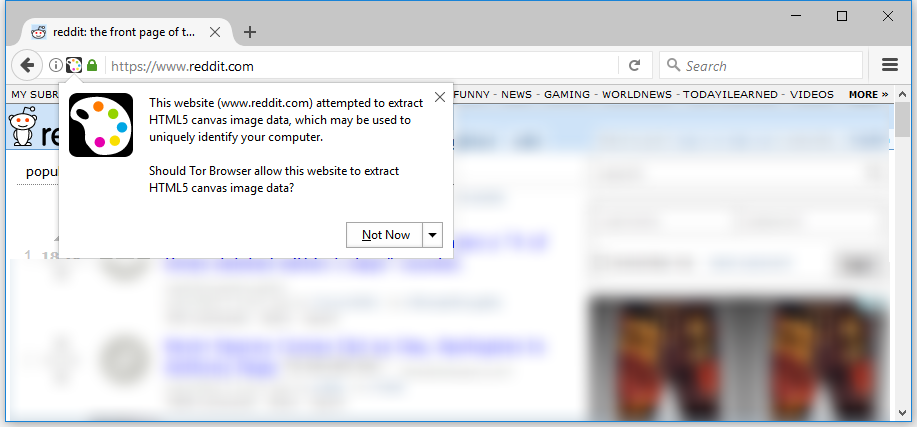
It is interesting, that while technologies like canvas, WebGL or WebRTC were intented for other purposes, their main usage became fingerprinting. For example, WebGL provides valuable information about GPU model and its drivers.
This shows how browser developers race to provide new features ignoring privacy impact.
I don't understand why features that allow fingerprinting (reading back canvas pixels or GPU buffers) are not hidden behind a permission.
It is absurd to claim that the main use of WebRTC is fingerprinting. Especially during the pandemic the world pretty much ran on WebRTC. Real-time media is clearly a pretty core functionality for the web to be a serious application platform, it wasn't just some kind of a trojan horse for tracking.
Now, it is true that a lot of older web APIs do expose too much fingerprinting surface. But the design sensibilities having changed a lot over time, it's just not the case that you can make statements about what browser developers do now based on what designs from a decade or two ago look like. These days privacy is a top issue when it comes to any new browser APIs.
But let's take your question at face value: why aren't thesespecific things behind a permission dialog? Because the permissions would be totally unactionable to a normal user. "This page wants to send you notifications" or "this page wants to use the microphone" is understandable. "This page wants to read pixels from a canvas" isn't. If you go the permission route, the options are to either a) teach users that they need to click through nonsensical permission dialogs, with all the obvious downsides; b) make the notifications so scare or the permissions so inaccessible that the features might as well not exist. And the latter would be bad! Because the legit use cases for e.g. reading from a canvas do exist; they're just pretty rare.
The Privacy Sandbox approach to this is to track and limit how much entropy a site is extracting via these kinds of side channels. So if you legit need to read canvas pixels, you'll have to give up on other features that could leak fingerprinting data. (I personally don't really believe in that approach will work, but it is at least principled. What I'd like to see instead is limiting the use of these APIs to situations where the site has a stable identifier for the user anyway. But that requires getting away from implementing auth with cookies as opaque blobs of data with unknown semantics, and moving to some kind of proper session support where the browsers understands the semantics of signed-in session, and it's made clear to users when they're signing in somewhere and where they're signed in right now. And then you can make a lot better tradeoffs with limiting the fingerprinting surface in the non-signed in cases.)
> "This page wants to send you notifications" or "this page wants to use the microphone" is understandable. "This page wants to read pixels from a canvas" isn't.
That specific wording may be a touch too verbose for the average end user, but it's not impossible nor is it strange. Just include a note about how this is 99% likely a fingerprinting measure; option b) isn't so bad in this case. Of course, due to the nature of how fingerprinting works, the absolute breadth of features that would be gated behind something like this would be offputting.
I am also wary of what you suggested with gating this kind of fingerprinting to when the website has positively identified the user anyway; in a way, this seems to me even more valuable than fingerprint data without an associated "strong" identity.
Giving users the permissions would simply be a training exercise in "I have to say 'yes' or TikTok breaks". Like how Android worked a few years ago with the other permissions.
Android largely works now with these permission prompts, though. TikTok asks you for a million permissions too, and many average end users decline. Many people also opt out of tracking on Facebook et al. when iOS prompts them about it.
The user ‘Joe average’ does not use Tor, does not even know it exists - Tor is used by a completely different segment (of people with ‘above average’ IT skills…)
Of course it's main use is fingerprinting. Do you think WebRTC is instantiated for genuine reasons the majority of the time? That's real absurdity.
WebRTC is instantiated most often by ad networks and anti-fraud services.
Same thing with Chrome's fundamentally insecure AudioContext tracking scheme (yes, it's a tracking scheme), which is used by trackers 99% of the time. It provides audio latency information which is highly unique (why?).
Given Chrome's stated mission of secure APIs and their actions of implementing leaky APIs with zeal, I have reason enough to question their motives.
After all, AudioContext is abused heavily on Google's ad networks. Google knows this.
> It provides audio latency information which is highly unique (why?).
As someone who has worked with WebAudio extensively, and have opened and read many issues in the bug tracker and read many of the proposals... this is just not as nefarious as you are making it seem. I don't disagree that this _can_ be abused by ad tracking networks but I do disagree with the premise that it was somehow an oversight of the spec or implementation which led to this (or even worse, intentional). Providing consistent audio behavior across a wide variety of platforms (Linux, OSX, Windows, Android) along with multiple versions of all those platforms and the myriad hardware in the actual devices is actually just pretty hard. The boring answer here is that to provide low latency audio to support things like games, a lot of decisions have to made about what buffer sizes are appropriate for the underlying hardware and this is what ultimately exposes some information about audio latency on the system. Some of those decisions are limited by the audio APIs of the OS. Some are limited by the capabilities of the hardware. Some are workaround for obscure bugs in either layer. The point is that, as with most software, compromises are made to support an API that people actually need or want to use to make stuff. I also don't think audio latency information is really "highly unique". There are only a handful of buffer sizes which are reasonable based on the desired sample rate and are mostly limited by the OS, meaning at best you can probably identify a persons OS via the AudioContext. Furthermore, I have seen API "improvements" and requests rejected outright due to possibly exposing fingerprinting information. Things that would be really useful to applications which are building audio-centric software won't be implemented because the team takes this issue seriously.
AudioContext latency information can be retrieved without the user's consent or knowledge on websites that never ever use audio. It's a security disaster. I know for a fact that AudioContext is routinely abused on ad networks and by anti-fraud solution providers. Given its widespread use for purposes it wasn't designed for (in fact, this information is used primarily for tracking and spying), it's safe to say it's a tracking scheme.
The fact Google directly and knowingly benefits financially is a smoking gun. They don't give a damn it's not a secure -- in fact they profit on the fact it's a leaky sieve.
You said AudioContext is sometimes used for purposes which benefit the user. Well isn't that swell, the user is maliciously tracked by this security exploit 99% of the time and gets to reap the "benefits" 1% of the time.
Do you mean more websites use webRTC for legitimate purposes than for fingerprinting? Or more instances of it being activated is legitimate or more traffic is legitimate (probs true given bandwidth needed for audio video).
But I suspect by the other two metrics it's correct to say most uses are to fingerprint.
The main reason is that it's really hard to avoid fingerprinting (while providing rich features like WebGL and WebRTC anyway).
A secondary reason is that web browsers started off from a position of leaking fingerprint data all over the place so there's not much incentive to care about it for new features.
(The real conspiracy is that Google added logins to Chrome specifically so that they don't have to rely on fingerprinting. They have a huge incentive to stop fingerprinting because it leaves them as the only entity that can track users.)
I thought the developer of the browser is the only ad provider that _doesn't_ need it (since they have other, better ways to get that intel which their competitors do not).
Also, it's very convenient in a work context if your employer uses G Suite/Workspace. I don't have anything to hide work-wise, and I do everything else in incognito windows.
The fly in the ointment with this theory is why Apple (or even Mozilla) would expose the same kind of information. Apple has only recently started experimenting with ads, and their ads are limited to the apps that they control.
The more benign explanation would be to allow developers to work around device-specific or browser-specific bugs.
(I'm aware Apple changes the GPU Model to "Apple GPU", however they do expose a ton of other properties that make it possible to fingerprint a device.)
Apple devices are in fact fairly difficult to fingerprint. In my experiments [1] all instances of the same hardware model (on iOS, iPadOS, and macOS) give the same fingerprint, so the best a tracker can get is "uses iPhone 14". Better than nothing, but not terribly unique.
They're not that big of a deal, but my two biggest annoyances with RFP:
1. prefers-color-scheme is completely broken, even in the dev tools. Mozilla refuses to fix this in any way, it is allegedly "by design" that you have to disable all RFP protection if you're a web dev and need to test the dark color scheme of your website.
2. Similarly, RFP always vends your timezone as UTC with no way to change.
that's a great way to get even more fingerprinting potential, each additional switch is another bit of identification on top of the actual fingerprint itself.
Continuing the push the browser to be a general app platform is the only way it can survive against native experience, which is already eating into the enthusiasm for the web. It seems like the trend for consumer companies is to maybe launch first on the web for velocity but eventually migrate to native experiences.
I wonder to what degree we can enable hardware performance without leaking user data.
> This shows how browser developers race to provide new features ignoring privacy impact.
I think it showed how many years ago browser vendors were naive with understanding how this tech could be misused.
These days I think browser vendors are very much aware of it and will frequently block features or proposals that they feel compromise on privacy and/or could be used as a tracking vector, especially Firefox and Safari. Sort this list https://mozilla.github.io/standards-positions/ by Mozilla Position to see the reason they reject/refuse to implement standards and proposals.
For those who are unaware of how big of a problem fingerprinting is, there is an EFF website [1]. EU cookie policy is nothing compared to this. There are libraries like fingerprintjs [2] which can generate a pretty stable visitor ID.
If you change or alter some browser APIs in order to make your browser less unique, some payment processors webs may stop working. And webs proxied through CloudFlare will constantly display "Checking if the site connection is secure" page, sometimes in an infinite loop where even solving their captchas won't help.
In most parts of the world, if a person is in a public space, anyone can take a photo of that person, including shop owners. This photo could be considered as a type of "fingerprint" for that person. The only important difference is that in some countries, you are not allowed make money off of such photos.
The Internet is a lot like a big public space, and possibly worse - while you are using certain services (web pages or apps), it might be argued that you are actually "on premises" for that service provider.
The best we can do now is more and more education about what can go wrong with such data collection.
Yes, but taking photos is expensive, fingerprinting online is cheap. Also, there's a difference between taking a photo of the eiffel tower and taking a photo of a bunch of other tourists there (legal), or intentionally targeting and photographing an individual and creating a database of those photos (illegal in most countries).
{kind=link}
This shows how browser developers race to provide new features ignoring privacy impact.
I don't understand why features that allow fingerprinting (reading back canvas pixels or GPU buffers) are not hidden behind a permission.