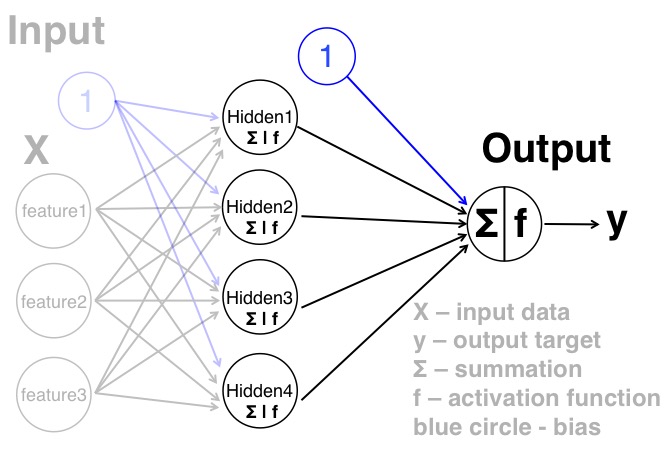
For one, "depth-three" implies three layers, and in the standard terminology of the field what they really mean is "depth one".
And another major red flag:
We give a polynomial-time algorithm for learning neural networks with one hidden layer of sigmoids feeding into any smooth, monotone activation function (e.g., sigmoid or ReLU)
They cite https://arxiv.org/abs/1610.09887 for their definition of network depth, which defines it in such a way that e.g. a ReLU network of depth 2 is of the form linear2(ReLu(linear1(input))). That means, depth is the number of linear layers.
The "depth-three" model in this paper is a bit strange in that their second layer has only one output, so the third linear layer doesn't have any effect. I would have called this "depth two"; but it is internally consistent with their definition of depth.
> How is ReLU smooth?
It is 1-Lipschitz, which is smooth enough for them.
> The "depth-three" model in this paper is a bit strange in that their second layer has only one output, so the third linear layer doesn't have any effect. I would have called this "depth two"; but it is internally consistent with their definition of depth.
No, it does have an effect: It takes a linear combination of the outputs of the previous layer, and then applies a non-linearity $\sigma'$. If $\sigma'$ is the logistic function, then the output of the last layer is a probability.
No, the last layer is just a linear layer, there's no non-linearity. That's what's strange about their definition. The depth-three network only applies a non-linearity twice, which would conventionally be labeled as depth two.
Yes, it is a classical NN with a single output node. I'm not disputing that, I just think their calculation of depth is strange. The network only applies the sigmoid function twice, and would ordinarily be regarded as having a depth of two. The third linear layer is fixed to multiplying by 1, which is what I meant by "has no effect". (Did you miss that I was talking about the third layer?)
{kind=link}
For one, "depth-three" implies three layers, and in the standard terminology of the field what they really mean is "depth one".
And another major red flag:
We give a polynomial-time algorithm for learning neural networks with one hidden layer of sigmoids feeding into any smooth, monotone activation function (e.g., sigmoid or ReLU)
How is ReLU smooth?