforce.
Are you arguing that the stock market is not correlated with unemployment? That’s a weird and plain stupid hill to die on because anybody can disprove it with 3 seconds of googling.
It might be a stupid hill to die on that general statement, but currently we have a falling stock market with very little unemployment which is part of the reason for the inflation.
> An inverse relationship between level of unemployment and forward stock market returns. In the current quintile (2.5% to 4.4% unemployment), the average S&P 500 return over the following year is 5.6% versus and average of 12.7% in all periods. The best returns historically have come after periods of high unemployment
Maybe you should use a source that is at least self consistent?
Inverse relationship between unemployment and returns - proceeds to show a table where the lowest quintiles of unemployment have the lowest returns. That doesn’t seem very inverse to me.
In any case even if you don’t use some trash site that can’t get a basic editor/proofreader and correct that error, it’s not counter to anything already told to you by me and others.
You both make valid points. The JPMorgan memo's point is that a view on the economy is insufficient for reaching a view on the market. If we're heading into a recession, that doesn't necessarily mean stocks will fall. If we've rounded the bottom, it doesn't mean stocks will rise. More pointedly, it's asking its clients not to sell even while it predicts a recession.
The Seeking Alpha piece doesn't support your argument. Returns one year post peak unemployment are good because valuations at peak unemployment are in their trough. The correlation drives the effect. The article could be summed up as buy when the market is low / unemployment is high.
There is a real effect that comes from the stock market being forward looking and the labor market backwards [1]. When unemployment goes up, markets go down, and that's a problem for forced sellers.
> An inverse relationship between level of unemployment and forward stock market returns. In the current quintile (2.5% to 4.4% unemployment), the average S&P 500 return over the following year is 5.6% versus and average of 12.7% in all periods. The best returns historically have come after periods of high unemployment
Of course they don’t, that’s not what your articles say. Did you read them? They, respectively, say that the market is forward-looking and that major gains are made after downturns.
It can simultaneously be true that major gains are made after downturns and that there has historically been a strong correlation between downturns and unemployment.
And even these days the typical investor probably uses a financial advisor, who would do such fund reallocation, even if they don't use target date funds explicitly (which they should).
Do they really? When I've looked around at financial advisors they've wanted at least several percent annually of AUM, which, to my mind, is just insane.
For this hypothetical, I don't think it makes sense to consider anything but a typical 401k investor that only invests in the sp500. Thats all that we're tracking here.
When spending down money you get the reverse of cost dollar averaging. In a good year you might sell say 1,000 shares but in a down year you might need to sell twice that to take out the same money. This means more of your shares are sold in down years than good years.
This is why people say to increase the bond ratio in retirement, but that also reduces expected returns.
I'll just share this. I've recorded every retirement contribution and date since I started saving for retirement back in the late 90's. From that, I can figure APY at any time by comparing to my balance.
I had some learning experiences early on but never totally lost my shirt. I went through the dotcom crash, the finsys crash, and the more recent stuff. And I've been following Bogle philosophy for a very long time, of an allocation model with a percentage in US stocks, intl stocks, bonds, and cash.
I would love to have 3.5% real over that time period.
Now, it's possible I'm the world's lousiest investor, but I don't think so. Because I did a similar exercise pretending "what if I had just bought S&P500 on those dates?" and looked at dividend-adjusted-close. And the results there were also nowhere near as high as you'd expect.
People just can't equate "stock market performance" with what their own performance will be. You might get laid off when economy is bad and markets are down. You might have more money to invest at the top of the market, and less at the bottom, which totally screws up dollar-cost-averaging. You won't be entirely in the stock market, keeping some in bonds in cash. Your "well, I'm getting old so I should keep less in the market" decision might align with the beginning of one of the most irrational bull markets in history. (All of the above have been true for me.)
I think the only real answers are just to save like crazy, keep expenses low, and push for a better social safety net. My own retirement projections assume Social Security will only pay out at 74%, and I'm feeling the need to have a big buffer due to economic/political uncertainty, which really sucks.
I have been a Betterment customer since 2014 - robo-advisor-driven portfolio since the start of my retirement journey.
Been 90% stocks/10% bonds the whole time, though the underlying basket has shifted a few times as I made decisions about how to skew the basket using Betterment's portfolio options.
8 years on, I have a total annualized return of 4.9%, with Betterment saying "All performance figures displayed reflect the actual performance of your account since its creation in terms of total time-weighted returns, net of Betterment's management fee, fund fees, and certain other fees, if applicable."
The most volatile part of my retirement journey has been how much money I am able to contribute in a given month; some of these years I've had the job security and consistent income to dollar cost average the whole year's worth of contributions every 2 weeks or every month; other years I've had to wait until some amount of money became available to do a more "lump sum" contribution.
Thank you for your comment as far as it can at least help me set expectations for how I might see this performance number continue to go up and down over time!
First, please repeat the standard mantra: past performance is no guarantee of future success.
Then tell me the 95th percentile and the median geometric returns based of fixed periods (say, copy the 20 years.)
Let us also grab what an inflation linked gov bond would have given over those same periods. Classically I would always think of pension returns as vs the risk free rate (heh, us gov credit risk) which is essentially an IL bond.
Then repeat the analysis on, say, the G8 or G20 countries. Oh, and lets do a variety of stock indexes as well. I am a great believer in diversification - so betting on the US is not my standard behaviour.
6.9% assumed return is mad for any individual. It would be mad for a DB scheme _and they at least have some risk pooling in their favour_.
But. I am hella risk averse and see the world through that lens.
Yep, long-term I'm okay at 3%, comfortable at 3.5%, happy at 4% and awesome anywhere above 4.5%. I find the benefit of going with a conservative plan is stress reduction during downturns.
Maxmizing log returns is very good in many respects. It has nice mathematical properties. It's not too far off from what people subjectively value. But it is an approximation. For instance, how upset would you be if you woke up to find your bank account was $0? Pretty upset I'm sure. Infinitely? Doubt it. Now some one gives you a single cent out of pity. Feeling a lot better? Hardly.
The subjective satisfaction we get from a certain amount of money is something that would take a lot of experimental science to figure out, and subject to change as society changes. How high up Maslows hierarchy of needs can you climb, and how long can you stay there until age brings you low?
Now where log returns really shine is if you make a very large number of similar bets. Thats where the asymptotic behavior dominates. But if you make a big once in a lifetime decision of whether to bet the farm on a new business idea, that's where you have to figure out your own values.
That's the thing. The Sharpe Ratio looks at a catastrophic situation and says it's ok. It's not appropriately scoring risk!
Let's say the risk-free rate of return is 3%.
Asset 1:
Every year, with 99% probability you get 8% return, and with 1% probability you get -100% return, i.e., you lose everything. This has an expected return of 7%, which is 4% above risk-free; the standard deviation is 0.1; and the Sharpe Ratio is 0.36. But the exponential of the mean log annual multiplier is zero; you will eventually lose everything.
Asset 2:
With 90% probability you get the risk-free rate of 3%, and with 10% probability, you get a 10,000% return (multiply balance by 101). Yes, this has a good average return of 1,000%, but it also has a giant standard deviation of 30, so its Sharpe Ratio is slightly worse, at 0.33. But, the exponential of the mean log multiplier is 1.62, which means that over time it will have a 62% annual return. Moreover, it literally never goes down; there's no risk.
Asset 3:
You just take the "risk free rate of return" at 3%.
Surely, the best choice is Asset 2. It's literally Asset 3 plus free lottery tickets. But it has the worst Sharpe Ratio of the three. And Asset 1, which has the flavor of some prudent tradeoff, is actually guaranteed to bankrupt you eventually.
> But maximizing log-return was proven by Kelly to be optimal, and you don't need to further penalize volatility.
This is what I'm questioning. We do need to further penalize volatility, if that is our preference.
The criteria is optimal in the sense of greatest expected return, in the limit of infinite number of bets. But we don't make infinite numbers of bets, and the variance matters.
Any truly optimal strategy has to factor in subjective preferences.
Example: We play a game where you are ill and need to pay for medical treatment. At the beginning of the game you obtain a sum of money exactly enough to pay for the treatment. Then you are allowed to place (a finite number of) bets in some gambling, possibly increasing your payoff, or losing part of it. I'd argue that in this scenario the "optimal" strategy is not playing, no matter what criteria is used to select the size of the bets.
It would make sense to allow a risk-averse utility function in our framework (say a concave function of total dollars at the end).
I don't think the identification "volatility" = "standard deviation" = "risk" matches anyone's actual preferences. So that part doesn't make sense to me.
But I like your example with the medical treatment. That could be modeled with a step utility function. Mixing it with my example, there'd be no problem choosing my Asset 2 or 3, since both guarantee that your capital will be preserved so you can pay for your treatment. If your utility function were truly a step, you'd be indifferent between Assets 2 and 3. More realistically, you'd assign minus infinity to values beneath the threshold and some monotonic function to values above (e.g. just the number of dollars), and you'd prefer Asset 2: It guarantees your medical treatment, which is what you really care about, but it throws in a free lottery ticket, so why not take that.
1. Im not sure that’s what the Kelly criterion is but I didn’t look it up.
2. Arithmetic mean of log returns is the same as the geometric mean of returns. Indeed it’s pretty typical to work with log returns for this reason as adding is easier/better for computers than multiplying. This equivalence is easy to prove:
Yeah, I should have been more clear. The point is that you can convert between them without needing any other information (like the original values that were averaged)
I want to believe this. Do you have any citations?
My experience would suggest shipping higher quality software is a lot cheaper in the long run, but has up-front costs that often times startups can't afford.
You can afford them if you don't have project managers or sales guys begging for their demoable results of new shiny thing and promising it to others too early and too often.
My companies first 5 hires were junior developers. This cost a fair packets (because there were 5 of them!) and led to pretty low quality software (because they were all junior and didn't know what they were doing).
They could have shipped higher quality software quicker by hiring 2 senior developers for similar cost.
Startups bias toward hiring some less experienced developers by their nature, so they don't always know how to build quickly and solidly. The up front cost is either learning skills of abstraction from scratch, or hiring people who have.
With mastery learning, it's the feedback loop that's making the difference. In some domains where the subject matter itself can be computationally modeled (such as math), it seems plausible that the feedback loop as well can be emulated by software. There have been many attempts and many failures to do so, but I'm optimistic and believe it's a matter of further investment and research.
The cost of nuclear energy has been flat for decades, but the cost of sources like solar has been plummeting. Nuclear doesn't have much of change without some technological break through.
Same for nuclear though, a steady source of power is not a good fit for our energy use. You have to start building thermal or battery storage, or do specialized more-expensive designs that can operate at variable power, or get customers to shift their load.
Exactly my point. Repeating first line of my comment above for added effect:
"Nuclear and renewables are not 1:1 match or comparison.
Different energy sources for different requirements. You want a good mix, not bad mix. Things like periodical negative electricity prices (in Europe) increase the net cost of energy. Excessively high night-time electricity is also harmful (industries, and many other uses require 24/7 energy).
Important to define the "peak" part of "off-peak" here. Is it peak production, peak differential between supply demand, etc.
Mid-day is off-peak for solar in many markets, and they curtail their output so that they don't oversupply. As there is more solar built, more and more will be curtailed.
Both nuclear and solar would need a hydrolysis system that was economical even if not run 24x7 in order to utilize their supply-demand mismatches. This is the biggest road block to hydrogen production with the GWh of "free" electricity that we could currently be generating in the spring in California, but currently just don't use.
As I mentioned in another comment, Ontario could stand to build another 2500-3000MW with of nuclear to deal with the base load, and the variable demand could then largely be dealt with using hydro-electric.
Looking at Ontario's numbers, I see no way in getting 11,000MW of renewal power to replace nuclear connected to the grid, regardless of how many interconnects are set up to other jurisdictions (especially the population is concentrated in the south, and so there's be a high concentration of connections).
Ontario has quite a few turbine farms itself, spread over a reasonable wide area, and even then variability is high:
As other people mentioned here, it looks like the problem now is that the experience of building nuclear reactors was lost, so we are in a Catch-22 situation right now: if you want to build experience you need to just build reactors, but they are not economically viable without experienced builders.
The problem is that all current reactors are of the 1 GW size. For the last few decades the world has been building about 1 or 2 per year outside of China.
The solution is small nuclear reactors. For very large machines there is a dis-economy of scales. It was more expensive to build a Saturn V rocket than to build 20 rockets that are 20 times smaller each. In fact it was 3 times more expensive (about $180MM/ launch for Saturn V vs $3MM for Titan II)
Similarly, it's quite likely that it will be much cheaper to build 20 reactors of 50 MW each than it is to build a 1 GW reactor. And this is exactly what small nuclear reactors hope to achieve. For example NuScale estimates it will cost them $3 BN to build a 600 MW power plant [1] using small modular reactors.
Isn't that basically the whole point of the recent ITER news? Swapping from fission to fusion and getting a 10x gain power in to out? I know it's been slow going and still will be, but it's still progress
Solar is barely able to be used 30% of the time, and wind maybe touches 40% reliability. Meanwhile nuclear hardly ever drops below 80%, and is usually above 90%.
I live in Ontario, Canada, and we have quite a few nuclear plants, and they deliver very reliable power (click on the "Supply" tab):
IMHO, if we build another ~2500MW of nuclear, then that would completely take care of our base load, and the daily fluctuations could be handled by hydro.
This shows that wealthier people are moving to California, while middle and lower income people are leaving (People with an income lower than 110k a year).
{kind=link}
In other words, it's not clear to me LLMs are going to eat into the market share of search engines, rather than just providing a tool with largely orthogonal use cases. But we'll see how the tech develops from here.