1) Transistors dissipate the most power when they are switching (this is because they transit their linear region). So the more they switch the more power they dissipate, thus the power dissipation of any transistor circuit is proportional to its switching frequency.
2) Silicon stops working reliably above 150 degrees C, this is due to thermal effects in the silicon overwhelming its electrical characteristics. One way to think about it is that at 150 degrees C the silicon lattice structure is vibrating so hard because of heat the electrons can't move anymore.
3) Lithography and manufacturing techniques have increased the number of transistors per square millimeter of silicon exponentially over the years so the number of transistors has been observed to double every 18 months or so.
4) The ability to channel heat from silicon to the outside air is limited by the thermal conductivity of silicon and the ceramics used to encase it.
So those four parameters create a 'box' which is sometimes called the 'design space.' If you build a chip that is inside the box it works, if one of the parameters goes outside the box it fails.
In the great Mhz race of 1998 clock rates were pushed up which caused heat dissipation to go up, and transistor counts were going up too, so you got an n^2 effect in terms of heat dissipation. The race was powered by consumers who used the single number to compare machines (spec wars). It was unsustainable.
The end of that war occurred when AMD introduced multi-core (two cpus for the price of one!) architectures. And Intel had the largest design failure in its history when it scrapped the entire Pentium 4 microarchitecture after realizing it would never get to, much less past 4Ghz as they had promised.
AMD proved that for user visible throughput, multiple cores could give you a better net gain than a faster CPU. This side stepped the n-squared problem by having twice the number of transistors but running at the same clock rate, so the heat only went up linearly rather than exponentially.
It was a pretty humbling moment for Intel.
That begat the 'core wars' where Intel and AMD have worked to give us more and more 'cores'. The heat problem was still there, but it was managed with transistor design since the frequencies were staying flat.
Recently, some new transistor designs and system micro-architectures, have combined with the inevitable flattening of performance gains from multiple cores (see Amdahl's law), to give us 'turbo-boost' type solutions, where only one core runs at higher speed (side stepping Amdahl) at the expense of down clocking or even turning off other cores (sidestepping the frequency component of power increases).
Another technology on the horizon (which used to be only for the military guys) is SoD or Silicon-on-Diamond. Diamond is a wonderful conductor of heat and so if you make your processor on a diamond subtrate you can pull lots of heat out into an attached cooling system. Get ready for 7" x 7" heat management assemblies though that attach to these things. Or alternatively a new ATX type form factor that includes something that looks like a power supply but is a chiller that attaches via tubes to the processor socket.
clock rates were pushed up which caused heat dissipation to go up, and transistor counts were going up too, so you got an n^2 effect in terms of heat dissipation
Back when Dennard scaling was in effect, transistor power decreased as density increased, keeping chip power under control. The root of the problem is the end of Dennard scaling.
AMD proved that for user visible throughput, multiple cores could give you a better net gain than a faster CPU.
I don't know if that's true. AMD's success in 2003-2005 was mostly with single-core processors; I think all AMD showed was that a well-designed core and memory system beats a bad one.
It wasn't the multiple cores that allowed AMD to steal market share from Intel. It was the original Athlon chips around the turn of the century. They were the first chips that ran at a lower clock speed but produced far superior benchmark numbers in just about any benchmark. Combine that with the much higher prices that Intel charged for inferior products and AMD had a great run until Intel ditched the Pentium 4 line.
The original Athlon was all about clock speed and the race past 1Ghz. The P4 quickly surpassed it, though, and left the Athlon competing on the basis of cost (P4s required RDRAM, which was much more expensive.) In the fall of 2001, the P4 hit 2Ghz and added DDR SDRAM support before the Athlon XP showed up at 1.5Ghz, and the Athlon XP was never really able to clearly beat Intel's fastest. It wasn't until the Athlon 64 that AMD was able to win across the board with significantly lower clock speeds.
No, point 1 means that 'active' power (which is the power the system dissipates when it is actively switching things) limits the maximum clock rate. Higher clock rate, more heat is generated, heat can't get out of the chip fast enough so chip temperature rises, transistors fail.
Leakage current, that is to say the current that flows through transistors because they cannot be fully turned 'off' is a sort of power 'floor.' If you use the 'water flowing' model of heat transfer (its not useful for simulation but it can explain behaviors) the leakage current results in a fixed amount of heat being dumped into the chip. Active power dissipation gets added to that and the combination is the total power created. Chip designers build systems to transfer that heat into an ambient cooling fluid (typically air) and away from the chip. You can do that by blowing air over a large surface area (as room temperature air goes by, it becomes warmer and the heat sink becomes cooler).
The transistors have always been small enough for 'weird quantum effects' the most well known is quantum tunneling of electrons into the gate area. Those effects are known and designed around but so far have not prevented the shrinkage of transistors (increasing the areal density of same).
I really want to start seing 128 or 256 bit processors... but with brand new architectures, putting aside the x86 and 64x86 architecture, with a huge instruction set like gpus... I wonder how much time could someone need to break sha1 in a 64 core 256 bit gpu alike processor.
I'm probably in a very small minority but I think that the 'free ride' we got from Moore's law in terms of transistor density leading to an increase in clock frequency has caused us to be locked in to a situation that is very much comparable to the automobile industry and the internal combustion engine.
If it weren't for that we'd have had to face the dragons of parallelization much earlier and we would have a programming tradition solidly founded on something other than single threaded execution.
Our languages would have likely had parallel primitives and would be able to deal with software development and debugging in a multi-threaded environment in a more graceful way.
Having the clock frequency of CPUs double on a fairly regular beat has allowed us to ignore these problems for a very long time and now that we do have to face them we'll have to unlearn a lot of what we take to be un-alterable.
I'm not sure about much about the future, the one thing I do know is that it is parallel and if you're stuck on waiting for the clock frequency increases of tomorrow you'll be waiting for a very long time, and possibly forever.
Moore's Law still applies today; the number of transistors continues to double every couple of years. However, the transistors no longer go towards making clock speeds faster; instead, we get more parallel cores, and more impressive instruction sets.
And I agree that we've taken too little time to look at parallelism. In particular, our current approaches to concurrency (such as mutual exclusion or transactions) don't actually provide much in the way of useful parallelism; they just serialize bits of the code that access shared data. We don't actually have many good algorithms that allow concurrent access to the same data, just concurrent access to different data.
Currently writing my dissertation on exactly this topic: a generalized construction of scalable concurrent data structures, which allows concurrent access to the same data from multiple threads without requiring expensive synchronization instructions.
Clojure's data structures are rather good for "concurrent access to the same data". References change value, but values don't change. The references are protected by read/write locks but the values in them need no protection once they have been extracted and while they are being used.
Let me give you one example of how the wrong habits have become embedded in how we think about programming because of the serial nature of former (and most current) architectures:
One of the most elementary constructs that we use is the loop. Add four numbers: set some variable to 0, add in the first, the second, the third and finally the fourth. Return the value to the caller. The example is short because otherwise it would be large, repetitive text. But you can imagine easily what it would look like if you had to add 100 numbers in this way, and 'adding numbers' is just a very dumb stand-in for a more complicated reduce operation.
That 'section' could be called critical and you'd be stuck at not being able to optimize that any further.
But on a parallel architecture that worked seamlessly with some programming language what could be happening under the hood is (first+second) added to (third+fourth). You can expand that to any length list and the time taken would be less than what you'd expect based on the trivial sequential example.
Right now you'd have to code that up manually, and you'd have to start two 'threads' or some other high level parallel construct in order to get the work done.
As far as I know there is no hardware, compiler, operating system or other architectural component that you could use to parallelize at this level. The bottle-neck is the overhead of setting things up , which should be negligible with respect to the work done. So parallelism would have to be built in to the fabric of the underlying hardware with extremely low overhead from the language/programmers point of view in order to be able to use it in situations like the one sketched above.
Those non-parallelizable(sp?) segments might end up a lot shorter once you're able to invoke parallel constructs at that lower level.
What you've described has been available for a while in Haskell[1]. These tiny, parallelizable units of computation are called "sparks", and are spawned off as easily as "par x y".
No special hardware is required — it's all in the runtime. Quoting from Parallel Haskell Digest[1]:
"""You may have heard of sparks and threads in the same sentence. What's the difference?
A Haskell thread is a thread of execution for IO code. Multiple Haskell threads can execute IO code concurrently and they can communicate using shared mutable variables and channels.
Sparks are specific to parallel Haskell. Abstractly, a spark is a pure computation which may be evaluated in parallel. Sparks are introduced with the par combinator; the expression (x par y) "sparks off" x, telling the runtime that it may evaluate the value of x in parallel to other work. Whether or not a spark is evaluated in parallel with other computations, or other Haskell IO threads, depends on what your hardware supports and on how your program is written. Sparks are put in a work queue and when a CPU core is idle, it can execute a spark by taking one from the work queue and evaluating it.
On a multi-core machine, both threads and sparks can be used to achieve parallelism. Threads give you concurrent, non-deterministic parallelism, while sparks give you pure deterministic parallelism.
Haskell threads are ideal for applications like network servers where you need to do lots of I/O and using concurrency fits the nature of the problem. Sparks are ideal for speeding up pure calculations where adding non-deterministic concurrency would just make things more complicated."""
Right, but at some level if you want the OS to have multiple cores active within the same process then you'll have to spawn multiple threads. So I'm wondering if these threads are pre-spawned and assigned from some kind of pool (relatively low overhead) or if they're started 'on demand' or some mechanism like that. Thank you very much for the pointer, I'll read up on this, it is definitely a very interesting development.
That would be very similar to Objective C's asynchronous blocks. The system manages a queue of blocks and a set of threads to schedule those blocks in.
I think (and I recognize I'm not a theorist) that the synchronous aspect of the queue management is still going to hurt for the original "add numbers in a loop" case until we get better hardware support for them. Is it better than spawning a thread? Of course. But it still isn't ideal.
I'm not poo-pooing improving the ability get 10x speedups... that'd be awesome in many contexts.
Rather I think a lot of even "embarrassingly parallel" problems have lots of micro-sequential code within.
With your example there are mico-sequential portions for allocating the processors for the split addition to run on, and then the sequential bit of adding the resultants back together again.
Those micro-sequential portions are right now lumped into one huge 'can't fix', to be able to exploit parallism at that level would make huge speedups possible.
After all, Amdahl's law is 'bad' when you're looking at a 20% segment that you can't improve, but as you get closer to 100% the pay-offs of even small optimizations becomes larger and larger.
FPGA's is where parallel processing is alive and well.
I've done a lot of real-time image processing work on FPGA's. The performance gains one can create are monumental. One of my favorite examples (one that parallels yours) is the implementation of an FIR (Finite Impulse Response) filter --a common tool in image processing.
How it works: Data from n pixels is multiplied by an equal number of coefficients, the results are added and then divided by n. There are more complex forms (polyphase) but the basics still apply.
Say n=32. You multiply 32 pixel values by 32 coefficients. Then you sum all 32 results, typically using a number of stages where you sum pairs of values. For 32 values you need five summation stages (32 values -> 16 -> 8 -> 4 -> 2 -> result). After that you divide and the job is done.
Due to pipelining this means that you are processing pixel data through the FIR filter at the operating clock rate. The first result takes 8 to 10 (or more) clock cycles to come out of the pipe. After that the results come out at a rate of one per clock cycle.
If the FIR filter is running at 500MHz you are processing five-hundred million pixels per second. Multiply that by 3 to process RGB images and you get to 1.5 billion pixels per second.
BTW, this is independent of word width until you start getting into words so wide that they cause routing problems. So, yes, with proper design you could process 1.5 billion 32 bit words per second. Try that on a core i7 using software.
For reference, consumer HD requires about 75MHz for real-time FIR processing.
A single FPGA can have dozens of these blocks, equating to a staggering data processing rate that you simply could not approach with any modern CPU, no matter how many cores.
This is how GPU's work. Of course, the difference is that the GPU hardware is fixed, whereas FPGA's can be reconfigured with code.
My point is that we know how to use and take advantage of parallelism in applications that can use it. Most of what happens on computers running typical consumer applications has few --if any-- needs beyond what exists today. When it comes to FPGA's and this form of "extreme parallel programming", if you will, we use languages like Verilog and VHDL. Verilog looks very much like C and is easy to learn. You just have to think hardware rather than software.
The greater point might also be that when a problem lends itself to parallelization a custom hardware approach through a highly reconfigurable FPGA co-processor is probably the best solution.
The next major evolution in computing might very well be a fusion of the CPU with vast FPGA resources that could be called upon for application specific tasks. This has existed for many years in application-specific computing, starting with the Xilinx Virtex 2 PRO chips integrating multiple PowerPC processors atop the FPGA array. It'd be interesting to see the approach reach general computing. In other words, Intel buys Xilinx and they integrate a solution for consumer computing platforms with API's provided and supported by MS and Apple.
FPGAs have been the next big thing for at least 15 years, during which time the consumer GPU has made huge performance increases, and is turning into a general purpose parallel vector unit. Still seems to me the GPU is on track to fill this role and the fpga will stay niche, has anything changed to change this?
What's changed is the definition of GPU. 15 years ago, the most programmability a GPU had was a few registers to switch between a handful of hardcoded modes of operation. For the past several years, GPUs have been something like 80% composed of Turing-complete processors that can run arbitrary software, and they've more recently gained features like a unified address space with the host CPU, and the ability to partition the array of vector processors to run more than one piece of code at the same time. These features are 100% irrelevant to realtime 3d rendering.
GPU architectures don't exactly resemble FPGAs when viewed up close, but for the right kind of problem, an application programmer can now deal with a GPU in the same manner as an FPGA. (In fact, with OpenCL, you can use the exact same APIs.)
> FPGAs have been the next big thing for at least 15 years
It's a tough equation. They are certainly not aimed at or geared towards a commodity co-processor slot next to the CPU in a consumer PC.
What I am arguing or proposing is that if Intel acquired Xilinx and got Microsoft and Apple behind the idea of integrating an FPGA as a standard co-processor for the i-whatever chip we could see vast performance improvements for certain applications.
Per my example, I can take a $100 FPGA today and process 1.5 billion 32 bit pixels per second through an FIR pipeline. That same hardware is instantly reprogrammable to implement a myriad of other functions in hardware, not software. The possibilities are endless.
Many years ago I was involved in writing some code for DNA sequencing. We wrote the software to gain an understanding of what had to happen. Once we knew what to do, the design was converted to hardware. The performance boost was unbelievable. If I remember correctly, we were running the same data sets 1,000 times faster or more.
GPU's are great, but I've seen cases where a graphically intensive application makes use of the GPU and precludes anything else from using it. Not having done any GPU coding myself I can't really compare the two approaches (FPGA vs. GPU). The only thing I think I can say is that a GPU is denser and possibly faster because it is fixed logic rather than programmable (it doesn't have to support all the structures and layers that an FPGA has).
What I'd love to see is an FPGA grafted onto a multicore Intel chip with a pre-defined separate co-processor expansion channel via multiple MGT channels (Multi-Gigabit Transceivers). This would allow co-processor expansion beyond the resources provided on-chip. If the entire thing is encased within a published-and-supported standard we could open the doors to an amazing leap in computing for a wide range of advanced applications.
Let's see, Intel market cap is around $120 billion and Xilinx is somewhere around 8 billion. Yeah, let's do it.
You should take a look at cilk. They compile two versions of your code: one sequential, one parallel. The runtime switches between them dynamically. This avoids paying a lot of overhead managing parallelism for small subroutines, but still presents the programmer with a unified view of very fine grained concurrency.
Indeed, we see this today with our compiler (Manticore). On our 48-core AMD and 30-core Intel boxes, we now routinely have flattening speedup curves due to the small sequential portions of even our supposedly "embarrasingly parallel" benchmarks.
Compilers, even icc, are still shockingly bad at making good use of the x86_64 instruction set for sequential code. Part of that, of course, is due to C. But part of it is also our (my) fault as compiler writers because even with fantastic type information and unambiguous language semantics we emit shockingly dumb code.
Yes, certainly the vector instructions. There are a few keys issues many C compilers seem to run into today:
- Loop unroll identification is really bad. For example, ICC will unroll and turn a single-level loop with a very obvious body into streaming stores if the increment is "i++" but not if it is the constant "i+=1".
- The register allocation problem has some subtelties. Many of the SSE registers overlap the name of the multiple packed-value register with those of the individual ones (e.g. "AX = lower 16 of EAX"), so knowing that you want four numbers to be in the right place without additional moves means a little bit more thinking.
But, there's also very little control-flow analysis done or global program analysis done except for some basic link-time code generation and profile-guided optimization. There's a lot you can do (e.g. cross-module inlining; monomorphizing to remove uniform representation; dramatic representation changes of datatypes), though admittedly some of it requires a more static language with some additional semantic guarantees.
Well that law is a good theoretical instrument.
But aside from some computations which have been deliberately designed to be impossible to parallize, it seems to me that Amdahls assumes that there is some constant part of the program that just can't be parallized. I disagree with that, and I think Erlang offers the best counterargument-- just because some part has to be done on one node (or thread) doesn't mean that the computer can't do other work at the same time.
Sure if your mental model of computation is do this, then that, and then do these two things in parrallel and then do these other things in parallel then gather all the results, this would suggest you have a problem under Amdahls law. If your mental model is a set of independent nodes sending messages to each other then when you run into a bottleneck, you spawn a few more of the most commonly used nodes. Suddenly there is no part of the program which has to be run sequentially while the rest of the world waits.
You're not speeding up a given instance, you're "merely" running more instances or running larger problems. (In some problems, the sequential portion is roughly constant, independent of the amount of data. So, you can reduce the effect of the sequential portion by increasing the amount of data.)
More throughput and larger data are both good things but they're not the same as running a given problem faster.
Yes, but "90% of a task" is very different from "90% of the code."
The parallel parts tend to be the tight loops, etc where the program spends most of its time, which means for some tasks a number quite close to 100% of the runtime is parallelizable.
I don't mean this as a backhanded compliment, but you're in no way in the small minority. You've very eloquently explained what pretty much everyone considers to be the actual situation.
Even way back in the mid 90s debated getting a Pentium Pro (two CPU) because I couldn't see how a CPU could keep getting faster. But I think I needed Win NT which was too expensive and I was still new to Linux.
Not sure why you think you're expressing a minority opinion, you're stating generally accepted fact. We hit the soft limit years ago, that's why Intel finally dumped the Pentium 4, they realized they couldn't make it scale.
Everything since has been about finding ways to do more with fewer cycles, and more research and education on parallelization at all levels (from on-die branch prediction up to google-scale distributed systems). I don't know of anyone who disputes this in principle.
It's generally accepted fact that "the free ride is over". It's more difficult to argue that we'd be better off if it had happened sooner, that we'd escape more quickly to better global optima if the local optimum we're stuck in wasn't quite so deep.
Improvements to the processors we've made by adding more cache, executing instructions out of order, predicting branches better etc are making it more difficult to escape from the conclusion we've reached. To use GP's analogy, there's now a gas station for every suburb and a garage for every house. We know better solutions are possible, but getting from here to there is going to be difficult and expensive, and it could be worse than the status quo for the early adopters in the short term.
You are right, this has been predicted some time ago. The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software[1] from 2005 is the seminal essay on this subject.
High(er) Frequency means that you have to run at a higher core voltage (this is, in part, because gate propagation delay is inversely proportional to bias voltage, i.e., the voltage corresponding to a 'high' or 1 bit). You have to decrease the propagation delay so that the clock tick gets everywhere in the processor quickly (one part of the clock doesn't lag the other parts, called clock skew). So in order for things to run faster, you'd have to run it at a higher V(bias). Now that means that there are higher thermal costs (things get hotter) - heat produced is proportion to voltage.
So its now mostly a thermal management problem. This is the primary problem in the newer chips. Even though we can pack in more transistors, we can't get signals among them faster without higher V and making it run too hot.
Therefore, our solution is to use the extra transistors to create a separate new processor, running with a different clock, so the 'tick' doesn't have to reach all parts of this rather big chip, but just needs to be synchronized intra-core.
I'm curious if asynchronous logic will get brought back in as time goes on. Multi-core is essentially desynchronising the individual cores since (iirc) clock generation and distribution is one of the most expensive parts of the processor, in both energy and size.
Historically, it lost out because of the added complexity of handshaking/synchroniser logic scattered all over the place, and the mess a mishandled metastable condition propagating through the system could cause. How that we've got transistors to burn, however, and routing is no longer done on large empty floors with crepe tape...
Well, Handshake did make an asynchronous ARM core not too long ago, and Achronix has a nice business in async FPGAs, so the idea isn't dead. That said, I'm not sure (though I'd love to be proved wrong) that the idea will really go big again. Synchronous chips are still easier to reason about.
By far the most expensive real estate on a typical processor is on-chip RAM, and that really does need a clock. Sure, clock-tree synthesis is complex enough that you may even still be able to start up a company selling a tool for it, but it's still possible for a few reasonably competent engineers to do within some weeks.
Right, but decreasing the size of the chip means that you effectively can get signals around it faster (because they don't have as far to go) and allows them to be run at lower voltages as well - modern CPUs seem to be generally around 1V, but 10 or 20 years ago they were around 2V, so there is (or has been at least?) a reduction in that over time as well.
This is a good example of why science isn't a popularity contest. The top voted reply makes some vague noises about vt-scaling and leakage. It then claims that we "don't get a very good "off" if the threshold voltage is too low". This is incorrect. Leakage doesn't degrade the logic values for CMOS-style logic, which is the vast majority of the digital logic in the world.
The real issue which the OP may or may have been trying to get at is that leakage power eats into the chip's power budget. Since we'd rather not burn our budget on leakage, we reduce leakage by increasing the threshold voltage. But unfortunately, this comes at the cost of frequency.
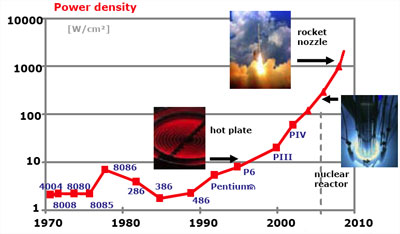
The other very important issue is that of power-density. There's a famous graph that Shekar Borkar of Intel [1] made showing that if we continued to ignore power dissipation issues like in the past our chips would run ridiculously hot (IOW, they wouldn't work at all because they'd just burn themselves to death).
There are also other issues like the fact that your wires start acting like antennas at 5+ GHz and that reliability concerns like electromigration and dielectric breakdown are getting worse with newer technologies.
A much more recent and reliable (not to mention highly-cited) reference on scaling and power issues is [2].
While I agree that power is the primary issue leakage does have a correlation with "degrading the off" value.
Specifically the effects of drain induced barrier lowering becomes very significant in the sub-threshold region as the channel length is reduced. This has the effect of both increasing drain current (leakage) and making the transistor more difficult to turn off, that is a larger gate bias is required to turn the transistor off.
While "leakage" isn't the cause, you do get leakage and a harder to turn off transistor at the same time, at least for this type of leakage.
Hmm. In a CMOS structure with a weakly turned off device, you'd need the effective off resistance to be more than 1/20th of the effective on for the logic value to degrade by roughly 5%. Did we have such leaky transistors for 130nm/90nm when the shift happened?
A quick calculation I did with a 90nm model for I have some parameters with vt=0.3, vdd=1.2, subthreshold slope=90mV/decade and dibl coeff=0.1 seems to suggest that leakage would still be < 1/100th of the on current.
I don't think so. The effect of DIBL is an increase in leakage current with the drain to source voltage.
The first-order model I was taught in school was that leakage current not considering DIBL used to be proportional to exp(vgs-vt) but thanks to DIBL leakage is now proportional to exp(vgs - vt + eta*vds). The eta here is the DIBL coefficient, which AFAIK is 0.1 or thereabouts.
I would guess the concerns are less about corrupting results, and more about leakage power and switching speed. If you have a very leaky pulldown, switching to "1" is going to be slower.
I'm not convinced for the same reason I posted above. The on-current is at least an order of magnitude higher than the off-current for all technology nodes that I know of.
The only way I see this having a significant effect is through the vt vs. speed trade-off I mentioned above. Lower vt's exponentially increase leakage power, so we push the vt up to combat leakage, but this reduces transistor speed because frequency is roughly proportional to the on-current which is roughly proportional to gate overdrive vdd - vt.
We've gotten very close to physical limits. Quick back-of-the-envelope estimate: if electrons traveled at the speed of light through silicon (they don't), then in 3GHz, an electron could travel .1 meters. In reality, electrons in silicon travel quite a bit slower than that. Net result: electrons can barely cross the diameter of the chip in one cycle, even without gate propagation delays and other factors limiting work done per cycle.
So, if you want data from a tiny distance away, such as a local register, you can grab it and do something simple with it in one cycle. If you need data from any further away, forget about it; cache takes longer, another core takes even longer, and memory takes far longer.
Fun fact: electrons in an metallic wire under a potential difference move only in the order of mm/s. See e.g.[1]
As electrical signals still travel at about half the speed of light, that seems besides the point. However, electrical signals do not need to span the entire width of a chip in order to have an effect. That is true for your example of accessing memory, but not for the actual calculations happening inside the CPU.
On each clock cycle, all transistors are 'fed' by the transistors before it. The state of a transistor only depends on the states of the immediately connecting transistors on the clock cycle before it. That means the signal only has to travel the length of a single transistor on each clock cycle. We could have CPU's working at 3THz and a much larger focus on the difference between CPU-bound and IO-bound tasks.
The easiest to understand analogy to illustrate this that I've found to date is to imagine a tube full of marbles, push one more marble in on one end and another one will pop out instantly on the other end. As long as the marbles are all the same colour it is as though the marble you pushed in has miraculously teleported to the far end of the tube. It appeared to have moved at the speed of light even though in reality all the marbles have shifted only an amount equal to the diameter of a single marble.
There is a problem with that analogy: if you only apply pressure to a single marble, the marble at the other end will not be pushed out instantly. In fact, the 'signal' will travel with the speed of sound in the material of the marbles and you can measure the time difference it takes for the last marble to move after the first one has moved. The marbles will be slightly compressed and decompressed while moving, accounting for the extra length needed to accommodate the 'not moving instantly'. [1]
A better analogy would be one where all marbles are pushed simultaneously. That is more like what happens in logic circuits.
[1] People doubting relativity often try this thought experiment: I have an incompressible metal bar of a lightyear long. I press on one side. The other side must move instantaneously and not after 1 second (or longer). In fact, this proves the reverse: relativity is incompatible with the existence of incompressible metal bars. As we know, all metal bars are in fact compressible, so that is not a problem. And with compressible metal bars, the thought experiment fails, because the push will travel with the speed of sound.
That's true, but it is only an analogy, and like every other analogy it breaks down at some level (after all, it isn't the 'real thing').
The fact that there is a pressure wave set up in the materials is possible because marbles are made of some material (glass, stone, metal, whatever). If you wanted a 'perfect' picture you'd have to explain about electron migration in detail and then we're looking at a completely different picture.
You'd not have a pressure wave in an electron to begin with, and they're not 'pushing' against adjacent electrons either.
But it serves well to show how a slow move can have an apparent instantaneous effect at a distance.
Edit: I had a thing written here, but I figure I'm not understanding what you mean by 'all marbles are pushed simultaneously'. Can you elaborate? Other than the conflation of the speeds of light and sound (which is not such a big deal, really), it's a good analogy.
As for the 'all marbles are pushed simultaneously': a key characteristic of useful transistors is that they operate as amplifiers[1]. This is possible because effectively, every transistor has its own power source. As such, on each clock cycle, then can all get a simultaneous push from their power sources.
BTW, I'm not conflating the speeds of light and sound. If you bang on one side of an iron bar, a wave travels through the material, quickly compressing and decompressing the bar where the wave passes. Such waves travel at the speed of sound in that material, no at the speed of light. That makes sense, because sound is nothing more than the physical modulation of the density of a medium, most commonly air.
You're not, the person you're replying to was. I find it odd that you would object to an analogy where the signal propagates through the marbles at the speed of light (i.e. 'instantly'), and offer up instead one where each marble moves simultaneously. If the exit event is simultaneous to the entry of the other marble, they are separated by a spacelike interval despite the causal relationship between the two events. This violates relativity.
On the other hand, in the original analogy the two events are separated by a lightlike interval, which while impossible in the case of marbles, at least does not violate relativity when the two events are causally linked. This is what I meant when I said the conflation of the speed of sound and the speed of light is not such a big deal, in this case.
Anyway, it's perfectly reasonable to talk about light traveling instantly and it's time that has propagation delays. The idea being what separates the present from the future is the ability to interact with each other.
The electrons are only moving at ~ mm/s. With an AC current, the net effect is that they're not moving at all. Electrical power is not provided by the movement of electrons. The force carriers of the electrical field, the particles responsible for actually exchanging energy, are photons.
I initially was mostly interested in the word instantly, but if we're going to analyze this analogy further, I'd have to say you just can't treat electrons inside bulk materials as particles. It may sound sensible and give you the idea you understand what's going on, but it's just not even wrong.
Umm, yea just like the marbles in the example. If you have a marble pushed into a pipe with 1,000 marbles the one popped out at the end is pushed out a lot faster than any single marble moves.
Ummm... no? It'll come out at roughly the same speed (less if the moment it came out there was still energy trapped in the form of compressed marbles when it emerges). Why would it be otherwise?
Have you ever seen those desktop toy's where steel balls 10+ steel balls are strung up next to each other. You drop one and it fall hit's one end of the chain and in less time than it would have taken the first ball to move that distance the last one pops off the end? Same concept the final ball moves a little slower than the first ball that hit the chain, but it start moving sooner than it would have taken the first ball to move the distance of the chain.
Ok that's true, but not how I read your post. Yes the energy is transfered at the speed of sound in the material, but I read your post as saying the velocity of the marble on the end is greater than the velocity of any other marble, including the one you push in, which is certainly not true.
I've been told by chip designers that chip-crossings are on the order of 5-10 cycles these days. This is for data; they can arrange faster crossings for some signals, such as clocks, but they don't like doing this.
GPUs are getting really interesting. It's not general purpose yet -- you still have to worry a lot about contention and memory bandwidth -- but you can do a jaw-dropping amount of computation in a second on a recent GPU.
One thing Knuth doesn't mention is that he may not explicitly use that extra core on his workstation more than once a week for computation, but he /does/ use it for parallelism at the OS level, where it's helping reduce the latency of his interactions. I can definitely tell a single CPU box from a multicore box, given a couple of Emacs sessions.
I was going to chime in and say, "ahh, but GPUs are worthless for everyday tasks!" when I realized that my 4-yr old MacBook is just fine for every day tasks. For scientific computing GPUs seem to be a great way forward. The pain and complexity of writing parallel code is mitigated by the fact that, hey, scientists are writing it.
For normal, everyday usage I see no reason why 3.5ghz is any better or worse than 20ghz. Or 2ghz, for that matter. The 'computer' my mom is most excited about now is her iPad 2, which has less power than the workstation I built in high school.
A nitpick - electrons travel very slowly in silicon (iirc on the order of a few metres per second), but electrical signals travel rather more quickly - around a half or two-thirds the speed of light (again, iirc.)
Think of electrical signals like waves of sound through the air - the air particles don't move by any significant amount, but the signal propagation, is rather quick because of the speed at which movement is transmitted to neighbouring particles (and so on.)
Andrew: Vendors of multicore processors have expressed frustration at the difficulty of moving developers to this model. As a former professor, what thoughts do you have on this transition and how to make it happen? Is it a question of proper tools, such as better native support for concurrency in languages, or of execution frameworks? Or are there other solutions?
Donald: I don’t want to duck your question entirely. I might as well flame a bit about my personal unhappiness with the current trend toward multicore architecture. To me, it looks more or less like the hardware designers have run out of ideas, and that they’re trying to pass the blame for the future demise of Moore’s Law to the software writers by giving us machines that work faster only on a few key benchmarks! I won’t be surprised at all if the whole multithreading idea turns out to be a flop, worse than the "Itanium" approach that was supposed to be so terrific—until it turned out that the wished-for compilers were basically impossible to write.
Let me put it this way: During the past 50 years, I’ve written well over a thousand programs, many of which have substantial size. I can’t think of even five of those programs that would have been enhanced noticeably by parallelism or multithreading. Surely, for example, multiple processors are no help to TeX.[1]
How many programmers do you know who are enthusiastic about these promised machines of the future? I hear almost nothing but grief from software people, although the hardware folks in our department assure me that I’m wrong.
I know that important applications for parallelism exist—rendering graphics, breaking codes, scanning images, simulating physical and biological processes, etc. But all these applications require dedicated code and special-purpose techniques, which will need to be changed substantially every few years.
Even if I knew enough about such methods to write about them in TAOCP, my time would be largely wasted, because soon there would be little reason for anybody to read those parts. (Similarly, when I prepare the third edition of Volume 3 I plan to rip out much of the material about how to sort on magnetic tapes. That stuff was once one of the hottest topics in the whole software field, but now it largely wastes paper when the book is printed.)
The machine I use today has dual processors. I get to use them both only when I’m running two independent jobs at the same time; that’s nice, but it happens only a few minutes every week. If I had four processors, or eight, or more, I still wouldn’t be any better off, considering the kind of work I do—even though I’m using my computer almost every day during most of the day. So why should I be so happy about the future that hardware vendors promise? They think a magic bullet will come along to make multicores speed up my kind of work; I think it’s a pipe dream. (No—that’s the wrong metaphor! "Pipelines" actually work for me, but threads don’t. Maybe the word I want is "bubble.")
From the opposite point of view, I do grant that web browsing probably will get better with multicores. I’ve been talking about my technical work, however, not recreation. I also admit that I haven’t got many bright ideas about what I wish hardware designers would provide instead of multicores, now that they’ve begun to hit a wall with respect to sequential computation. (But my MMIX design contains several ideas that would substantially improve the current performance of the kinds of programs that concern me most—at the cost of incompatibility with legacy x86 programs.)
Knuth comes across as living in a bit of denial here... Sure the frequency speedups were much nicer, but faced with hardware limits that make this impossible, he should point out that the future lies in finding algorithms best suited to multicore. They surely deserve their own volume of TAOCP, and I don't see how this would be wasted research for the next 10+ years.
There are some amazing lock-free data structures/algorithms out there which should be taught in any CS curriculum.
Intel has been releasing some great tools to aid with multicore development since they realized years ago that this was the only way to get more performance.
Knuth comes across as living in a bit of denial here... Sure the frequency speedups were much nicer, but faced with hardware limits that make this impossible
It's easier to say "the hardware guys are dropping the ball" than to acknowledge silly things like "Physics".
Now, he could try to argue that hardware should be responsible for paralleling things under the covers, and that would be a bit more reasonable- though I would still have to disagree. CS folks are the ones supposed to be discovering algorithms; find them, and have the hardware guys stick them in once they are known.
Yes, some of those lock-free structures are amazing.
However, if you read the fine print it turns out that they are quite often slower than lock-based exclusion on top of one of Knuth's structures. The atomic primitive operations still require cross-core communication which only gets more expensive with more cores.
Most applications simply don't parallelize perfectly. We're going to have to face the fact that not only is the free lunch over, the lunch we have to pay for isn't always as satisfying.
I think Knuth here has hit the nail on the head (as usual). There are plenty of applications of parallelism but they don't affect everything.
I am going to add something to this. There are a lot of areas where existing performance on a single core is certainly good enough, and where optimizing for a single core provides the ideal combination of performance and maintainability. I have to think about some of the weird multi-row insert bugs I have run into on MySQL and think that they are thread concurrency problems, but with PostgreSQL (single threaded model) things just hum along well.
We are at a point hence where processors don't need to offer better performance at single tasks for the most part, and neither do software developers, and where those that do can be frequently split off into some sort of component model either with separate threads or separate processes.
At the same time when we look at server software, we are usually talking about parallel jobs, and so those of us who do technical work on server software in fact do see performance increases. I mean if I am running a browser on my box which connects to a web server on my box which uses an async API to hit the database server also on my box, these multiple cores come in very handy.
This being said, I do wonder if a better use of additional capacity at some point would be in increasing cache sizes and memory throughput rather than adding more cores.
I have to think about some of the weird multi-row insert bugs I have run into on MySQL and think that they are thread concurrency problems, but with PostgreSQL (single threaded model) things just hum along well.
Surely that shows that there is an issue with multi-threaded programming being prone to bugs rather than parallelism in general? It seems to me like many of the people advocating parallelism as the future of software believe we have to invent better ways to manage that parallelism as well, current methods (particularly threading) being deficient. For example, see Guy Steele's work on Fortress. [1]
Of course it is not with parallelism in general. PostgreSQL is pretty good at the process model although this means that queries can't have portions executed in parallel (within the query). Multiple sessions with multiple queries can be executed in parallel with no problem however.
Note that the big open source projects (Gridsql and Postgres-XC) which get rid of this limitation currently do this through a different method without breaking single threaded process model.
So the question is how intimately connected portions that run in parallel should be.
Multiprocessing doesn't help with TeX because compiling it is an inherently linear problem the way it was designed. One can imagine a layout language that sucks less (TeX is very powerful but one of the worst designed languages in existence) that can manage to work on rendering different parts of the document in parallel.
> Surely, for example, multiple processors are no help to TeX.
But but but, The STEPS project at http://vpri.org did find a way ! Basically, each character is an object, and is placed relatively to the one just before it. Sure, you'd want to wait for the previous character before you place the next one, but you could easily deal with each paragraph separately…
I'd like to blame hardware vendors as well, but I think they did their best to provide Moore's law Free Ride to single threaded programming. The first one who don't would be driven out of market. And now we know that parallelism can be applied quite pervasively, it'd be our fault not to do it.
Pretty sure you can't do what you are saying for some layout considerations. For example, how do you layout a paragraph if you don't know whether or not it will be split across a page boundary?
It ends up being iterative. First you layout every paragraph in parallel, then layout the paragraphs on the page, then re-layout any paragraph that needs to be split, etc.
The entire document could be laid out as if the page length was infinite, and then -- depending on desired page length -- the page breaks could be inserted between the appropriate lines.
In any case, in a typical document the overwhelming majority of paragraphs won't be affected by page breaks. So their layout could be parallelized regardless of where the page breaks wind up occurring.
When laying out a paragraph near a page boundary, you don't simply insert the page break wherever you want. In fact, depending on whether or not orphaned lines are desired, you may wind up adjusting the inter word spacing of several lines worth of characters.
That said, the other poster is likely correct that you can probably just do an optimistic run in parallel across all paragraphs, and then rerun any that are "dirty" from other considerations. In this regard, it is a lot like multiplying two large numbers. There are some parts that are pretty much only done sequentially, but some could likely be guessed or pinned down in parallel.
The question remains, how much benefit do you really get from this, over just speeding up the sequential operation? Especially in any layout that has figures or heaven help you columns. A single "dirty" find could likely render all of the parallel work worthless. Best example I could give would be a parallel "adder" adding 9999 to 1111. Since every single digit has a carry, the whole operation winds up being sequential anyway.
I wish people would quit asking this question. This is just another case of the Mhz myth. Who cares what the clock speed is if modern CPUs can execute instructions 2-4x faster per clock than they did 30 years ago.
Go look at the Bulldozer design, 2 hardware decoder/scheduler engines, 4 integer ALUs, 2 fp ALUs, all per core...
A shared L3 cache per socket that is owned by the memory controller and is socket-local to other sockets (ie, all memory controllers conspire to cache system memory efficiently and synchronously know what is cached across all sockets)...
And the memory controllers also accept memory requests from ANY core on the Hypertransport bus, no matter which socket, and multi-socket boards commonly have one memory bank per socket, thus 4 sockets of dual channel DDR3-1600 would indeed give 820 gbit/sec of bandwidth that can be accessed (almost) in full by any individual core[1]...
The ALUs have execution queues, and any thread (currently 2 per core) can schedule instructions on it to maximize ALU packing...
And you can now buy Bulldozers for Socket G34 that have 16 threads/8 cores per socket, and G34 boards usually have 4 sockets.
So again, who cares what the mhz is?
[1]: A 4 socket setup has 4 or 6 Hypertransport links, on AM3+ and G34+ sockets this would be HTX 3.1 16bit wide links running at 3.2ghz, or 204 gbit/sec per link.
On a 4 socket ring, that would be 204 gbit/sec off each neighbor's memory bank, plus another 204 gbit/sec (also the speed of dual channel DDR3-1600) from the local memory bank, thus leading to 612 gbit/sec that could be theoretically saturated by a single core.
On a 4 socket full crossbar, it would be the full 820 gbit/sec.
Not necessarily. The fact is that you could probably do just exactly that by making the pipeline deeper. But making the pipeline deeper has a price: your control logic becomes much more complex and emptying the pipeline is more expensive. The question is then: does the price you pay become larger than the gain. As this is not happening I have a good guess :)
Historically, the Pentium 4 is an example of a Mhz-oriented design. The pipeline was made ridiculously deep. This meant that when you had heavy floating point intensive work, then the Pentium 4 was very very fast. Essentially this was because you could fill up the pipeline in the CPU and you have relatively few jumps in that code. It was just a processing job. On the other hand, the P4 suffered for almost any other task. Even to the point where a more beefy Pentium 3 (Tualatin) could beat it. Intel chose a path which was based on the P3 design for their Pentium-M CPU and that is the design which guided Core, Core 2 Duo, Core i7 and so on.
So it is possible, but it is not a given it would lead to faster CPUs. Mhz is but one of the knobs you can turn. The problem we are facing is that all the parallelism we can squeeze out of a sequential program has been done. Modern CPUs dynamically parallelizes what can be run concurrently. But to gain more, now, you need to write programs in a style where they expose more parallelism.
Who cares what the clock speed is if modern CPUs can execute instructions 2-4x faster per clock than they did 30 years ago.
I think we're more concerned with 3 years ago; if clock doesn't increase and IPC increases very slowly, that means new processors aren't faster enough to be worth buying.
Go look at the Bulldozer design
Indeed; look at the fact that it's not faster than its predecessor for many workloads.
But the workloads when it is faster? I'm very impressed with AMD's offering.
Have code thats largely complex branch and loop conditions that bust the branch predictor's balls and isn't cache friendly and is largely integers? Bulldozer eats it for breakfast and asks for more.
Because scaling limits. The stuff we're already getting uses very highly doped silicon. You could go smaller or faster if you could dope it more to keep the field characteristics viable, but more doping would screw up the silicon lattice. "More" also generally means an orders-of-magnitude increase.
There are a few alternative processes and materials, but they're costly as all hell and hard to do in bulk.
The main problem is that leakage current has started to become a problem[1]. Back in the day designers could just scale down features and rely on the reduced capacitance of the smaller areas to lower power usage enough to let them put in more logic. Unfortunately that only reduces active power, not leakage power. Transistors have started leaking more now that they're smaller. You can reduce leakage by lowering the voltage your processor operates at, but that also causes a reduction in the frequency that your transistors flip at because your logic voltage becomes smaller with respect to the transistor threshold voltage, meaning less current but unit of charge you have to move. Modern devices are also tending to run up against saturation velocity[2] now, limiting their switching speed still further.
You certainly could increase clock speed by increasing the voltage you put into a chip, and just accepting that you're going to have more leakage current and more wasted power. But we're already close to the edge of what chips can dissipate right now. You can try having less logic between clock latches, meaning you have a higher clock speed for your switching delay. However, this increases the ratio of latches to everything else so its a matter of diminishing returns. It also means that you've pushed your useful logic further apart, and now you have more line capacitance too. Finally, you can decrease the temperature of your silicon to substantially reduce the amount of leakage you get. This will let you raise the voltage safely, letting you attain faster switching speeds. The only problem is that this requires expensive cooling devices.
So what confuses me is that we've seen tech demos (and overclockers) push CPU speed to 4 to 10ghz. Are those gains so artificially made that they just can't be replicated at scale in the public market?
We can get them to go faster, just seemingly not for the public.
It was weird to buy my new Macbook Pro and after 3+ years, it was .2ghz slower than my old one. Now of course it has more cores, better instructions, etc... but it was still a weird thing.
Apple's done a great job of explaining the benefits of new ones to the consumers - they don't. I'm not being sarcastic. At the end of the 90's (and still largely today for most PC companies) its all about specs. Apple sold what you can do with each computer instead in a good, better, best format. I bet a large amount of computers sold at the Apple store never have the sales associate mention the clock speed.
As I said, it's a few years ago. Today you can get 5 GHz with Sandy Bridge on air (although it might entail testing a few dozen CPUs to find one that can reach that high).
But the OP was referring to speeds up to 10 GHz, those still need something special. Here's a current Guiness record, 8.4 GHz using liquid helium:
http://www.youtube.com/watch?v=UKN4VMOenNM
Most POWER7 cores are clocked in the 3.5-3.7 ish range and high density blade models at 2.4 to 3ghz. There is one model that can hit 4.25ghz but this is only achieved by shutting down half the cores on the chip to limit TDP.
The POWER6 hit 5Ghz but was an in-order architecture, which is far more limited than out-of-order capable architectures. One of the reasons the POWER7 is so much faster than the POWER6 at lower clock speeds.
That's because Power7s are more aggressively pipelined than Intel chips. Intel usually has around 20 FO4s of gate logic between clock latches, while IBM tries to keep it down to around 12 FO4s.
>What would happen if you added a second compressor loop with its cold side on the hot side of the first one? What if you added a third one? You've now got 3 stage cascade phase change(compressors cool stuff by compressing gas into a liquid, then letting it suck up thermal energy while decompressing/evaporating back into a gas elsewhere, i.e. phase change) cooling on one end, and a spectacularly inefficient heater on the other.
Now wait a second... that's not just wrong, that's precisely the opposite of reality. If you have a heat pump, it must be more efficient than a simple heating element. If it at all cools the processor, by the simple laws of thermodynamics, it must heat the room more than any process which simply converts the work directly to room heat.
CPU speed isn't a bottleneck anymore. These days improving caching, threading, and increasing the bus/memory speed have been the primary contributors to speeding up a computer. Once those bottlenecks close a bit you'll see those numbers begin to rise again.
that's a theoretical maximum. you increase Ghz, you have a shorter theoretical maximum length of path electricity can take through your chip. An i7 is not that small. You would have to shrink things further and further to get a smaller chip with shorter paths in it, which is what new fabrication methods have been about.
Obviously this is very difficult. Sure, chips could be even faster if they were just a few atoms across, but who would expect you to do meaningful computation in that size, or to be able to manufacture that.
As the top comment on reddit currently states, there's no issue with speed of light, the issue is with heating. And there's no "3.5Ghz" limit, stock, mass produced heating solutions limit us.
People get all sorts of crazy clock speeds by improving their cooling, mine's on Zalman 9500 fan and has no stability issues to run at 4.2Ghz (stock 3.0Ghz).
{kind=link}
1) Transistors dissipate the most power when they are switching (this is because they transit their linear region). So the more they switch the more power they dissipate, thus the power dissipation of any transistor circuit is proportional to its switching frequency.
2) Silicon stops working reliably above 150 degrees C, this is due to thermal effects in the silicon overwhelming its electrical characteristics. One way to think about it is that at 150 degrees C the silicon lattice structure is vibrating so hard because of heat the electrons can't move anymore.
3) Lithography and manufacturing techniques have increased the number of transistors per square millimeter of silicon exponentially over the years so the number of transistors has been observed to double every 18 months or so.
4) The ability to channel heat from silicon to the outside air is limited by the thermal conductivity of silicon and the ceramics used to encase it.
So those four parameters create a 'box' which is sometimes called the 'design space.' If you build a chip that is inside the box it works, if one of the parameters goes outside the box it fails.
In the great Mhz race of 1998 clock rates were pushed up which caused heat dissipation to go up, and transistor counts were going up too, so you got an n^2 effect in terms of heat dissipation. The race was powered by consumers who used the single number to compare machines (spec wars). It was unsustainable.
The end of that war occurred when AMD introduced multi-core (two cpus for the price of one!) architectures. And Intel had the largest design failure in its history when it scrapped the entire Pentium 4 microarchitecture after realizing it would never get to, much less past 4Ghz as they had promised.
AMD proved that for user visible throughput, multiple cores could give you a better net gain than a faster CPU. This side stepped the n-squared problem by having twice the number of transistors but running at the same clock rate, so the heat only went up linearly rather than exponentially.
It was a pretty humbling moment for Intel.
That begat the 'core wars' where Intel and AMD have worked to give us more and more 'cores'. The heat problem was still there, but it was managed with transistor design since the frequencies were staying flat.
Recently, some new transistor designs and system micro-architectures, have combined with the inevitable flattening of performance gains from multiple cores (see Amdahl's law), to give us 'turbo-boost' type solutions, where only one core runs at higher speed (side stepping Amdahl) at the expense of down clocking or even turning off other cores (sidestepping the frequency component of power increases).
Another technology on the horizon (which used to be only for the military guys) is SoD or Silicon-on-Diamond. Diamond is a wonderful conductor of heat and so if you make your processor on a diamond subtrate you can pull lots of heat out into an attached cooling system. Get ready for 7" x 7" heat management assemblies though that attach to these things. Or alternatively a new ATX type form factor that includes something that looks like a power supply but is a chiller that attaches via tubes to the processor socket.