I have no idea what you're talking about and am waiting for an answer to OPs question. Downloading text-generation-webui takes a minute, let's you use any model and get going. I don't really understand what this Nvidia thing adds? It seems even more complicated than the open source offerings.
I don't really care how many installs it gets, does it do anything differently or better?
> Downloading text-generation-webui takes a minute, let's you use any model and get going.
What you're missing here is you're already in this area deep enough to know what ooogoababagababa text-generation-webui is. Let's back out to the "average Windows desktop user who knows they have an Nvidia card" level. Assuming they even know how to find it:
2) See a bunch of instructions opening a terminal window and running random batch/powershell scripts. Powershell, etc will likely prompt you with a scary warning. Then you start wondering who ooobabagagagaba is...
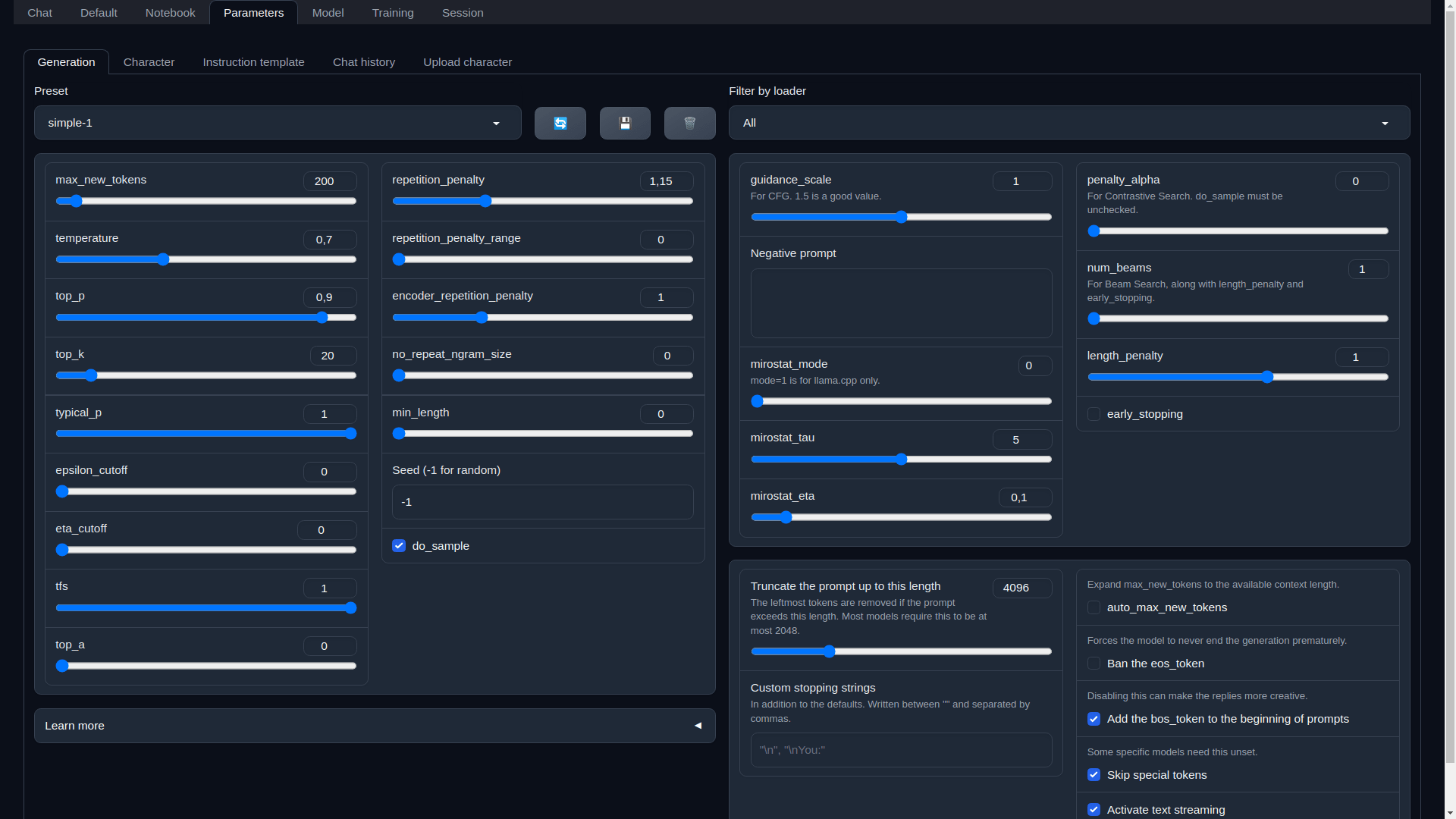
3) Assuming you get this far (many users won't even get to step 1) you're greeted with a web interface[0] FILLED to the brim with technical jargon and extremely overwhelming options just to get a model loaded, which is another mind warp because you get to try to select between a bunch of random models with no clear meaning and non-sensical/joke sounding names from someone called "TheBloke". Ok... Oh yeah, what's a "model"? GGUF? GPTQ? AWQ? Exllama? Prompt format? Transformers? Tokens? Temperature? Repeat for dozens of things you're familiar with but are meaningless to them.
Let's say you somehow braved this gauntlet and get this far now you get to chat with it. Ok, what about my local documents? text-generation-webui itself has nothing for that. Repeat this process over the 10 random open source projects from a bunch of names you've never heard of in an attempt to accomplish that.
This is "I saw this thing from Nvidia explode all over media, twitter, youtube, etc. I downloaded it from Nvidia, double-clicked, pointed it at a folder with documents, and it works".
It's a different inference engine with different capabilities. It should be a lot faster on Nvidia cards. I don't have comp benchmarks for llama.cpp but if you find some compare them to this.
Disingenuous to what? I'm asking what it brings someone who can already use an open source solution. I feel like you're just trying to argue for the sake of it.
{kind=link}
I don't really care how many installs it gets, does it do anything differently or better?