Structured logging is my jam. Our unit tests validate error content, errors have all dynamic text in different fields, provide all info to reproduce (including, where appropriate, copy-pastable curl commands to replicate an error to remote api endpoints!) and log aggregators like Splunk can group and aggregate and find relationships.
If I see a spike in errors, I can, in real time, count them by user id, group by region, filter out by some other field, then have the table of events generate a live line chart easily showing the error rates over time, and pin pointing the exact moment an error started.
Less than five to ten minutes after detection or report and I can be talking with another team about a change they released at time $x, including a list of affected users for product teams to reach out to if needed.
SendGrid, so billions of incoming requests that multiplex out to at a minimum 8 other log events, plus all errors, etc. We have to run our own splunk instances. We used to store data for a much longer time but as our scale keeps going up so do the costs. We've had to reduce this to a 7 day lookback for higher volume services. For lower volume (in the millions not billions), 30 days to a year lookback depending.
As for blog posts - I'm not aware of any. I've actually wanted to show off what we have but have never prioritized the blog post.
For compressed logs, it doesn’t have to be significant. If you can get structured logs into a TSDB you really only need to retain logs in cold storage or for as long as more detailed views or correlation might be necessary.
Depends on what you are doing. We mask auth stuff and some known params like an auth header might log as "authorization: bearer $APIKEY". Some things can't be logged. But as a general rule, it is an immense time saver.
1. Apache has a perfectly coherent and structured view of the situation: Host 1.2.3.4 made a GET request of this particular URL, with this particular UA, at this particular date.
2. Apache proceeds to shove all this into a string, destroying the structure, and probably some of the data (it likely knows the timestamp with >1s precision)
3. Then to do some sort of analysis we need to manually reverse this process: write some convoluted regex to match this kind of line, turn an IP address back into a number, turn a timestamp into a number, find the delimiters. We're now undoing the damage Apache did. Why!?
4. For extra fun this adds extra problems to deal with log rotation, log compression, newlines and special characters in fields, and so on. All kinds of problems that are ultimately unproductive to solve and get in the way of actual useful work.
Logging should be structured by nature. I shouldn't be writing weird regexps. I should have every message structured from the start, where I can search by "ip_address is in 1.2.3/24", or "request == 'GET'", or such. Every bit of data should be logged in its pristine form with zero ambiguity, with its original type, and analyzable accordingly.
I think systemd has the beginning of a good idea in here, in that you can actually do this if you care to, and can send arbitrary chunks of data (even binary) to the log if needed.
People who complain about journald not logging in plaintext honestly baffle me, because come on, whose idea of fun is it to do log parsing? And why are we spending CPU cycles on converting timestamps to text and parsing them back?
The problem with logging since time immemorial seems to be log producers throught about it as 'How do we put records from one SQL table into strings?'
IMHO, that's not even the right mental model, because it assumes a constant schema. Log entries are more like types: the fields in one entry may look nothing like the next.
The consequence of using the wrong model is its inevitable collapse into 'Shove everything custom we need into a single field that's somewhat appropriate'.
In the base case that devolves into everything in a one line string. Yet even in structured systems you see the behavior in {use of boring, standard fields correctly} + {everything else in an 'error' or 'customdata' field}.
Thankfully, some tools and ecosystems seem to have grokked this and moved forward.
And honestly, it's mostly an ecosystem problem (producers and consumers), so really needs to be solved via more programmatic self-declaration of data structures.
Yeah, logging doesn't fit well into a RDBMS because fields can change from one message to another.
My imagined ideal logging model is logging two things:
1. A structured tree of data. With field names, types, and content in native format.
2. An end-user hint about which of those fields are of most interest to an user. This is used by a log viewer to generate something like a traditional log file by default.
So an HTTP log entry might contain the entire HTTP request with all the headers and metadata, and the hint then says "Of this, the admin probably want to see timestamp, URL and status code".
You get the convenience of paging visually through what looks like a traditional log, but also everything is available for easy analysis.
To me, GraphQL is a great base model for what logs should be.
The producer declares all possible data.
The consumer requests the specific data it wants, at runtime.
Because fundamentally, there's a mismatch of knowledge. Log consumers won't inherently know everything that can be in logs. Ergo, modern API-style ecosystem models are probably better approaches.
I don't care what format it is, I care about solving problems.
But also I want pristine data. I don't want to be parsing text timestamps to convert them to a number I can then finally use to filter out what happened last Saturday. I want the system to know it is indeed a timestamp, and to natively support date comparisons, and to then be able to output that timestamp in whatever format might be required, if that's needed.
Like this:
journalctl -S '2023-08-06 12:00' -u libvirtd
See, I get what I want and I don't have to figure out where in /var/log it is, what's the timestamp formatted like, if it's compressed and with what. All that is nonsense that gets in the way of getting the actual work done.
Or I can also do stuff like:
journalctl _PID=3663
Isn't it nice that I don't have to recurse through /var/log, uncompress compressed archives, and take into account that some things don't actually write the PID into the log?
That's great if everything you're running plays nice with journald or generates logs in the same structured format, but the problem I always run into with production systems is the mess of various formats coming out of each piece of a running app... I find myself just wanting a folder full of plain text files I can grep/cut/awk my way through, however imperfect that may be.
At this point I've used many different proprietary web based cloud log viewer apps that are slow, glitchy, and each have their own special query syntax. Theoretically I can leverage them for super powerful queries against structured logs, but instead I find myself using different ones frequently enough that I never master the syntax and have to read through the docs to do silly basic searches.
All of the above is an automatic journald feature. If it logs to syslog, or it's a systemd unit that logs to stderr, journald will automatically add various fields like the PID, and log timestamps with microsecond precision.
Logging natively with journald allows you to add custom fields on top.
And it luckily has a journald module, which actually can log some fields in a structured manner. But even that doesn't seem to go far enough according to the docs.
Eg, maybe I want structured logging for the HTTP headers. No way to get that at present, as far as I can tell.
> Sounds like systemd stuff. Why deal with systemd.
Because it's better. Because it logs stuff separated by field, doesn't have problems with unusual characters or newlines, supports cursors, deals internally with log rotation and compression, a whole bunch of cool stuff.
> Use Apache customized logging as the parent comment suggested.
That's exactly what I want to avoid, for reasons explained in my original comment.
Because if you know you need a third value from the logs with ID NNN then you would always receive the third value from NNN message and nothing else. And no regex and locales shenanigans.
Awhile back I had to move a MariaDB database that should have been tiny. When we actually went to look at it, it was over 400GB and obviously the first question was WTF. The developers had decided to log to a table which did make for really simple ways to query the logs, but caused us to have to get a bit creative in the migration (which was actually kind of fun in the end). I'm sure it's been done many times, but it's the first time I had run into it.
Ohh I've seen similar situations. I recall wanting to dump a complex shared dev database, to make it easier to test destructive migrations locally in a container with no risk (that particular DBMS didn't support transactional DDL all that well).
The problems started when I realized that it was far too large to be feasible... until I discovered that about 80-90% of all data was log tables, which in my case I could just skip and export everything else instead.
Now, the logging implementation there used the EAV pattern and got somewhat complicated after years of development and maintenance... however it was mostly okay (in addition to some traditional logging into files and logrotate).
That said, personally I'd use either a specialized log aggregation solution, or at the very least would store logs in a completely separate data store, both for resiliency and security reasons.
We had this at Amazon and I built it at Okta because it was confounding that the closest thing was pumping things to collectdb or some other service that would immediately disassociate data from it’s request context into silos or have to wade through unstructured splunk logs (I don’t know if splunk structured logs are viable now). It’s extremely satisfying to be able to query request metrics and aggregate on arbitrary nested attributes when dealing with active issues.
It’s probably something I should write about. Even though the idea is not novel, it doesn’t seem to be well supported by any libraries that I’m aware of and causes an impedance mismatch with the ones I knew about several years ago (dropwizard metrics and it’s subsequent derivatives).
> The fundamental problem with general log monitoring is that logs are functionally unstructured.
JSON format logs?
One pattern I’ve used before - in a Java app with an RDBMS, create an error table, and every unexpected Java exception gets logged to that table. Then have a system to match problems in that table to known errors, or flag new ones for analysis. (I just clone the table from the production DB into a non-production DB, then have a bunch of views I wrote to analyse them - the fact it is cloned to the non-production DB means I don’t need release management approval to update the definitions of my views.)
At a certain scale this may lead to problems with performance or data volumes, but generally not if the app is small to medium scale (as in practice many apps are), and especially if exceptions are sufficiently infrequent (one hopes so!)
FYI not everyone find 'handwritten' diagramms cute and more importantly sometimes this cuteness actively interfere with reading comperhension, ie this font is quite shitty for me, esp. on the mobile when I need to actively pan and zoom this big diagramm.
[EDIT: I think you are correct, and that it is not as legible on the phone as I thought it was. Using a different font might not fix that, although it's something for me to keep in mind for future blog post diagrams]
I thank you for reading the content.
> FYI not everyone find 'handwritten' diagramms cute and more importantly sometimes this cuteness actively interfere with reading comperhension, ie this font is quite shitty for me, esp. on the mobile when I need to actively pan and zoom this big diagramm.
I understand that not everyone finds this sort of diagram as usable (by which I mean legibility, approachability, memorability and understandability).
By the same token, not everyone finds the usual sort of diagram as usable as this. In my experience, I've found that cartoony/sketched images results in the audience being more receptive to, and remembering more of, the message.
I think this is why this sort of thing is more and more popular these days - it mostly works (not for everyone, obviously).
> on the mobile when I need to actively pan and zoom this big diagramm
I'm sorry about that; I chose an image size that would fit most mobile phones in landscape orientation, and set the fontsize to what I personally could read without my glasses.
For reference, on my mobile, HN text is too tiny for me to read without my glasses, so I was fairly sure that, if I could read it with no glasses on, it should be large enough on most screens for most people.
> In my experience, I've found that cartoony/sketched images results in the audience being more receptive to, and remembering more of, the message.
Subjectively, I'm inclined to agree. Somehow the "sketched" diagrams just seem more approachable, at least up to a certain complexity: that's why tools like Excalidraw have replaced something like LibreOffice Draw for when I need to create a diagram, at least outside of professional goals.
Fonts are still difficult, though. Excalidraw's "handwritten" font is a bit too hard to read, but most of the sans fonts out there don't mesh well with the diagram style otherwise.
Thankfully there's probably tools out there that support custom fonts with little issues and one can probably find one easily.
I see your edit an.. sorry, I'm on the mobile so I would try to be terse:
This font is quite awful, if you need a good hw font - look for what manga scanlators use, and this is quite serious here , those guys spend up to 20 years to hone their skill. In short you you need way more height per glyph.
Regarding the d. Itself: it's good enough on the desktop, it is too big on the mobile. It can be reorg. To be more
Agreed, JSON is just a wire protocol. What TFA complains about is lack of contract on the part of logs' producers. (Schema would be a crucial part of such contract.)
In .Net we're using Serilog which supports CLEF[1], and I'm in the process of changing our non-.Net code to do structured logging to CLEF as well (I made an internal library to support structured logging).
Since Serilog supports consuming CLEF as well, this makes it trivial to upload the non-.Net logs to Azure Application Insights for example.
Might be other options as well, I didn't look much further as this fit our needs well.
edit: This doesn't completely solve the main point in the article of course, as the variables, error codes etc in the structured log message can change willy-nilly in a general system setting.
There are a few more that are fairly common to be logged somewhat separately: severity, host and component/service, but even if so, the structure is lacking in universality (i.e. lot of logging systems support this, but in their own ways). So, yeah, it's not much.
In my limited experience the amount of lines logged correlated with expected or actual activity of the system(s) is perhaps useful for monitoring. Looking into and analyzing the actual log events and their text is then the next step if there seems to be too much or too little information logged.
If you're going to treat logs as a db entry and afford them a schema, then by all means knock yourself out.
The main point he's trying to make is not just about the logs you wrote but about logs coming from other systems or services, e.g. monitoring kernel logs in your OS. As he rightly points out, one of the reasons is that logs are not an API.
> One reason this happens is that almost no one considers log messages to be an API, and so they feel free to change log messages at whim.
create table log (dt timestamp not null primary key, msg text not null)
is usually all you need to start sifting through the haystack. Problem with this approach is if you aren't diligent, you'll end up killing you app AND you're db.
We already established that log sifting at scale isn’t productive nor does it work for reasons outlined in the article. This was just an answer to how to do it in a smaller scale. Yeah, primary key is going to give you problems, a simple index shouldn’t but the issue is this, logs are not event sources - or shouldn’t be. The only time you should be looking is when your looking for stack trace and even then there’s better options like sentry.
> And if you don't do it asyn out of your request path you add unnecessary latency to your hotpath.
Well, in my case - the table only logs unexpectedly failed requests (so not “user entered wrong password”, more like “HTTP 500 NullPointerException”.) That’s not on hot path by definition.
I agree logging every single HTTP request to an RDBMS, even a 200 GET, is dumb.
Logging is one of those things that remains mostly an afterthought for a lot of languages, frameworks, and engineers.
It's not that hard to get organized. Here's what I've been doing since the last ten years on most of my projects (Java & Kotlin mostly but you should be bale to do this for anything).
1) log levels matter. Debug/tracing is disabled in production. Info is informational only and should not have a signal to noise ratio that gets annoying (people doing debug logging at info level). Warning frequency should be low. If you are not going to fix it, it's not worthy of a warning. Errors should cause alerts and people to be woken up. Simple rule but only if you enforce it. Don't log at error level unless it really is worth waking somebody up for (e.g. me). An error is not "something totally expected happened but I could not be arsed to think about handling that in a sane way". I've seen projects that routinely log thousands of errors per hour and never fix anything until after customers start yelling on the phone. Log levels are totally irrelevant in such projects. Nobody bothers to look at those errors. They are no longer actionable. If errors are normal and expected behavior, how do you tell when something abnormal and unexpected happens? You can't; unless you make people do something about those errors and create a culture where having errors is simply not an acceptable state for the product to be in. Life is great when you do that. We have zero errors on most days. When they do happen, it's usually because something changed. And then we fix that and it goes quiet again. Simple rule to enforce. Generates very little work. But you have to enforce it.
2) Java logging frameworks have something called a mapped diagnostic context (MDC). This is great. Basically it means every log entry can have a context where you can keep track of things in e.g. your request like headers, user agents, ip addresses, session ids, etc. Why don't other languages have this? I don't know. Seriously, how is this not a thing for any web development framework worthy of the name. Why would you not want to know this information when something happens?
3) Logging messages are structured data. Whether you like it or not. Plain text is a shitty way to represent structured data. If you can, log in json format. You have timestamps, logger names, log levels, attributes in your MDC, attributes coming from your server environment like the host name, service name, etc. All of it is relevant.
4) Tailing and grepping plain text logs simply does not scale. It's what you have to do when your ops team is too incompetent to setup proper logging. Usually goes hand in hand with having snow flake servers that people ssh into. It's actually the #1 excuse to have boxes you can ssh into to begin with. Solution: logs go into a data store that allows you to filter on this data. Not having this is the equivalent of running blind. Completely and utterly unacceptable. Most cloud environments come with a reasonably OK logging console but you might want to upgrade to something with a bit more querying capability. But done right even those default logging consoles can be capable enough.
5) Your logs should have alerts on them. If errors happen, alerts should happen and people should do things about those errors. If logs go silent when they shouldn't be, alerts should happen because something is probably broken. If there's a weird spike in logging volume, alerts should happen. Alerts should be actionable and be exceptional. If something is alerting all the time, nobody will check when something important actually does happen. Tricky to get right but once you do, you can react quickly to any incidents.
Deliberately keeping product names out of this. There are plenty of libraries, tools and products that allow you to do this properly. That most likely includes your preferred software stack. And if it doesn't, use something more production ready that does. Or fix it (not that hard usually).
I'd characterize logs as a poor tool for doing the two tasks people use them for: investigating the state of the server, or investigating execution of a request. I instead am a strong believer in separate tools for those two tasks.
Server state should be exposed through metrics. Metrics have far fewer sharp edges than logs, and it's more obvious how to correctly produce, consume, and alert on them. I've seen (variations of) your 5 action items needed for the logs of every company I've worked at, but they've never applied to metrics.
Executions should be exposed through tracing. I'm kind-of cheating here: I expect the traces to have logs attached. But a well-done tracing system, where a developer can add a flag to their Postman query and their request was traced with the debug level set only for that request is a magical thing.
> Solution: logs go into a data store that allows you to filter on this data.
You can get very far getting to know the operating system's remote logging machinery can get you very far on this. It's amazing how often people basically duplicate this and how often people just write logs to text files or database tables instead of hooking up to the tooling that comes with the OS.
We used to call it Perl Programmer's Disease: at some point every Perl programmer in the late 1990s wrote a script to send Apache logs to a remote host because doing that was faster than learning how to make Apache log to a remote host directly.
> log levels matter. Logging messages are structured data.
Swift has those [0][1] and other features like jumping to the file and line of code from where the log was generated, but I wish there was a way to easily add extra information to each message in the debug console such as the current frame being rendered etc. Something I've been wrestling to do for the past few days, but if I write a custom logging function, then the IDE's debug console thinks every log message was generated from my custom function.
And god I wish we started making use of COLOR within text-heavy information. Being able to color different words/values in a log message would massively improve readability and comprehension.
I only used it once for a class in grad school, but it’s things like this that make Swift feel like a really well intentioned programming language, especially paired with the xcode ecosystem.
You've made a lot of good points. I've stepped into a team that is supporting a large product that has been going for years. There are so many error logs and alerts that nobody notices them any more - its so frustrating.
- I (as the CTO) get grumpy when I get alerted for nothing or spammed with non stop alerts. And I see all the alerts. Basically that means I tell people to get their act together (or lead by example). In fairness, it's quite often me that made the changes that caused me to get alerted and grumpy. This is not about finger pointing but about it genuinely being annoying to have to deal with this. This is a necessary level of pain that you seek to minimize.
- I get more grumpy when I don't get alerted when the thing actually breaks. This means I have to explain to others why shit was broken for hours/days on end without me doing anything about it. The dog ate my homework doesn't quite cut it here. I'm responsible, so I need to know.
The balance here is making sure every error gets logged and then making sure that everything that does get logged gets resolved in a way that makes the problem go away permanently. It's either a bug (fix it), an infrastructure failure (fix it), or something that isn't an error (so fix that it doesn't log a such).
It logs locally in plain text and in color, for easy visual parsing, but in production - it's in JSON.
It also lets you add arbitrary one-time properties or "sticky" constants (environment, process ID), or dynamic properties based on current context of the logger, such as information specific to a specific user request.
I've used it in the past. I forget what the implementation of syslog was that we were using (I want to say it was rsyslog) but it didn't support the RFC above. There are two syslog formats, the one in that RFC, and an older one, IIRC "BSD syslog", which is worse.
So, if your implementation supports it.
But JSON is loads easier to emit and to build random parsers around.
In our case, syslog was then just upstreaming the logs as JSON to a more central collector, so we ended up just cutting it out of the loop.
Compressor model log watcher. When a log entry has unusually high entropy score it higher. Add that to your regexp tables of "things to watch for" and even a very simple parser can give you a better first pass log filter than an untrained intern.
"structured or not" is a valid discussion; but irrelevant to the point. We're not good at watching our logs for the things we wanted to see; nor are we good at emitting the data we want in the logs in the first place. Too many conflicting purposes in the same place.
not that I know of. I had a lovely system that had audio alerts for all sorts of things and multiple time windows for comparison and statistics etc. long ago now, big mass of python script tuned for that environment.
Made my office sound like a jungle: bird chirps for firewall probes, coin clatters and cash register "Kaching!" for sales page hits and actual "someone gave us money" sales, etc. It was fun.
Request logging should be done by an application gateway; it will do a more honest job of it. In applications, don't log anything except:
- application startup and shutdown (at INFO level)
- occurrences that indicate a bug in the system logging (at ERROR level)
- occurrences that indicate a bug in another of your systems (at WARN level)
The last two require a lot of education and discipline to stop people from logging rare but valid circumstances, bad input originating outside your software, and "important" events. The answer to "but don't we want to know when..." arguments should always be, "If it's that important, emit it as a metric or store it in an appropriate datastore." Anything logged at WARN or ERROR should be something that can be addressed by fixing code.
If you stick to this discipline, monitoring logs is valuable and reasonably simple. You can alert on any WARN and ERROR level logging. There's nothing like looking at a month of logs and seeing only actionable information and a handful of application lifecycle events. (There's also nothing like looking at six months of logs from a stable system and only seeing lifecycle events.)
It is hard to stick to this discipline. You need a manager who believes in it and will back it up when engineers want to depart from it, and who will always prioritize fixing violations.
Why is it so hard to make engineers follow these rules? Because initially, it makes them feel incredibly anxious. It feels irresponsible to throw away so much "important" information instead of logging it. After working this way for a while, though, they realize that it actually forces a higher level of responsibility. Logging information in noisy logs might feel better than throwing it away, but it's not. It creates an illusion of having handled the information responsibly. By taking away the illusory option, you force people to make a real decision between throwing it away and saving it in an actionable way, by emitting it as a metric or storing it in a datastore to be processed.
I've been here with this and having logs also emitted by application/web servers is critical too. If you only have it at the gateway, and it emits a 503 or 504, did the request make it to the web server? Maybe? You have no signal. Seeing a timeout at the gateway/load-balancer and the web server log that it serviced the request successfully but took 45s tells you very critical information. If you didn't have the web log, you have a missing signal that tells you critical information.
Despite having to managed TBs of logs per day and sift through them at times, I'd rather have too much logs. However, we did not alert on any of them. All alerting was symptoms based via SLOs (error rate, latency). Logs were only used for debugging.
> If you only have it at the gateway, and it emits a 503 or 504, did the request make it to the web server? Maybe?
I was taught a perfect solution to this. Only ever return 200-300 from your web server (not applicable for most public APIs, though). My web server is not a gateway, not a resource access mechanism as envisioned by people in the 90s. It’s always an RPC server. REST is RPC. JSON is RPC. I let my outsourced CDN do HTTP code shenanigans, but any apps I develop are 200 all the time. Want to know if it failed? Easy!
More important, this is generally expected when calling any kind of API over HTTP.
Returning a 200 in an error situation makes it very difficult to diagnose errors. For example, the F12 debugging pane in my browser color-codes errors responses. Fiddler does the same thing too.
More important: Languages / libraries have built-in mechanisms for handling these errors, which make error situations easier to handle (or not handle.) For example, some C# libraries will always throw an exception on a 4xx or 5xx response. If your oddball API returns a 200 in an error situation, it breaks normal error handling patterns. (And could result in making situations where "success": false much harder to track down.)
And finally: Because error situations are unusual, they often aren't encountered in the normal day-to-day debugging of your APIs consumers. As a result, your oddball API's failure situation is probably untested in whoever is calling your API. When your API fails (because it will at some point,) there's a high chance your consumer won't check the success flag and parse the response as if it's successful. (Again, because you're not following normal HTTP semantics.) This will trigger unpredictable failures in your consumers.
> Returning a 200 in an error situation makes it very difficult to diagnose errors. For example, the F12 debugging pane in my browser color-codes errors responses. Fiddler does the same thing too.
I strongly disagree; let me try to convince you why those tools are correct and why it's still wrong to return non-2xx error codes from the application.
The F12 debugging pane and related tools which color code non-2xx response codes are correct for returned documents, not for API requests. For returned documents, HTTP is the application protocol, for API requests HTTP is the transport medium! These tools are not able to make the distinction (yet) between "calling an API" and "retrieving a document".
In HTTP it's literally called the status code, not the error code.[1]
Look at it this way, when you're in ssh to a remote host, any errors in the transport medium is reported within the TCP stream, not inside the TCP headers or inside the IP headers. Errors from ssh itself don't set error bits in the TCP stream or IP packets. You'd be horrified if, within ssh, a shell error (say, 'cd /non-existent-dir') sent error codes in the error fields of TCP headers or IP headers.
So, yeah, errors in the application layer should not set error fields in the transport medium. When serving static files or documents, HTTP is the application layer, so it should report things like '404 not found'. When GETting an API endpoint
results in the application not find (for example) 'web.config', it should not* return a 404. After all, the handler was* found, the URL is correct, so don't overload the 404 for something else.
[1] Even curl handles it properly for the level it is working at. Since it is one layer higher than even the HTTP API (because it returns a result to the shell that called it), no errors are returned for any non-2xx responses, because, from the shell PoV, that's not an error.
> Languages / libraries have built-in mechanisms for handling these errors
And it's always easy for me to override this. I've been doing it this way for years - all of the startups I've worked at do it this way - and it's extremely successful.
> whoever is calling your API
Just internal use. For external use I agree meeting expectations is important. Users will expect a 400/500 for certain issues.
> Remember, you're breaking debugging tools like Fiddler when you do this...
> ...And, whoever inherits your code probably won't like working with it. Doing weirdo things like that can hurt your reputation in a team.
Well, it explains why web APIs are such a hot mess: the people creating the tools don't know the difference between transport errors and application errors, the developers creating the applications don't know the difference, and the developers calling into the application don't know the difference.
It's a pretty important difference, and it all other protocol stacks care is taken not to side-step any layer and directly fiddle with the transport layers from the application layers.
Right now, a client getting a 5xx response can't tell if the application had an error or if the proxy is misconfigured, because the application developers are sending proxy errors/server errors (5xx) and trampling all over the namespace of the transport medium.
The system appears to be well structured, but the conventions were all set by developers who were all noobs. I don't think, in 25 years of development, I ever saw a sockets program (neither client nor server) where the application detected an error and set error-bits in the IP datagram, and yet in web-development, I see this all the time.
Yup. I'm not sure I've perfectly figured out where to draw the line, but a 500 error should mean a 3rd party proxy failed to get a response from your server - not that you caught an exception in the server and specifically crafted an internal server error response.
Should you start HTTP responses with "ACK" because it's based on TCP? No. Then why start your HTTP responses with "HTTP/2 500" because your call to OpenAI timed out?
There's always a bit of a cultural adjustment needed for people who are onboarded to this paradigm (myself included! It took a year before I bought in). But everyone has universally either been converted or at least had to admit that the system works.
That still doesn’t explain any actual problem, it explains what you think is the cause behind the unspecified problem, jumping right over the key question.
HTTP is a hyper text transfer protocol, designed as such. My application is a RPC front-end for a series of data stores, AI models, etc.
Using HTTP codes for your application's protocol is a mismatch. There are some fairly general-purpose HTTP error codes that can meet many application's use cases, but the overlap is not perfect. You can get greater granularity by ignoring it entirely.
Going HTTP 200-only means any non-200 is now definitively from 3rd party middleware, a router, proxy, etc. The boolean check of "did I hit my application code?" is easy and useful.
Its easy and useful if you just return details in response bodies, which you can do with errors as well as 200s, and that lets everything else (including client code) that deals with your responses (which doesn’t generally care if it hit your application code as likely as it cares about the things HTTP error codes communicate) handle errors without having to code for your bespoke method of error reporting.
I only agree with this for a request/response application.
I disagree for fully automated applications, for example message-driven ones. Logging key steps is important for situations where you need that post-mortem information after a problem already happened, because you often cannot reproduce the exact environment in which the problem was encountered. Numbers and timing information can be very useful in these systems, as well as information about what path the system will take (tracing) when there are many.
> The first problem with monitoring this way is that there's no guarantee that the message you're monitoring for won't change.
This is a solved problem (at least for the linux kernel) with printk indexing[0]. So you can query the running kernel what log messages it can output. With that your monitoring tool can check when an expected message was changed and you get the messages in printf format so you can parse them if you want.
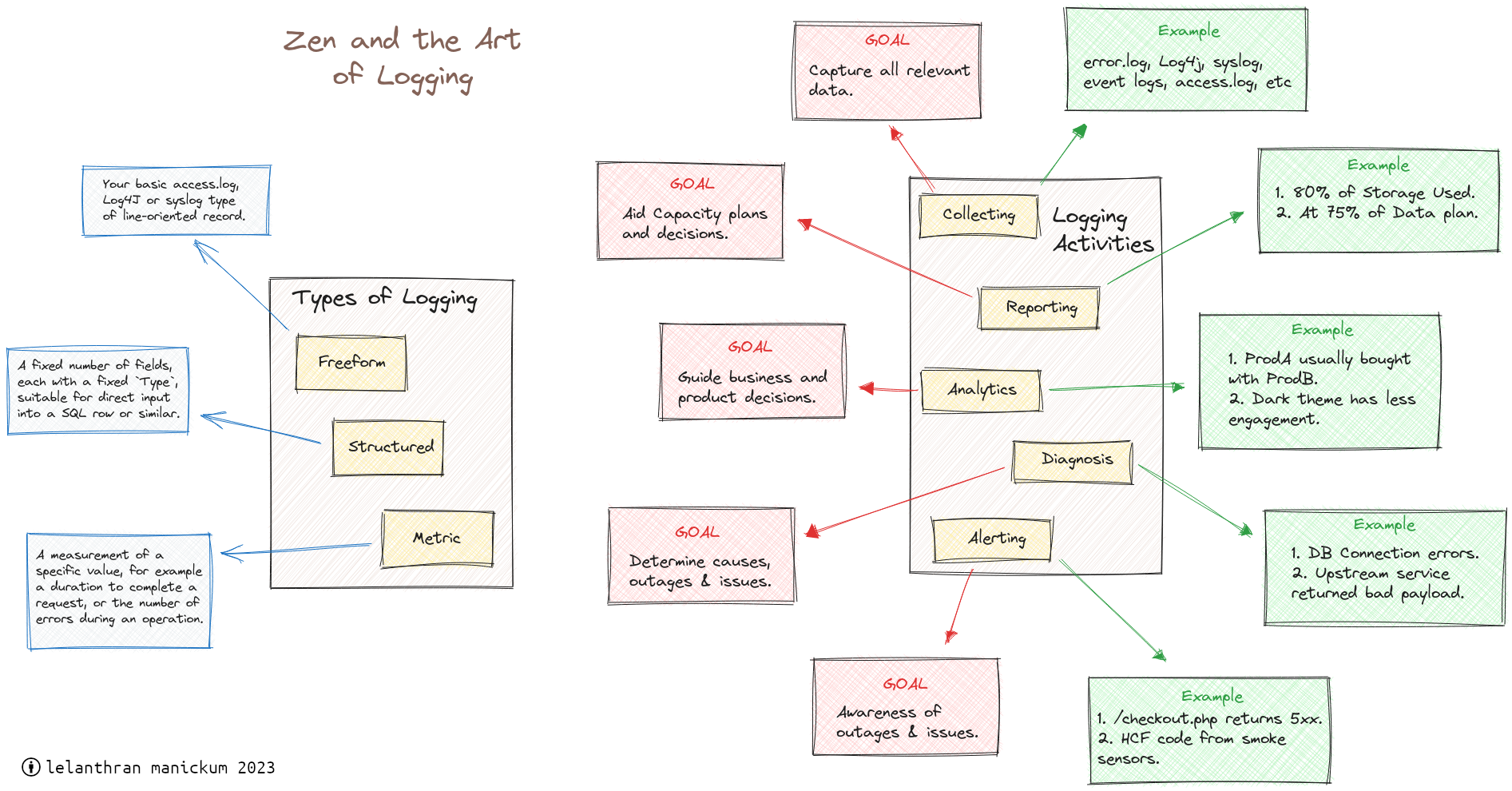
What does the title intended to mean? It's summarized at the end.
> But monitoring your logs looks productive and certainly sounds good and proper. You can write some positive matches to find known problems, you can write some negative matches to discard noise, you can 'look for anomalies' and then refine your filtering, and so on. That's what makes it a tarpit; it's quite easy to thoroughly mire yourself in progressively more complex log monitoring.
Nothing surprising here. Spend only the time that's worthwhile and has a point. I don't think I've done any bottom-up (just because) log analysis other than counting logged exception types/sites.
That does not match recent experience with datadog or the GCP log aggregator
We derived values out of that ( meaning : OPS having a playbook to troubleshot, alarms & prod support in general )
This reminds me of the time the VP of engineering wanted to “just open telnet up” to solve a short term problem (this was a while ago) so I showed him the firewall logs of all the probes to the telnet port. Then we went down the rabbit hole … “what else is being probed”, “how do we report these people”, “block all those IP addresses”, etc. etc.
Logging can be useful AND a rabbit hole. If you have the horsepower to manage the firehose, knock yourself out.
AH the 'i didnt know' side of logging. Once you start logging you probably will find all sorts of things going on you did not know about. Things you probably now need to address.
I have also made the mistake of logging because I could. Logging without a plan I have found to not be worth it. If you are not going to take actions on those logs. Why are you keeping/making them? The flip side is when something breaks you will know you want those logs. Hopefully, you will have what you need in them (usually not). But then you turn on more and more as you need it and eventually find a happy medium.
I've seen similar panic+rabbit holes on people seeing the HTTP request logs. They contain a constant stream of requests for WP vulns., phpMyAdmin vulns/cred stuffing, etc. (We ran none of this, so it shouldn't've been a concern.)
It is amazing how many people (even ostensibly security people…) don't know that, if you're on the Internet, you're being subjected to a never ending torrent of it.
Just as it happens with backups, if you overlook the quality and utility of logs it will come back to haunt you, often costing 10x more time and effort.
This seems backwards to me in 2023. Logs seem like valuable data to train your AI on in order to automate as much of the basic inference away as possible.
What if the logs were missing entries though? Would you train your AI on missing data?
I found a bug in rsyslog a few years ago, where in certain conditions, log entries were missing. If you know the pattern for what log entries were going missing, then you could craft a very stealthy attack on the system and remain undetected in the logs.
> there's no guarantee that the message you're monitoring for won't change. Maybe someday the Linux kernel developers will decide to put more information in their MCE messages and change the format.
How often do the messages change? How often do you need to re-train the AI? Is it worthwhile?
A properly trained one shouldn't overfit. If it was trainer to just detect error lines and flag them for human review I think that'd be very beneficial
Not as accurate as string matching though. And more time/compute intensive
I generally feel that way regarding the log systems I've worked with, specifically since they were some of the first I helped implement and/or design, and thus I'd not consider them high quality. However, what would be better than monitoring logs? Any sort of monitoring I know of looks at logs produced by one system or another... I'm not sure if there is an alternative.
Start treating reporting and monitoring as first class parts of your domain instead of some text. Do the same modelling/event storming exercises you’d do for everything else with these operational requirements.
> Sometimes you can even extract metrics from logs by looking for specific log lines
This looks backwards from the app dev's perspective.
- Metrics are strictly structured, documented data. They are a first-class output.
- "Strictly structured logs" is contradiction in terms. These are just events to be sent to a pub/sub, also a first-class output.
- Logs are unstructured, unknown, bleeding-edge, grey-area data, which can potentially become either metrics, or events, or bug tickets.
If I output data as metrics, I don't output it again as logs - that'd be just noise.
But of course other apps/systems can have a wholly different approach and force people to invest a lot into sorting out that dumpster fire. The leverage is on the producer side.
if we are talking about the "log files" aspect then one certainly needs to get away from that and have all log events in a single searchable interface.
I like monitoring my logs, but I hate making it an added cost and piece of infrastructure. While it lacks a ton of features that ideal solutions have, CloudWatch Log Insights is "good enough" for those times I need to comb, requires no additional infrastructure, and is dirt-cheap.
We used to split logs into two buckets at work, one containing parsable log lines that used the expected format and schema and then the rest in the second one.
That way we could centralise all logs and detect different kinds of failures, like unexpected log lines appearing.
structured logging has been a thing for a long time, so I don’t really buy this argument.
the problem with monitoring and alerting derived from logs is that log ingestion pipelines usually have the property that when they get saturated, they get behind in time and catch up later. That’s more or less the opposite of what you want for an alerting pipeline.
{kind=link}
If I see a spike in errors, I can, in real time, count them by user id, group by region, filter out by some other field, then have the table of events generate a live line chart easily showing the error rates over time, and pin pointing the exact moment an error started.
Less than five to ten minutes after detection or report and I can be talking with another team about a change they released at time $x, including a list of affected users for product teams to reach out to if needed.