Git is one of those things that people (including myself) have frequently derided for being "unintuitive", "full of footguns", etc.
But after looking at other source control options, I find it to be an absolute joy to use -- even for very complex tasks. The VC problem itself is where the complexity lies. Any tool that deals with collaborative working on document will present the same issues that Git does. Maybe worse.
Be thankful that you can use any tool you want to create plain-text diffs; that git performs operations quickly; that resets, undo's, etc are possible; that the precise history (both of the actual state and the steps taken to get there) is entirely legible; that each command performs a single, well-defined, and well documented atomic operation; that the tool is extensible, command-line script-able, usable locally, free; that it keeps the size of a repository small; that it is scalable across any number of contributors working simultaneously.
Some, all, or none of these may be true with other tools.
Anyone ever had to do a diff of a Microsoft Visio document by hand? Anyone had to manually type in the name of a document and its revision by hand into a web form? Anyone ever spent an afternoon working on a document, only to realize that someone else already made the changes you made but forgot to update the filaname which caused their changes not to be visible to you? Programmers are spoiled with the best tools in version control. People in other domains are doing this, without even knowing that they are doing this. They are making commits, merging, rebasing, etc.. without even having a word to describe it.
> But after looking at other source control options, I find it to be an absolute joy to use -- even for very complex tasks. The VC problem itself is where the complexity lies.
I think mercurial is a lot better and more intuitive.
Yes, But I would say that is a minor issue; I appreciate that there actually is lots of documentation for the precise and unchanging behavior of `git branch`!
Instead of:
"Oh, email this to doc management. Depends on who you get. If you get Nancy, she will double check that your rev C filename matches with your rev D filename in the changes section. Matteo does it differently though, sometimes you do need to include redlines for minor AND major changes, even if the major version gets rev'd. Oh, that doc doesn't have any minor changes at all. I don't really know why, but you better not include minor changes because that will be flagged for sure, only on this document though, for every other one you should have C->D in the footer. Oh that one, the template never got updated so you actually have to type it in manually. Yeah, no idea why it does that.
It would be great if you got the change review back by Wednesday because regulatory has a preliminary product summative scheduled Monday. There's a confluence page for which doc manager should be CC'd for each document to get the review back in time."
Why does the first “origin main” not need a slash and the second does? I’m sure there’s a “perfectly reasonable” explanation for it but it screams UX inconsistency to me.
In before people tell me that it makes perfect sense because that’s how Git works. Well duh, because Git was designed that way, not that the problem that it’s encapsulating demands it
"Just memorize these shell commands and type them to sync up. If you get errors, save your work elsewhere, delete the project, and download a a fresh copy."
I wish people would do a little bit of yak shaving when they run into errors (usually some form of merge conflict when pulling) to learn how to fix them, roll back, etc. They would learn how to appreciate the power and flexibility of git then.
I've helped people in my own open source project when they hit git roadblocks. They've never needed to save out their work and wipe their repo. There was always a solution within git and once they learned it, they really understood how version control worked much better.
By "abstractions", parent means the abstract entities forming the application domain model. The user interface to that domain model is not the abstractions.
I don’t get the distinction. An application’s domain model always has an interface layer. It can either be API or UI, but in either case it’s something your model allows to expose.
Up to 2011 I used Subversion. Then I worked for a year for a company that used CVS. So, by comparison, my time with Subversion looks trouble-free, as you can imagine. I've worked in Git ever since, but every time Git makes my feet hurt, I think back with fond memories to Subversion and TortoiseSVN, probably unwarranted so.
I use Mercurial on a volunteer project and it gives me problem after problem including repository corruptions and it's extremely slow for the same things git does before I can blink. I often wish it never existed so our team was never tempted to try it over industry standard git. Everything integrates with git, git is optimized every day by devs all over the world, every issue you can have with git is on stackoverflow, and it's essentially bug-free, meanwhile mercurial is some niche thing with embarrassing bugs written in python.
It's especially vexing that mercurial throws a fit if you try to do anything like pull with changes in your repository while git does the sensible thing and just works.
Mercurial was optimized for performance on windows. On other OSes it was worse. But the reason it didn't win isn't that.
It was GitHub. GitHub changed it from "use one of several analogous products"[0] to network effects.
[0] Joel, founder of StackOverflow, had a GitHub like competitor that used either git or mercurial commands on the same repository. Just as one example of how similar they are.
I think one of the answer's is sadly just: Mercurial was written in Python.
Regardless of what the benchmarked real-world performance of Mercurial was or how well optimized it was, there is a class of developer that thinks all Python is slow and may never change their mind about it.
Python seemed a good decision: git had a two week headstart and Mercurial was faster to hit many usability milestones (and arguably git may never hit some of them, jk). Mercurial had good Windows support from early on (and doesn't need to ship like half of the GNU userland to do it).
I just don't think it should be surprising that some Linux kernel developers dismissed Mercurial off-hand just for being written in Python. I also don't think it is a coincidence that early GitHub ignored Mercurial just about as dismissively. (Ruby and Python aren't entirely "competitors" but there isn't always a lot of shared love between them.)
The "core" (most of the "plumbing") was always C/C++ and most of those bash scripts (with very few Perl exceptions) were automating GNU C/C++ tools. I've certainly referred to git as a Frankenstein's monster of shell scripts myself, but the sorts of developers that hate Python often don't seem to see bash scripts, they see lots of little invocations of C/C++ tools and "C/C++ core" matters to them. (They also tend to get irrationally angry when you challenge that logic and point out what the C in CPython, the most common Python runtime, stands for.)
> Whether it was the language or not, Mercurial was objectively slower than Git.
That was not my experience, but I was on Windows at the time. Mercurial "objectively" had good Windows performance. (Not just because it ran at all, versus how much work it took to tame Frankenstein's Monster of shell scripts that was early git to run at all on Windows. But also because it's file system transaction model always fit Windows better.)
(ETA: Also, to be fair, my "team" at the time was darcs and my opinions on VCS performance at the time were from a very different perspective.)
IMO, it really helped that Linux/Linus had a lot more fame. At the time there was drama around Bitkeeper, which Linux found acceptable, but was closed source.
I don't think most people really care that much about performance; rather a vocal minority. Most devs are not that discerning in choosing their tools: they'll happily use what's given to them or what's mainstream when they're learning and stick with it as long as they can. This is the quiet (massive) majority that mostly don't post on HN.
I see a lot of people attributing Git's "win" to GitHub, and that's likely the biggest nail in the coffin, but the GH devs chose it because it was already reasonably popular and it was popular because of Linus Torvalds.
Because it's called Github, not Mercurialhub ;) (I bet if Github would have chosen Mercurial instead, the popularity would be reversed, at the time I switched to Github I was just looking for an alternative to SourceForge for hosting my open source stuff, but didn't care much about the actual version control system).
I have used Mercurial at work for a few years about a decade ago after already knowing git basics (but only basics back then). It never felt "better" or "worse" to me, it was just a slightly different git. Its branch handling was a bit confusing compared to git's, but it was manageable.
One thing that perhaps let me understand git better later was how `hg pull` works actually like `git fetch` and makes more sense than `git pull`.
I started with Git and now work with Subversion. SVN is definitely simpler but I find myself regularly getting frustrated with its relative lack of features and the wait times inherant to centralized version control systems.
You have two options. You can use the git-svn bridge or manage your own patches.
git-svn has a lot of good features that are specific to it, so it’s worth learning it like a new tool rather than a git feature. Get comfortable with it from some tutorials, then read the man page from top to bottom. It’s worth it.
The cheapo version is to git init and checkout of your source code, pretend it’s a git project, and then produce a patch for your branch at the end. You might even be able to use svn and git commands in the same directory? git for managing your private “work in progress” branches, locally, and svn to track upstream and submit work.
It's not quite fair to compare Distributed VCS to strictly centralized IMNHO (even if a lot of people are using git as a centralized VCS with GitHub in the middle).
Still, it is interesting to compare workflows and common gotchas.
> But after looking at other source control options,
...
> Anyone ever had to do a diff of a Microsoft Visio document by hand? Anyone had to manually type in the name of a document and its revision by hand into a web form? Anyone ever spent an afternoon working on a document, only to realize that someone else already made the changes you made but forgot to update the filaname which caused their changes not to be visible to you? Programmers are spoiled with the best tools in version control. People in other domains are doing this, without even knowing that they are doing this. They are making commits, merging, rebasing, etc.. without even having a word to describe it.
I don't see what that last paragraph has to do with git being any good. You're looking at the difficulty of collaboration without revision control, and saying "this shows how good this particular revision control system is".
If you think git is good because of that last paragraph, then it's no better than CVS.
That isn't the point there. It's that we should be thankfuly for text-based tools in general, compared to most other professions' experience of digital collaboration.
> But after looking at other source control options
Genuinely curious: what other VCS are you referencing here?
Personally, I have not used many, but of the total of three that I have used, Git is the hardest.
I've used SVN and I will start by saying that Git is objectively better. But that "better" is a balance between ease-of-use and features/power. SVN is much much nicer to use than Git in certain (admittedly narrow) contexts. To be more specific, the SVN (cli) user interface is a lot nicer to use than Git's. Merge conflict resolution is improved in Git, and decentralisation is pretty useful - the ability to setup a local repo and persist changes to disk immediately with no remote is essential in modern version control. These things make Git better but it is not easier to use.
Then of course there's Mercurial: somehow delivers on all the things Git has over SVN while still being almost as easy to use as SVN. No competition here.
>But after looking at other source control options, I find it to be an absolute joy to use
Git is objectively pretty janky, though, so it seems to me this statement is an indictment of Subversion and CVS rather than some statement about the virtues of git.
I think it's much like the case with Wireguard. It's not that wireguard is some super amazing thing to deserve such adulation; it just sucks (a lot) less than what came before it.
Nope, I'm not even talking about subversion or CVS (although, I certainly prefer git to those, and it's a fun discussion).
I am talking about patched-together workflows developed at regulatory agencies, law offices and the like; collaborative editing of... non-code "information".
People who are doing "version control" but don't know that they are doing version control. They are editing documents in parallel. They are changing documents and recording the changes with a paper trail and diffs. They are working on separate parts of the same document in parallel, and managing the conflicts that appear in those documents when they are rev'd. They are sending their changes to someone else to have them reviewed before they are rev'd. Version control.
Their workflows and their tools are positively prehistoric compared to what is being discussed here.
I'm an aerospace engineer so I know all about Windows shops that operate on the "RequirementsSpec-final (3) Nate's comments.docx" school of version control.
Half the industry runs on excel spreadsheets. I feel your pain.
There is absolutely a ton of technical barrier to shipping this. I don't know that much about internals, and I can imagine quite a few off the top of my head.
For example: a number of operations are not reversible in the current git model because they're not tracked. We'd need git to start tracking uncommitted changes so that it can restore them on `undo`. That's a fundamental change to how git works and I doubt that the idea would be entertained
> For example: a number of operations are not reversible in the current git model because they're not tracked. We'd need git to start tracking uncommitted changes so that it can restore them on `undo`.
No? If an operation is not reversible then it’s not undoable. That’s not abnormal. The opposite really.
Do you mean literally deleting your last commit? That would break a lot of the guarantees gained from the append only graph that git exploits for nearly everything it does. I think undo is too ambiguous in the context of vcs that it would be risky to introduce as a part of the cli api. What would you expect undo to do?
The commit graph is effectively append-only, but the named pointers into that graph can be reassigned at will, which means some commits can become (more or less) unreachable and eligible for garbage collection.
Yes, it is. You can't change a commit: you have to create a new one, and create copies of any child commits, which are also different commits. This generates a different graph. What changes are things like tags, branches and HEAD, but they're just pointers, not part of the graph itself.
Sure, but there's no generic "db rollback" command that reverses the last thing you did. This command would have to decide what to do for every previous command, no?
> Sure, but there's no generic "db rollback" command that reverses the last thing you did.
Technically nothing prevents the database automatically creating a subtransaction / savepoint for every operation you perform.
> This command would have to decide what to do for every previous command, no?
Yes? Not sure I see what the issue with that is.
And technically much of the information is already encoded in the reflog. The two big additional informations you’d need are:
1. Tracking changes to refs as they’re not necessarily tracked by the reflog, but there should only be a small number of plumbing operations manipulating refs so it’s not really a concern.
2. Tracking changes to the index, would likely be a lot more difficult.
> Yes? Not sure I see what the issue with that is.
The issue is that it sounds even more confusing in practice than status quo.
If you don't understand git, you can't rely on `git undo` cause you don't know what's undoable and what isn't. And if you do understand git, you don't need `git undo` in the first place, you can already undo things by yourself.
> why is there no git undo command shipped in box? There is absolutely no technical barrier to shipping such a command.
To undo something you gotta know what thing-that-you-did to undo in the first place.
This is often achieved using the command design pattern, but git does not record commands, nor has such a concept. It only has state.
Let's imagine it does record commands, what should a purported magical "undo" right after each one of these commands?
- git branch topic
- git branch -f topic cafebead
- git checkout topic
- git checkout cafebead
- git checkout -- file
- git commit # detached
- git commit # on branch
- git commit --amend
- git reset HEAD^
- git reset --hard HEAD^
- git add foo
- git rm foo
- git rm --cached bar
- git merge a b c # merge succeeds
- git merge a b c # merge fails
- git merge a b c # merge fails, resolve conflicts, add, continue
- git merge --abort
- git cherry-pick
- git cherry-pick --abort
- git rebase main
- git rebase --onto main cafebead^ topic
- git rebase -i # pick, reword, drop commits, one fails
- git rebase -i # pick, reword, drop commits, one fails, fix, add, continue
- git rebase --abort
- git stash
- git fetch
- git pull
You could come up with answers to that, but then, they would make sense only with one use case of what you intended to do with each command. To cater for that you'd start to need "git undo --this-way" or "--that-way". Any command that cannot be undone would break undo. Any external tool would need to operate using only commands, or it would break undo. Any external too or script extending git by chaining commands would need to implement new commands with undo for it not to break undo (otherwise "git undo" would only undo the last one). Also, consider that there may be files untracked in the tree and tracked in other branches, become tracked midway through a merge or rebase and whatnot. It becomes stupendously complex stupendously fast.
If "git undo" were made for beginner users to make it more approachable, then it would fail as soon as the user faced a non-undoable situation and not understand why ("this undo is stupid!"). If "git undo" were made for advanced users to make it more convenient, then it would fail as soon as the user used advanced tools or scripts breaking undo.
What git chose to do is to be the simplest possible tool: it's a DAG made out of commits that can be labeled, and its commands operate on the DAG and labels (with a staging area so that commit creation is transactional). Commits are not removed until they're GC'd and "undoing" is moving back labels to be pointing to commits as they were before, so not having "git undo" is not even dangerous.
To make "git undo" robust, git would need to hide and/or change its core design + API + UI, which would make it not-git. I'd argue that part of the success of git is these "internals" (which are its actual interface) made it spectacularly easy to script, extend, compose, write alternative implementations of...
The only way to implement "git undo" is to embrace the database-like design (stage manipulation with git add and git rm are preparing a transaction that gets committed with git commit) and explicitly start (git start / git begin, records current work tree + refs + index state) and end (git end, a.k.a discard recorded state) or rollback (git undo / git rollback, restore recorded state).
BEGIN TRANSACTION git begin
INSERT INTO ... echo >> foo && git add foo && git commit
UPDATE ... WHERE git cherry-pick bar
DELETE ... (SELECT ...) git rm baz && git commit
COMMIT // or ROLLBACK git end # or git rollback
> You could come up with answers to that, but then, they would make sense only with one use case of what you intended to do with each command. To cater for that you'd start to need "git undo --this-way" or "--that-way".
I don't think so. Lots of software products that support "undo" support undoing across a greater many actions than git provides, and yet they are able to perform the undo just fine; they don't need a special "undo --paint" and "undo --move-object" and "undo --reset-to-default".
There's literally nothing special about what git does that can't be covered by a general "undo" command which looks at the last git command executed in the local repository and maps that specific intention to an action.
When this is not possible (in the middle of a rebase, for example), simply tell the user (as git currently does) that $ACTION is not possible while performing a rebase.
This can all be figured out. The only real requirements are careful discipline and a commitment to getting the user experience right.
Having an undo command is likely the most leveraged thing by far the git developers can do to make new users unafraid of it. Screw up somehow? Just undo.
* if we call git undo, checkout the hidden branch, otherwise delete it
In practice, I think a lot of people call `git lg` often enough that they can just git reset --hard to a recent commit hash, or they manually create a just-in-case branch if they're going to do something risky/dangerous.
Look at the last repository-altering operation you ran and reverse the effects of it. Add a --dry-run to see what it would do, and print out the command it runs as a way to teach people more advanced things about Git.
I don’t recommend git pull to anyone. The magical ways that .git/config sets up tracked vs untracked branches are too opaque for me.
It’s always been much easier to understand (and explain) what’s going on when you separate fetch from rebase/merge*, and I feel like all these “just re clone and start again” memes are all because people’s branch tracking broke and they wanted magical “git push # no further args” to work properly again.
Once you know how to “git push remote myref:theirref” you become much less dependent on magic. Knowing about / having to know about how it works internally is the fun / tedium of git.
*Just kidding about doing git merge, btw. Linear history for life!
Fetch means “safely fetch new data from one of your remotes without affecting any of your local work”.
Pull means “do what fetch does, but with the spicy bonus risk that your precious work will be modified in an unexpected way depending on when and how you checked out the branch you’re on, what version of git you are using, and what config options you have set.”
Most confusion I've ever seen from beginners comes from them trying to pull, ending up in a conflict and not realizing, not resolving it but not aborting either and just continuing their work and then getting confused when trying to do anything else.
That's true. I think the worst thing about git CLI is it hides the state and forces you to issue another command to query the state, but you could easily forget. A lot of people add the thing to the PS1 to show some state, but it's not default.
However, I'm still not sure git will actually fuck things up with a pull. I think that's the users later when they go nuclear and delete the repo.
> Pull means “do what fetch does, but with the spicy bonus risk that your precious work will be modified in an unexpected way depending on when and how you checked out the branch you’re on, what version of git you are using, and what config options you have set.”
That's going to happen anyway when you need to rebase/merge. May as well type one command (pull), deal with the conflicts and continue, rather than type command, type another command, deal with the conflicts and continue.
Unless you have some other strategy that does not include rebasing or merging upstream changes, there's no advantage to not pulling. And, TBH, if you workflow is "this branch is worked on while specifically ignoring other changes by other people", then you have bigger problems than version control.
> Unless you have some other strategy that does not include rebasing or merging upstream changes, there's no advantage to not pulling.
Of course there is: after fetching you can see if there are differences between upstream and local, you can inspect those difference, and you can decide how to reconcile the two.
“Pull” is a big hammer which unconditionally performs an integration operation, and the default integration is one you almost never want too.
There‘a no advantage to pulling IME, in the best car scenario it’s just an alias for “git fetch && git merge”, if that’s what you want you can just do that and create your own alias.
> Of course there is: after fetching you can see if there are differences between upstream and local, you can inspect those difference, and you can decide how to reconcile the two.
[FWIW, it seems you know more about this than I do, so don't think that I am purposefully trying to be annoying. I'm not, I hope :-)]
I agree that you can see the differences, but I'm asking how helpful is this.
For me, anyway (not an advanced git user) seeing the differences between master and my feature branch before doing the rebase makes no difference - I'm still going to do the rebase no matter what I see in the feature branch.
It is going to be rare for me to be able to see, of the 10 merges to master, if an of them are going to break the code in a way that I cannot continue (in which case I won't rebase).
The longer I put off rebasing, the harder it is going to be to do it, so I am highly motivated to rebase on whatever master has, even if it just got broken, because it will be more painful to rebase later.
One big benefit to fetch+rebase over pull is that you can create a backup branch before you rebase so that if you mess up the rebase too much, you can undo easily.
Another situation I've run into is that sometimes I've made a small change that's stacked on top of a lot of other branches. And if those other branches get squashed and merged, regular rebasing can be really annoying - it is often easier to cherry-pick (I use rebase --onto, but same idea) your changes onto main/master instead.
> If you mess up a rebase you can always rebase -—abort (/ use the reflog) to restore the pre-rebase state.
That is true. But a few times, I've finished rebasing and regretted how I handled conflicts. And once the rebase is complete, you can't abort any more.
And I haven't put in the time to learn how to use reflog. Maybe this is my sign to do so.
As in `git fetch ...; git reset --hard ...;`? I guess that is what people are trying to achieve a lot of the time... For some reason people are more scared of `reset` than `pull`, though.
>Fetch updates your local repository (which is behind the scenes, separate from your literal local files).
Therein lies the chief problem with git: it's a leaky abstraction. Nobody actually should give a flying shit about commit hashes and ^HEAD or whatever it's called.
All the newbie tutorials you find waste so much time on that, but what people really care about when they start using git is "what the fuck happened to my files and how do I get them back the way they were".
Git docs and tutorials are breathtakingly bad at showing this.
git pull with fast-forward (--ff-only) is the only sane way to use git pull (if one must use git pull).
The most powerful one most people don’t use is reset. Soft and hard resets are my bread and butter. I don’t even bother with interactive rebases for squashing. I do a soft reset against origin/<branch> and create a new commit.
Yes I agree. Have you ever seen the "command line instructions" GitHub prints at the bottom of pull requests to checkout the PR code?! I don't think you'd approve of them. I'm pretty expert at git having used it every day for the last 15 years or whatever and I have no idea how to do anything after following GitHub's instructions!
To do it sanely you need to add the contributors remote, and fetch, and checkout, as usual. Would be happy to be educated here if I'm missing something.
Honestly the picture shown in that thread are fine and most people I have met grok those commands really quick.
The issue is git's interface is terrible and very powerful. Which means when something goes awry and they land outside those 5 or 6 commands they often have no idea how to fix it. Which invariably leads to a copy paste of their changes and a delete and re-clone.
Honestly I really like mercurial. I found its interface better but in this day and age all the tooling is built around git so ...
> ..when something goes awry and they land outside those 5 or 6 commands..
Yes, this. I have no problem adding, rm-ing, branching, making and accepting PRs, etc. These are what the overwhelming majority of git for dummies tutorials cover. (I've even paid for a very well-known and well-reviewed course and completed it.) And, these photos upthread are fantastic for that initial git-101 progression.
Then, I eventually landed my first tech-sector job and still haven't picked up much more since. My solution to every ounce of apprehension is deleting and re-cloning out of paralysis and fear.
I find great difficulty in being able to glean a repository's "environment" in a sense analogous to gleaning the environment of an initially compromised machine (the foothold) when you've popped a fresh shell on a boot2root box. (I thank the digital gods for IppSec and his hands-on videos that teach you how to clear up the fog of war around you!)
> My solution to every ounce of apprehension is deleting and re-cloning out of paralysis and fear.
Having worked with older version control systems, I found that to be one of the best things about git. If I had a problem with a version control system like AccuRev, that sort of simple fix was not possible. Your every action resulted in a change of the server state, so if you got your workspace into a confusing state, the confusion would be synced to every machine.
These days I understand git well enough that I can fix just about any mistake, but the 'delete and start over' workflow was extremely valuable to me as a beginner. Knowing that there was a foolproof fallback of just deleting and recloning let me experiment without fear.
The other day Jujutsu featured on HN, with git as a possible back-end. Describing itself as "both simple and powerful" with a combination of practices adopted from multiple tools:
> Jujutsu is a Git-compatible DVCS. It combines features from Git (data model, speed), Mercurial (anonymous branching, simple CLI free from "the index", revsets, powerful history-rewriting), and Pijul/Darcs (first-class conflicts), with features not found in most of them (working-copy-as-a-commit, undo functionality, automatic rebase, safe replication via rsync, Dropbox, or distributed file system).
> The issue is git's interface is terrible and very powerful.
Git is basically that a programming language. The time you need to "master" git is comparable to "master" a programming language.
I'm being writing code for more than half of my lifetime so far, and every time I need to use an unusual git command I feel like a script kiddo who copies and pastes from SO.
Though, if you know enough to edit diffs by hand, you could use git apply --cached to stage parts of the diff in a way to make a sensible set of commits instead of a single commit for a large change.
As someone who's having a very difficult time coming to grips with git, would really appreciate another source for this. It does not load for me, in the eight ways I have tried to load it (two devices each on a different IP, on two browsers, with that %2F left encoded and attempted with it unencoded.)
I'm probably showing my ignorance of what is possible/required, but I'd like to see a GUI front-end for Git that looked like the background of this image, where each commit was a lozenge that I could just drag from one column to the other. Maybe individual files could be circles inside the lozenges.
Just drag-and-drop, and the front-end figures out all the underlying Git commands to use.
I think this is a good guide. Git tends to be an emotional topic for a lot of people - myself included - and the hill I dramatically die on time and time again is that I think, tragically, this is about where developers stop learning git. I think operations like rebase, cherrypick, and squash are just as important as some of the ones you first encounter. Especially when you're working with other people. I use them every day and I see some of the spaghetti experienced developers pile on the graph because they only know merge. I guess my point is "don't sleep on rebasing" :)
Git is one of those tools that exposes so much of the underlying infrastructure that people just can't help diving in and making their own lives so much more difficult.
After using git for well over a decade, I'm completely convinced that if you find yourself frequently rebasing/cherry-picking/reflogging you're using git wrong.
rebase and cherry picking are both cornerstones of trunk based development workflows, and those have proven to be extremely successful in my experience, vs other methods (like Git Flow, the GitHub overly simplistic branch per feature and merge approach, which feels like trunk based but isn't etc.)
rebase makes roll backs extremely easy if you need to roll back specific commits because of bugs and makes releases easier via cherry picking (so you don't slow down trunk merges just to do a release) and allow for fine grained continuous deployment that is harder to achieve than without it.
It is my experience however, that either everyone needs to rebase or you end up with issues eventually when only some developers are and other ones aren't.
I don't care as much for squashing myself as a general case, as you lose fine grained per commit rollback strategies though
Blindly squashing every branch into one commit is lame and done by people who have either never had to bisect a bug or too lazy to figure out how to properly rebase. Where squashing is important is turning a work in progress branch into a series of commits for the master branch. There shouldn't be any commits fixing your own shit, for example. I don't want to see one commit where you do the work then five commits fixing your own work. Nobody needs to see that. It only makes things worse.
> It is my experience however, that either everyone needs to rebase or you end up with issues eventually when only some developers are and other ones aren't.
The only time I merge is when I'm working on a shared remote branch. I haven't found a workflow (although I'm all ears if you have any suggestions).
2. upstream has new revisions? rebase my branch on top
3. if not finished with my task yet, go to 1
4. if ready for review, open PR
5. if accepted, squash and merge
6. if changes are requested, write more code
7. upstream got more commits causing a conflict? don't rebase! it will screw up the PR history on GitHub and can cause issues for reviewers who might've checked out your branch locally and maybe done some experiments. merge upstream into your local branch. then you can push fast-forwardable commits.
8. push new commits to PR and go to 5
I used to think of rebasing as just rewriting commit history. But now I also think of it as altering the history of collaboration that is captured in a PR. So I switched from rebasing onto new upstream base branch commits and force pushing to PRs that already had reviews, to merging in new upstream base branch changes. I only do this after someone else has done anything on my PR; if I open it but nobody has reviewed yet, I'll do the rebase/forcepush to keep it current until someone does.
I prefer squashing to merge because I prefer the default branch to have one commit per unit of collaborative work. The way different people split up commits on a branch is arbitrary and varies widely; you'll never get more than 2 engineers to agree on a convention here. Keep all the messy stuff in the PR, and you can always revert one of those individual commits if you want finer-grained rollback. If you want a PR to have generated more than one commit, then it should be more than one PR.
> I only do this after someone else has done anything on my PR; if I open it but nobody has reviewed yet, I'll do the rebase/forcepush to keep it current until someone does.
I believe the only reason to do so is GitHub's lackluster PR UI. Force-pushing with an updated version of a branch after a review works reasonably well with GitLab's MRs.
> I prefer squashing to merge because I prefer the default branch to have one commit per unit of collaborative work.
There's no reason to squash when you can create merge commits from fast-forwardable state instead (again, one of the easily achievable options in GitLab's UI; GitHub doesn't make it easy AFAIK). This way you don't lose commit granularity while you can still obtain the "one commit per unit of work" view with simple `git log --first-parent` (or do the opposite and skip the merge commits with `git log --no-merges`).
> Force-pushing with an updated version of a branch after a review works reasonably well with GitLab's MRs.
The problem I run into is that other people have different workflows.
If they `git checkout remote/branch`, then everything's fine. But if they want to make a local copy of the branch, it'll get all messed up if I force-push. And I only want to adopt practices that are as robust as possible in the face of the possible ways other people could work.
For me, individual feature branches feel private, even if they’ve been pushed to a hub repository for others to view and pull. I wouldn’t push to someone else’s branch and I frequently force push to my own branch without worrying what it will do to others repositories.
The only thing that is sacred is the main/master branch. Everything is else just a speculative idea that, until reviewed and applied to master, is ephemeral.
(I’ve tried collaborating on a branch before but at the end of the process it’s hard to review because you either feel like the other party is rubber stamping their own code alongside yours, or you need to find a third party reviewer which spoils the 1:1 nature of almost every other code review I do.)
> (I’ve tried collaborating on a branch before but at the end of the process it’s hard to review because you either feel like the other party is rubber stamping their own code alongside yours, or you need to find a third party reviewer which spoils the 1:1 nature of almost every other code review I do.)
In my experience, that's part of the negative side of pair programming as well, although I really like it in general.
It's literally just a matter of a single command line argument to switch between views of whole MRs and individual commits, and both those views can be incredibly useful (especially during bisection).
I still haven’t tried your suggestion, but would it be able to show only merge commits from PRs already merged into main, while still showing all commits on my local work branches I have in progress?
`git log --first-parent` shows you only the list of commits accessible from HEAD by traversing their first parents. So, yes - your local work will usually have commits with just a single parent, so nothing will get skipped until it gets to merge commits.
It's also useful to skip noise if you happen to merge the upstream branch back into your topic branch for some reason.
Also, there's always `git log main..`, or even `git log main..topicbranch`. Combined with `--oneline` and perhaps `--graph`, `git log` is a really powerful tool to visualize repository state (and something that's incredibly lobotomized on popular Web frontends, unfortunately - I often end up cloning a repo to browse its history just because the Web UI is useless).
> This way you don't lose commit granularity while you can still obtain the "one commit per unit of work" view with simple `git log --first-parent` (or do the opposite and skip the merge commits with `git log --no-merges`).
My workflow is almost identical to yours except step #2. Why rebase on main when you can just merge from main? It's much simpler, less likely to get hairy merge conflicts. If you're going to squash your PR anyway, the end result is identical.
I really don't get all these people who insist on usingrebase instead of merge. Who wants to spend time resolving meaningless conflicts?! Every time I try it, I instantly regret it.
I like being able to see the graph with my commits lined up on top of the latest main revision. It helps me order my work in my head. There’s probably a bunch of other ways to visualize that, I just haven’t learned them yet.
I agree that if you're having to use the reflog frequently, you're using git wrong (not least of which because the reflog is not designed for readability and understanding the context where it came from).
But for the rest? If you're working in a repo with more than 5 people, rebase, cherry-pick, and squash are necessary to keep your sanity. Merge nodes are awful once you get beyond more than maybe 3 developers.
Someone else pointed out that it's probably confusing that I didn't mention that I do religiously squash my branches before committing, so we still have multiple developers with a clean main branch and no merge commits.
If you’re doing collaborative trunk based development then you’re only cherry-picking. So far Dave Farley is the only person I’ve ever heard advocate for this but it does have its place in the universe. Cherry picking is not destructive to history fwiw.
There’s absolutely nothing wrong with rebasing/squashing/amending/resetting heads on personal feature branches. In fact, it’s a pretty good practice if you make messy history and can make PRs less of an eyesore. I think the confusion comes up about when destructive history operations are appropriate because the git cli client does not have a concept of protected (shared) branches vs feature branches.
As long as you keep history destructive operations away from shared branches, you’re good.
In some cases, you're still good even when rewriting shared branches.
At work we're maintaining a downstream Linux tree with a few hundred patches on top of mainline. The tree gets frequently rebased on top of new upstream releases, and some changes are being progressively upstreamed. It's much easier to reason about the remaining downstream changes and deal with conflicts when rebasing than when merging upstream releases back into the downstream tree. Of course you can't expect to be able to carelessly `git pull` in such workflow, but if you're working with people who actually know how to use git it's not really a big deal.
Naturally, this particular project uses a special workflow that fits its needs. It doesn't usually make sense to rewrite shared branches in projects where you're the upstream.
> If you’re doing collaborative trunk based development then you’re only cherry-picking.
All my work is collaborative trunk based development, and I never cherry-pick.
> There’s absolutely nothing wrong with rebasing/squashing/amending/resetting heads on personal feature branches.
I agree that there's nothing _wrong_ with it, just that it's unnecessary. If your branches are focused on a single feature and you're always squashing your PRs to main, the cleanliness of the branch while you're working on it is unimportant.
> always squashing your PRs to main, the cleanliness of the branch while you're working on it is unimportant.
I'm personally not a fan of always squashing, for large features you lose a lot of history. I like a merge commit in some cases, you can still undo everything easily and most git commands support --first-parent so you can "pretend" everything was squashed in certain cases. But when you're got blaming, you have a lot more context to go off.
My branches are always focused on a single atomic change†, so if I want the tip of my branch to be up-to-date with main (or the dev branch or whatever), merging from that branch accomplishes the same thing with a lower likelihood of conflicts.
I always squash‡ before pushing a PR, so the end result is identical to a carefully rebased PR.
† occasionally branches will need to be split into separate commits, but that's not my default working style
‡ I know `squash` is a rebase under the hood, but it won't ever result in conflicts, so I'm happy to use it with every PR
I think you'd get a lot less pushback if you mentioned that you squash every branch before merging in your original comment. That actually seems like a pretty good policy if you can keep your branches relatively small.
Rebase is pretty much just an automation for cherry-picking and squashing, and interactive rebase is the primary and most convenient way to put the branch you have worked on into shape before presenting it to someone else.
When I hear about people not using rebase in their daily workflow, I imagine myself 10 years ago when I barely knew git and couldn't really use it as a helpful tool like I do today. It's almost like looking back to before I started using VCS in the first place - somehow I did manage to not use one for years (even collaborated via FTP!), but now it seems impossible. Usually most of the useful magic with git happens before anything gets pushed out, and `git rebase` has a huge part in it.
Use the interactive rebase. It shows a list of commits which you can reorder, squash, remove or edit.
Reordering is pretty powerful. If you made a mistake, commit the fix, then move it to the commit where you introduced the mistake, and squash. Removing broken commits makes `bisect` nicer to use when you're desperate enough to use it.
Obviously don't do this on commits you've already published.
> I'm completely convinced that if you find yourself frequently [cherry-picking] you're using git wrong.
A previous employer had a multi-tenant application that was deployed as a client-specific application which loaded the "core" as a dependency. They didn't really know how to do versioning and most version changes were just arbitrary "I feel like we should call it 1.8 now".
At one point I ended up maintaining a client-specific branch of the core dependency on version 1.10 (branch was 1.10-$CLIENT) while the "main" branch was 2.3 or something. For context, it went 1.10 to 2.0 because general cognitive dissonance.
This meant any change that needed to be made in the application core for this particular client also needed to be cherry-picked in some direction, usually by making the change on the client branch and cherry-picking it back as necessary. In some cases another client -- naturally, they would be on a separate branch like 2.3-$CLIENT -- also wanted that change so it needed to be cherry-picked again to that branch.
The result was a minimum of two PRs, one a cherry-pick of the others' commits (one commit unless I felt like spending my time in self-loathing), that I would make for every change. Not knocking cherry-pick at all; it's wonderfully useful when used correctly. That's just the result of non-technical decision-makers making decisions about technical tools.
On the plus side, I learned a ton about git in that job.
Resolving rebase conflicts is technically and conceptually much more difficult than resolving merge conflicts, with the added bonus that rebasing can sometimes force you to resolve conflicts for each commit in your branch.
Here's how I think everyone should use git:
1. Create a new branch for your changes
2. Make commits and merge from main with wild abandon
3. One final merge from main
4. Squash everything into a single commit, push a PR
If you keep your branch focused on only a single change, the end result is a tight, focused, single commit PR that merges cleanly into main and didn't involve any complex or error-prone shenanigans.
> Resolving rebase conflicts is technically and conceptually much more difficult than resolving merge conflicts
The opposite is true: resolving a conflict during a rebase is much easier, as you get to resolve the conflict in the context of a single commit and its parent. In some cases it may end up being more work than resolving a whole merge, but it's much easier to reason about.
This is a very common workflow for larger OS projects, and I think it translates really well to corporate environments too. It reinforces some work/feature discipline and gives you a nice clean history.
So, I get the "squash your feature branch into a single commit before merging upstream", but what does doing "git merge main" instead of "git rebase -i main" give you? (Assume I have my global git config to remember conflict resolutions via rerere)
I'm a big fan of that practice but I get the impression that rebasing scares a lot of devs that either didn't take the time to learn git or are still recovering from that one time that their change got too far away from mainline. That latter reason is why I prefer the practice actually...
I can’t imagine using VC for exploratory programming without rebase or something equivalent. I don’t want to bother writing a meaningful commit message for a change I’m probably going to throw away. I also don’t want to push a history like “WIP, WIP, works now, broke again, WIP” and that’s what it looks like at a first pass when I’m moving quickly.
Instead I squash away the garbage and push out a reasonable looking chain of commits with nice descriptions.
> I'm completely convinced that if you find yourself frequently rebasing/cherry-picking/reflogging you're using git wrong.
A lot of people want to use git as a checkpoint/backup system, and commits and associated changes reflect that. The rebasing/cherry-picking/reflogging is one way to update the set of commits on the branch in order to make a set of meaningful commits for the feature branch they're working on.
I've been using Git for the same length of time, but I have not reached this conclusion. That's the problem with teaching someone how to use a very powerful flexible tool that accommodates a variety of workflows and styles: different people use it differently.
As long as you never ever cherry-pick from one branch to another when the source branch is intended to eventually be actually merged (directly or indirectly) into the destination branch I think it has its use cases.
If you break this rule you could be in for dealing with some atrocious merge conflicts though, so I try not to do it unless the branch I'm cherry picking from is a definite actual dead end (e.g. the change was an urgent hotfix against an old release branch and your workflow doesn't involve merging those back into main/master).
Is that really an issue? When you rebase, git automatically figures out that you've cherry-picked something and will skip it.
I will occasionally chery-pick something from master, do my work etc. Before making my PR, I'll rebase against master and potentially squash/reorganize my commits. When the PR eventually gets merged to master there aren't any problems.
I don't think I ever merge without rebasing though, so maybe rebase has been saving me from any potential problems.
Yeah I very rarely rebase, just autosquash PR commits into one on merge to master (and also delete the source branch to avoid similar headaches) + making sure PRs are fairly small and focused. Regular merges where commits have been cherry picked from one side to another, and then later also unmerged changes have touched those same files tend to result in a lot of spurious merge conflicts.
Fun fact, when I worked at Red Hat for many years on the Opensource.com project, we created a collection of dozens of great articles on the ins and outs of git, written by open source community members. You can still find most of those articles here:
Unfortunately, the team who ran site got caught up in Red Hat's layoffs earlier this year and the site has been sitting in limbo ever since, so I don't know what will happen to it long term.
ArchiveTeam saved the entire site to archive.org using ArchiveBot, except for the downloads, since those were loginwalled. If you are able to contact whoever still has access, it would be great to be able to save the downloads too. It looks like the team or someone from it are planning on continuing the site though?
I've been working a bit the past week on a guide for a workshop I'll be running in a few months to get research mathematicians productive using just GitHub's UI. [0] So the purpose is not identical by any means. But I'm curious whether it's appropriate that this RedHat guide seems to go straight into "what commands do I run" rather than answering/illustrating "how does Git model the history of a software project's files".
The #1 mistake in trying to teach people Git is jumping right to commands without developing a mental model first. It leads to nothing but confusion down the line, and reliance on copy/paste of snippets and scripts to get anything done. Effective usage of Git depends heavily on having a basic understanding of how it works, moreso than a lot of other tools.
Mental models are famously quasi-impossible to transfer. Almost nobody really groks new concepts with theoretical explanations, practical experience is needed almost immediately
Of course; but if you only get practical experience with no theoretical explanations, you're almost sure to develop a mental model that's going to cause you troubles later on.
Definitely a mistake, though you can explain Git's data model in about 2 minutes.
I would say a bigger mistake is starting with the command line. A good GUI is absolutely instrumental to understanding Git, and it lets you avoid Git's terrible CLI for as long as possible.
1. the git commands map so cleanly to the states
2. there are so many terrible GUI interfaces that try and coddle the developer, really hiding the intent
I think the real problem is the flexibility allows for a lot of totally unintended but "legal" actions, from which it is really hard to recover because it's not your standard workflow.
Yeah I definitely agree on the proliferation of terrible GUIs. As someone else said, pick a good one when teaching.
> the git commands map so cleanly to the states
They absolutely don't. Someone already mentioned the mess of "checkout" and "reset" but that's only half the issue. The naming is a huge issue with learning.
The worst is the "index" which is apparently named after the data structure used to store it. Such a bad name that it's often called the "staging area" instead. But even that is bad. Why isn't it just called the "draft commit"? That immediately tells you what it is.
Another example is reset's soft/mixed/hard. Terrible meaningless names. They might as well have been called 1, 2 and 3.
And there's more! It's not just the mapping and the naming. The actual CLI is stupidly inconsistent too. Flags have wildly different meanings depending on the command. You do the same action in totally different ways depending on insignificant differences (e.g. git reset --hard Vs git branch -f).
I have to look up the command to delete a remote branch every single time I use it because it's just so unintuitive.
I think people love the Git data model (which is great) sooo much that they think they love all of Git.
I disagree. "checkout" does literally 2 unrelated things, one of them destructive with no safety checks. "reset" kind of moves HEAD around, but does a bunch of other stuff in the process. "Rebase" has a lot of magical (albeit useful) behavior involved in determining what exactly gets rebased. Etc.
> there are so many terrible GUI interfaces that try and coddle the developer, really hiding the intent
I agree. The CLI is confusing and occasionally obfuscates the data model, so adding yet another confusing obfuscating layer isn't going to really help. That said, a really good GUI that doesn't try to hide what's going on, would be a useful learning aid.
> A good GUI is absolutely instrumental to understanding Git, and it lets you avoid Git's terrible CLI for as long as possible.
Depends on the user.
If they are already an active user of the Terminal, they should be able to learn the git cli without ever touching a GUI.
The git cli has some warts for sure, and some weird inconsistencies. But with a bit of practice and some good documents about the correct mental model to have, you get used to it and you learn to use it very effectively.
Interesting about starting with the GUI. I can see it being useful in a controlled learning environment where you start with the GUI and gradually transition to the CLI. But if you stay on the GUI too long the student might suffer because they eventually will need to use the CLI, or at least understand its vocabulary, in order to read the documentation and get help from other people.
You should almost certainly talk about the way the history is stored. Both because it is essential to understand how git works, but also, if you drop in some of the mathematics that git uses, the mathematicians will enjoy it more.
> It will be good if someone can suggest the git
commands for that.
> I tried creating diffs from the tagged commits, but those
are a bit messy too. I'll not try to fix more, unless someone can tell
me the git commands that will make something better.
Consider that even the creator of Vim, a text editor so esoteric that the running joke is that no one even knows how to exit it at first, was repeatedly asking for help with Git commands. Let that sink in.
This guide would benefit from some visuals. That is, what is happening, and why. Else, for beginners, just listing commands is too abstract. It would also help to elaborate a bit on why, or at least walk though a merge conflict, 'cause ultimately, that's what beginners need to be aware of. That is, Dev A made changes a file and Dev B also made changes to that file. Boom! But this is why we use Git.
I've been using GitKraken which is paid (@ a fair $60 p/y). But I also see FOSS options mentioned on HN from time to time and intend to explore one of those. Perhaps I'll do an Ask HN later today?
I have contradictory feelings regarding git. For more than ten years, I was using it daily without really understanding the internals... and I was often confused and frustrated. After investing some time learning how the Directed Acyclic Graph works, suddenly everything made much more sense.
And, yes: it is good to learn the underlying fundamentals of the technology we are using. But, on the other hand, it denotes a rather poor abstraction from the UX point of view, imho.
Now, when I deliver git training, I start by explaining the DAG and how there is no magic, only git. By the way, the notes and exercises of the course are in my GitHub account[1], feel free to check it out if you think it can be useful.
Unfortunately knowing DAG's inside out will not save anyone who decides to open man git and related pages. Git is not magic. It's just the dictionary example of what you get when software developers start coding without adult supervision. Lots of cool stuff, but usability and user-friendliness is not one them.
I only partially agree. Git is a complex project, developed to help with the management of the Linux kernel source code. Because of that, the original audience was technically very advanced and maybe didn't need any higher layer of abstraction, nor a proper product development roadmap.
The problem appeared when people like I started basing our workflow on it ^_^. There are a few good books[1] and tutorials[2] out there, but I totally agree that the official documentation is only useful as a technical reference.
> It's just the dictionary example of what you get when software developers start coding without adult supervision.
git was originally explicitly a VCS core for anyone to build on. Remember the "plumbing vs porcelain" days? I do.
And after 18 years what have the "adults" done in the meantime? Come at them sideways for having the gall to release an unrefined tool that got popular?
For almost all (99.999999%) intents and purposes git consists of the following commands: pull, push, merge, commit. If you are the mythical 10x developer, the add rebase and submodule to the list. Everything else is just fluff. If you use anything else, it ends only in 2 hours of agonizing googling, with shaking hands before each new commands you run trying to undo whatever arcane stuff you just did.
The core of git is cool. Few simple commands, easy to use. The remaining stuff is something only a mother could love.
My dream is that someday we’ll all use a VCS that is so simple the internet doesn’t have literally tens of thousands of blog posts pretending it’s simple. Someday…
Yeah. Maybe I'm making excuses, but tools should be easy to use and get out of the way - they're not what we're being paid for. People say 'knowing how to use your tools properly is part of your craft', but I feel Git is more like someone asked for a cabinet and instead we gave them a hammer, some nails, and some timber and said 'but this is so much better than just giving you a cabinet!'
I see it more like someone asked for a cabinet and hired you, the carpenter, to plane, route, chamfer, mitre, join, hammer, nail, screw and glue the wood into place.
You absolutely need to know the right tools and techniques, of which there are many. For instance, nails and screws are not interchangeable, and they're made with a variety of metals and coatings for specific applications.
Just about anyone can hammer a nail into a piece of wood. It is quite difficult to put together a high quality finished piece of woodwork. Same is true for software.
I can sort-of see your point, but (stretching the analogy way too far), imagine I'm the interior decorator and I'm asking for a cabinet among other things. My expertise is not in making the cabinet. Relating it back to being a software developer, my expertise is in the problem domain and the business logic.
I don't think Git is stupid or fundamentally wrong, just that the interface we're all using (even the GUI interfaces) are just thin veneers over the underlying API, which is confusing to many people, and that Git could be more productive for most developers when we have an abstraction that is easier to understand.
I've seen people much smarter than me fumbling around to solve problems with Git.
> Relating it back to being a software developer, my expertise is in the problem domain and the business logic.
That's your problem right there.
You're a craftsman. You have three sets of inputs: raw materials, designs and tools.
You've chosen to focus on raw materials and designs, and have decided that mastery of the tools (or some subset of the tools) is not important.
A cabinet maker who said "my expertise is in complex corner joinery and standalone rectangular forms" would be laughed at if they also added "i find japanese saws and routers problematic".
Yes, tools are tricky. Tools are hard. But tools are an equal part of the task triangle, and you owe it yourself to build up your own scaffolding of understanding for the tools as you do for the other components.
Sure, a source code repository is an essential tool. But if you have a company that has a room (or several rooms) full of developers that work on a product, the expertise (arguably, the whole raison d'être) of that company is in the things that only they do. The tools are necessary, but you don't want every developer to have to devote any more time than is necessary to learning/using a tool.
I'm not arguing against source control, I'm arguing against a tool that so complicated and is obviously so hard to master might work against us as much as it work for us.
I think it's because it is simple, but Git's terrible CLI makes it hard to learn. Once you've learnt it you can ignore all of the terrible interface and just think about the actual operations you want to do which are generally very simple.
I could explain Git's data model and what the operations do to my wife. I don't think I could actually teach her how to use the git command line though.
The core is simple. Misfeatures like the stage and the stash and submodules are not part of the simple core. The workflow where we have no good way to hide history besides destroying it is simple but also stupid, particularly when destroying history also destroys your ability to collaborate or even merge your own code cleanly.
Staging area and stash are simple too. Here I'll explain it in 10 seconds:
* The staging area/"index" is a draft commit. You can add or remove things to the draft. When you run `git commit` it turns the draft into a real commit and the draft becomes empty again.
* Stashes are just "WIP" commits. They don't have a branch name pointing to them but you can list them all. When you apply or pop (apply & delete) a stash it takes the diff from the stash commit (versus its parent) and applies it to your working tree.
Submodules conceptually are relatively simple but the actual implementation is stupidly buggy and confusing. Like, I still have no idea what "submodule init" does. Why are there two places where submodules are stored - `.gitmodules` and a second secret place that you can't see? Why isn't `--recursive` the default? Why doesn't switching branch also switch the submodules?
Most of the answers to that are "well it could work properly and be simple, but actually it's half-arsed and full of bugs". You can seriously break your repo with `git switch --recursive` or if you try to use work trees with submodules.
Yes but none of those things sound like they needed to be first-class built-in parts of git and instead could've been just plug-in tools built on top of git. Like stashes could just be a set of branches named stashes/<stash name>, with external scripts handling the stash/pop mechanic.
And given the choices in things that get first class support in git, "which branch was this commit originally made in" or "no you don't need to care about that intermediate commit" or "what commits were derived from this commit" or "what branch is this commit in" seems like they would've been more useful problems for the freeping creaturitis to solve.
So relatively simple that it took 12 years to even begin? Can you really blame people for using Git when it took them 9 years to even accept that Python performance was a problem?
It is easy to replace a "bad API". There are a million alternative CLIs and GUIs for git.
They haven't caught on because it turns out git's CLI isnt actually bad. It feels complex because it feels like what it is doing is simpler than is presented. But in fact it is solving quite a complicated distributed database program, transactionally, with editable history. The CLI hides a lot of that but cant hide it all. But you do need the flexibility.
Perforce is idiot proof. I can teach a non-programmer who has never even heard of revision control how to use Perforce in literally 10 minutes. They will never shoot themselves in the foot. They will never lose work. They will never, ever need to nuke and reclone their repo.
Perforce has other issues of course. But Git has both a bad CLI and a bad model. Maybe its particular model is strictly required for the Linux kernel. However for 99% of developers that are centralized on GitHub the model ranges from “mediocre fit” to “downright broken”.
>They will never shoot themselves in the foot. They will never lose work. They will never, ever need to nuke and reclone their repo.
You never need to do these things in git either. People only 'nuke and re-clone their repo' because they google something and get awful StackOverflow answers written by idiots that tell them to do that. It's not how you're meant to do things in git.
You're very unlikely to actually lose history in git unless you go out of your way to do so. I mean, you might not actually commit your changes, but I'd hardly call that 'losing work'. What's the alternative, autosaving into your history? No thanks. But once something's committed, it is hard to delete it. The reflog exists.
Another +1 for Perforce from me, it's just so much simpler for non dev users. It's of course a no-go if you really need the distributed nature of git, but as you say, for the majority of users that use GitHub/GitLab it's an option.
The philosophical difference I've found using both is that Perforce is file centric and git is commit centric. In perforce you have the file tree and then the history of each file, with git it's flipped. This is why I find it so hard in git to see how a particular file has evolved, with Perforce it's second nature. Perforce is so good at telling you why a particular line of code is there, I miss that so much in git.
Just curious about this because I’ve never had any direct experience. All of my uses of any version control (save very early work with RCS) has been to a central server.
But “distributed” must mean something other than that, especially how git is presented (i.e. technically there is no center).
So, do folks doing distributed development routinely push changes in a peer to peer fashion? Alice, Bob, and Charlene are collaborating with Alice and Bob working on one feature while Alice and Charlene work on another, pushing incremental changes to each other but only sending the completed feature/branch to their non-collaborating peers when they’re complete.
Does that happen often or is it just the “commit early, commit often to the local copy” that distributed devs are really using? “I can edit on a plane” scenarios.
>So, do folks doing distributed development routinely push changes in a peer to peer fashion? Alice, Bob, and Charlene are collaborating with Alice and Bob working on one feature while Alice and Charlene work on another, pushing incremental changes to each other but only sending the completed feature/branch to their non-collaborating peers when they’re complete.
Yes. The prototypical example is the Linux kernel, which is what git was originally created for. There, there are a large number of different trees. Linus's tree is 'standard' Linux, but there are the various stable trees, there are trees for various subsystems, there's the continuous integration tree 'linux-next', and others. Those trees' changes are all intended to eventually reach Linus's tree. But there are other trees which aren't, they host patchsets that sit on top of Linux "proper" but aren't intended to ever be upstreamed.
>Does that happen often or is it just the “commit early, commit often to the local copy” that distributed devs are really using? “I can edit on a plane” scenarios.
In practice, not many open source projects are big enough and distributed enough that they need to do what Linux does. This aspect of it is very useful too: that you can code on a plane, that you can code in the bath, that you can code in a shack in the woods, etc.
> This aspect of it is very useful too: that you can code on a plane, that you can code in the bath, that you can code in a shack in the woods, etc.
Even turbo-centralized Perforce supports offline mode. Distributed systems enable offline mode, but offline mode does not require a hyper distributed system!
git simply has a handful of commands that require network access, none of them a part of "day to day" development work, nor necessary to fully utilize git if your canonical repository is on your own machine.
my biggest problem with perforce (it's been years since i used it) was that it had a "checkout" model where it was necessary to do something before starting any code changes that you might want to commit later. i found that quite problematic, and reminiscent in some way of older systems like cvs. git manages to retain the sense of "the codebase is just a bunch of files" all the time, and that works better for me.
> For distributed development, it's a total non-starter.
Define distributed development. Do you mean like Linux with thousands of random contributors? Or do you mean a game team distributed across the globe? Or a AAAA team with big, scattered offices?
Perforce is not a good fit for Linux! It’s effectively the only game in town for almost all game devs.
> You can't solve the issues with perforce without making it no longer idiot proof.
I think I’d take that bet. Becoming idiot proof isn’t hard. The trick is for all commits to be automatically backed up in the central hub. And for commits to be locked and stable once made.
Git’s ability to re-write history is, imho, a huge mistake and I don’t think actually necessary to support Linux. Flattening on PR merge doesn’t require a rewrite.
>I think I’d take that bet. Becoming idiot proof isn’t hard. The trick is for all commits to be automatically backed up in the central hub.
That's the last thing I want. Random WIP commits being sent off to some central hub? Fuck that, man. Fuck that.
>And for commits to be locked and stable once made. Git’s ability to re-write history is, imho, a huge mistake and I don’t think actually necessary to support Linux. Flattening on PR merge doesn’t require a rewrite.
Being able to re-write history is absolutely necessary. I seriously doubt you've ever looked at a patch series posted for any free software project if you say that rewriting history isn't necessary.
To put it quite simply: my data is under my control. I can do whatever I want with it. I commit frequently because it is useful to be able to go back in history through changes as I make them. For the purpose of publication, it is not useful to see the various stages I went through when thinking about how to solve a problem. That's not what git history is for. It's for presenting a logical series of changes in a way that is easy to understand and bisect. Flattening on 'PR merge' is abysmal. I don't want one massive commit. I want a series of logical commits.
> That's the last thing I want. Random WIP commits being sent off to some central hub? Fuck that, man. Fuck that.
This is where you’re objectively wrong. I have this feature available to me today. It’s a killer feature. It’s amazing. Having it has zero downsides. Not having it is a pain in the ass and makes life worse.
Imagine this. You’re working at a company with thousands of engineers. Everyone is making stacks and stacks of local commits. At various points in time people push their commit(s) to code review. If approved it gets merged into master.
Now imagine if anyone could check out any commit from any employee just by typing “git checkout #####”. That’s it. That’s the feature. If you browse the repo it is perfectly clean. There’s no dirt or noise. This includes letting you checkout your own commit on one of your five different machines/platforms/cloud servers without having to push or pull or any of that shit. Commit on one machine and checkout on another. It’s pure automagic.
> Flattening on 'PR merge' is abysmal. I don't want one massive commit. I want a series of logical commits.
Sure fine. Shape the series of commits however you want. As few or as many as you want. With nice clean messages. The world is your oyster. But those are new commits. The initial commits should be, imho, unaltered (and unmerged). They can be GC’d months/years down the road if needed.
But in Perforce you can have your own private branch, in practice it feels not much different than having a local git one. You can then merge to main as you want.
How can it be that we are still using plain text files for editing code?
Wouldn't the grass be greener if a variable were stored as a unique key, making refactoring trivial? Wouldn't the birds sing louder if formatting were just a view on the underlying data? And wouldn't the sun shine really brightly if diffs were to operate directly on the abstract syntax tree?
I fear that this has to do with the great problem of interoperability, and of people not always wanting to work together. What would be a constructive way to coordinate ourselves out of this silliness?
We're in a very, very strong local maxima with plain text source code. In order for a rich-data source language to work you'd need to implement, competitively with what we have for text, the language itself (which is already a hard sell, look at how difficult it is for even phenomenal languages to gain a foothold) including built-in macro and codegen systems, a compiler, at least one fully-featured editor, complete with linting and code suggestion and search and an input mechanism competitive with just typing out text, possibly more than one to support the wide range of opinions about editors ranging from IDEs to Vim, source control integrated with means for sharing and collaborating on said code, and every other convenience you get for free from choosing plain text.
Basically, you need to sit down and build the greatest programming language ever conceived, complete with a world class ecosystem, and then convince people that this is truly a revolution software development, and you probably won't make a dime off it because proprietary programming languages are evil.
It's not about "not always wanting to work together".
It's about "i want to be able to pick the tools i use", which in turn means "the underlying data we operate on needs to use a format/storage mechanism that any reasonable candidate for a tool can use"
And the answer to that quandry is: plain text files.
You may be interested in difftastic for doing diffs based on the AST. One problem with this approach is that when you have a lot of changes (tens of lines, maybe hundreds), it gets slow.
The tool is great thou, and is my default diffing tool.
Not to mention that comments could point to bits of code without being in the code. We could show them to the user like tooltips (or like the sweet sweet balloon help from macOS Classic - how I miss it so much!)
Not a bad guide, but the Linux/Windows differentiation is a bit deceiving.
For example, 'git config --global user.name "username"' and 'git config --global user.email "useremail"' are required for Git users on any system before a commit is made, but since it follows the 'Git Configuration: Windows' title, it reads as if it's a Windows-specific configuration.
Additionally, $HOME/.gitconfig is also used by Linux (and UNIX and macOS) systems to store this configuration.
Teaching git by showing commands is like teaching how to write letters by showing LibreOffice Writer's toolbars. It only makes sense when you're moving from another similar DVCS that you already understand and know what you're operating on by using it.
This was a nice document. But could you expand what happens after step 4 of your last workflow if you get a conflict with the rebase? You say:
> and then tell git to continue attempting to apply your changes.
Sorry, I just don’t know what that means. Redo step 4? Does rebase fail on the first conflict? It seems that when you get a rebase conflict your in the middle of a process but dumped to the command line. It’s not clear how you move forward (I guess repeat step 4) but more importantly how do you go back to the start before you did step 4?
and get a conflict report. You fire up your preferred editor/IDE/whatever on the files that have conflicts, and you fix the conflicts, either by picking one of the versions (they will be marked sections delimited by <<<< and >>>>) or by manually merging the versions into a single new version. You save those files back to disk.
Then you run
git add ... list of files with conflicts that are now fixed ...
and then you run
git rebase continue
You may have to repeat this process multiple times before the rebase can complete.
On the topic of Git, I vaguely remember somebody mentioning that Google was looking at wrapping Git with something else to simplify it. Anybody remember what that project is?
There's "jj", which started as a Google employee's hobby project but they put him full time on it. Not sure how much G plans to push this, but they are endorsing it at least.
Unrelated to content of article but the fact that scrolling the article pushes sections onto the history stack (instead of replacing the top of the stack) is exceptionally rude. I should not have to hit back 10 times just because I skimmed through the subject headings.
A short explaination what remotes are and how to configure it would be helpfull. Otherwise, the "git push" command would fail and the tutorial gives no hint, why.
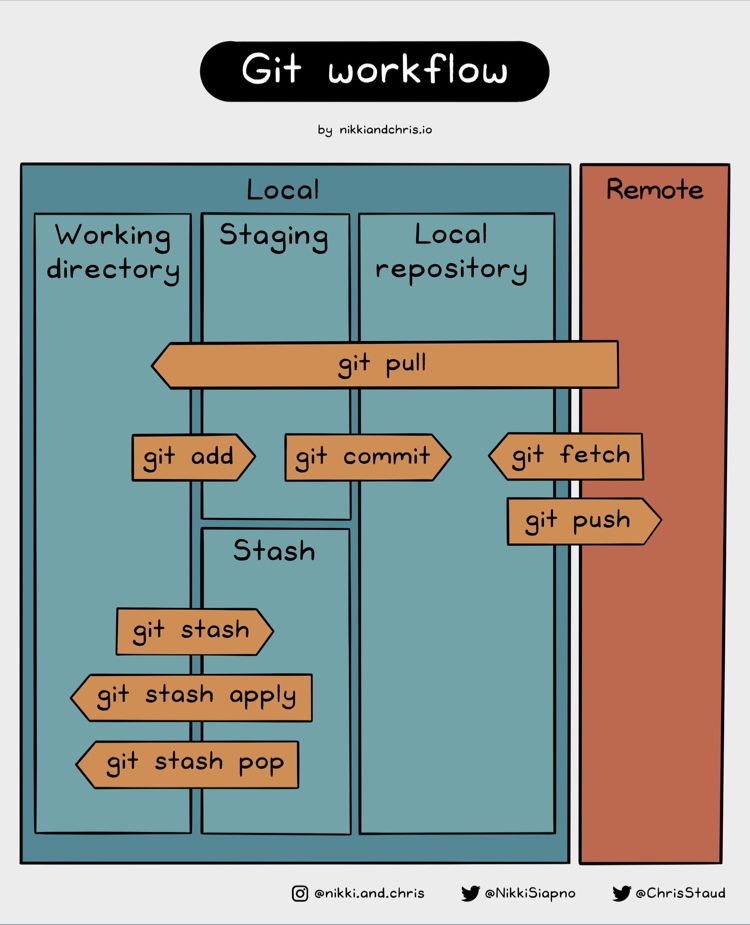{kind=link}
But after looking at other source control options, I find it to be an absolute joy to use -- even for very complex tasks. The VC problem itself is where the complexity lies. Any tool that deals with collaborative working on document will present the same issues that Git does. Maybe worse.
Be thankful that you can use any tool you want to create plain-text diffs; that git performs operations quickly; that resets, undo's, etc are possible; that the precise history (both of the actual state and the steps taken to get there) is entirely legible; that each command performs a single, well-defined, and well documented atomic operation; that the tool is extensible, command-line script-able, usable locally, free; that it keeps the size of a repository small; that it is scalable across any number of contributors working simultaneously.
Some, all, or none of these may be true with other tools.
Anyone ever had to do a diff of a Microsoft Visio document by hand? Anyone had to manually type in the name of a document and its revision by hand into a web form? Anyone ever spent an afternoon working on a document, only to realize that someone else already made the changes you made but forgot to update the filaname which caused their changes not to be visible to you? Programmers are spoiled with the best tools in version control. People in other domains are doing this, without even knowing that they are doing this. They are making commits, merging, rebasing, etc.. without even having a word to describe it.