Functional programming means, that your program is composed out of functions. A function only depends on its input parameters and the effect of applying a function is the returned function result. By this definition, functions don't have side effects.
Why do functions and functional programming matter?
- Functions are a very nice abstraction. Looking at the input and output values gives you the complete information about the data flow. This makes functions very easy to reason about.
- With the absence of side effects, you also have no unintended side effects, which plague all code which modifies state.
- Functions are easily testable, they do not depend on an environment but just the function parameters.
- For the same input a function necessarily always returns the same result, this also makes reasoning about a programs behavior easier.
- As a consequence that they only depend on their inputs, functions usually are very composeable.
While for certain tasks, modifying a global state can be the most efficient way of performing a computation, functional programming does not have to be slow, and in many cases the resulting program might even be faster. There are several reasons for this:
- With the lack of side-effects, functional programs can be relatively easy parallelized.
- With only local state involved, compilers can optimize the code inside functions more aggressively.
There are pure functional languages, but most modern languages allow you to write your program in a functional style. So it is possible to mix functional with object oriented programming.
This plus the fact that the "function" is also the most basic way to describe operation on data means that you can build any kind of operations, data structure, program construct as you please like lego.
This is at the same time, imho, the weakness of the paradigm when used in industry : it gives so much freedom that two programmers will solve the same problem in different ways, making it harder to share code. Not everyone has the desire/patience to understand the many flavors of solutions proposed by the colleagues.
I don't know if this relates or whether I'm misunderstanding, but one approach to impose a bit more structure on the functional approach that I rather like is 'behaviours' in Elixir (and Erlang?):
What do you think the solution is? Not being snarky here; I'm genuinely interested in the problem you've described, because this unbounded freedom bothers me too.
My immediate thought is specifying the requirements for the input and output desired. This is something I thought a small bit about when learning Haskell. It's easy enough to search on Hoogle[0] by type signature to at least narrow it down, but then you have to look through all sorts of functions to see if the semantics are correct. Then, one may think, perhaps having search functionality to pass a collection of inputs and outputs and run any relevant functions that have a valid type for the inputs and outputs. However, that could take longer to compute than just writing the function in the first place. It also gets complicated because perhaps what you need is a composition of functions (map reduce, filter map, etc.), so now how do you know when to stop composing functions to get the desired output? I'm not smart enough to know if there's a general solution to this (other than simpler cases of cycles).
I would also really like more insights into this. I'm working on a toy project dealing with bytecode and being able to interpret the semantics of a series of instructions reliably would be very handy. I believe if the above has any practicality then it would help my problem.
Not who you replied to, but I, personally, think it boils down to trust. Using someone else's code, _especially_ if it's functional, should be the same as using the proverbial black box. You shouldn't need to understand their code in order to use it with your own. The same should be true of your own code, really. You shouldn't need to remember implementation details of a function you wrote in order to use it in elsewhere in your code.
I know there's then the issue of security, freedom, openness. . .whatever. But if you're working on a project with someone else, and you don't trust them, the project's probably doomed to fail to begin with.
Discipline. A lot of people dislike bondage and discipline languages like Ada. But one of the reasons for those languages was that it enforced discipline. This made it very compelling from a systems engineering perspective.
Languages that permit more freedom for programmers require the programmers, themselves, to practice discipline. This requires attention to detail, up to date documentation, and effective communication. Those things require full-time staff, beyond just the programmers, to facilitate. And, really, you need to have systems architects/engineers to be making decisions or guiding decisions with a heavy hand.
I dunno :-( I think there's a permanent tension between creativity and norms... But my guess is that not everyone is wants to cope with that. Not everyone wants to discover yet a new solution, yet a new style each time he reads some code. Personally, I love that but given the success of, say, Java, I'd say there are people who prefers more guidelines. And this has nothing to do with IQ or coding skills or anything, it's just personality I think.
Worth mentioning that when you're dealing with pure functions that by definition avoid side effects, and your application somehow requires side effects. Most of the time you can solve this by pushing side effects from the pure code, so your functional code is decoupled and more manageable.
> The core of Functional Programming is thinking about data-flow rather than control-flow
I've spent a small amount of time trying to convince people that FP is a byproduct of immutability and not much else. But I like this description better than that. I like that it captures the idea of dependencies. Data flow, and FP, are about explicitly passing all the required dependencies into any step in the process, and getting back all the results - as opposed to having any implicit inputs or output. Making all dependencies explicit will force you into writing immutable code, and likewise writing exclusively with immutable data and functions that dont have side-effects will automatically make you spit out code with explicit dependencies as a byproduct. These are two sides of the data-flow coin.
I also like that the focus on data-flow makes it clear you can do FP in any language. Some languages definitely help you, but you absolutely can practice data-flow over control-flow in C and assembly almost as easily as python. It's just tempting not to when you don't have to, being more strict about FP takes more self control.
Data flow, and FP, are about explicitly passing all the required dependencies into any step in the process, and getting back all the results
I always knew there was some relationship between FP and dataflow. There is something profound here. However, I'm not so sure that current FP languages are capturing this something in the best possible way. To me this:
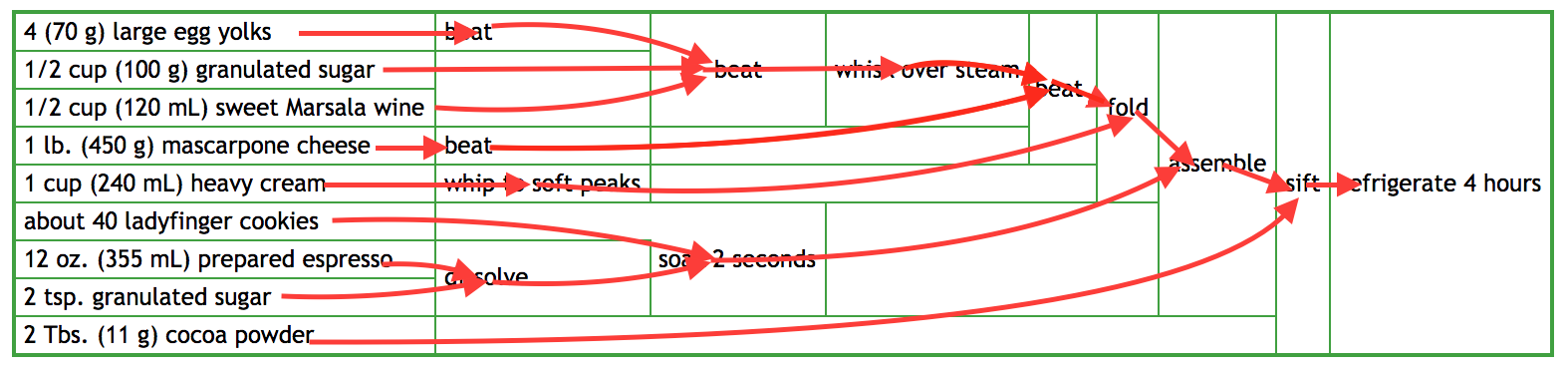
It reads a lot closer to the recipe, though the nested multiple operations are still a bit hard to read. Separating them into their own named functions would probably be better.
My first love was computer graphics and multimedia, the only software I liked were ones that:
1) had features called virtual entities: you don't crunch bytes, you manipulate the concepts, and only when needed you compute
2) non destructive edition: since 1) you can pile up operations without ever fearing loss of information, or memory usage for backup. The first audio editing software I had was Sound Forge, a simple one, every operation meant allocating a new space, computing, filling. This meant limited undo and higher resource requirements
3) from 1 and 2 you get laziness
(examples: nothing real shake, sidefx houdini, alias wavefront maya, sekd samplitude, anything by discreet. All these made far better use of your hardware. Compared to famous but non lazy ones such as Sound Forge or 3dsmax .. your poor desktop became pro tool (sic). Well until you hit the final render button of course)
Later I discovered FP and I laughed nervously.
Also many many highly rated CGI software use dataflow on a lazy DAG. GHC uses this for sharing computation in the evaluation model.
> The Racket doctrine tells developers to narrow the gap between the terminology of a problem domain and general programming constructs by creating languages instead of just plain programs. This pearl illustrates this point with the creation of a relatively simple domain-specific language for editing videos. To produce the video proceedings of a conference, for example, video professionals traditionally use "non-linear" GUI editors to manually edit each talk, despite the repetitive nature of the process. As it turns out, video editing naturally splits the work into a declarative phase and an imperative rendering phase at the end. Hence it is natural to create a functional-declarative language for the first phase, which reduces a lot of manual labor. This user-facing DSL utilizes a second, internal DSL to implement the second phase, which is an interface to a general, low-level C library. Finally, we inject type checking into our language via another DSL that supports programming in the language of type formalisms. In short, the development of the video editing language cleanly demonstrates how the Racket doctrine naturally leads to the creation of language hierarchies, analogous to the hierarchies of modules found in conventional functional languages.
I tell people it's about focusing on inputs and outputs rather than worrying about inputs and side-effects.
It let's you develop complex programs with clear separation of responsibilities without having to try to keep the model of the entire state-space in your head at once.
Yeah, I find that pure functions (or pure functions living in immutable objects) makes my code immensely more composable and easier to work with (i.e. more adaptable and less expensive to own). If some business requirement changes I can recompose and tweak existing code without reading every line of code to figure out what side effects may unintentionally get triggered.
I never really properly learned TDD and always felt a bit bad about it. Then I discovered this side effect (or primary effect) of FP and felt like there was no real need for tests. Not sure if I'm just rationalizing but the ability to drop into the data flow and make changes or add features with confidence makes programming so much more fun.
The thing that stops you from doing data-flow freely in C or assembly is ownership of memory.
In a GCed language, you can freely your parameters into a complex returned structure; without GC, you can't mix up ownerships without a separate accounting system.
If you're writing functional code, the return values of your routines will normally be a function of the parameters, which often means wholesale inclusion. Without GC, you need to do a lot more preemptive copying, and freeing the resulting data structures is much more painful.
Alternative accounting systems can be used, e.g. arena or marker based allocation (freeing everything allocated when control returns to earlier points on the stack), or something else more involved. But it's not free.
C++11 allows you to write natural "value-oriented" code without paying a copying cost. This is thanks to RVO (return value optimization) and move semantics.
I do like that too. lambda is just "I need this and that for the body to make sense".
I also like that providing partial dependencies isn't an error, but yields a smaller-dependencies lambda (thanks curry I guess).
But more and more I go away from functions as a thing. Scheme compiler turn lambdas into goto+args, Prolog made me think of programs as forest/graphs that you walk... and yes if you look at functions as dependencies then you end up as a description of a dep. graph.. so graphs again.
> Do FP using Microsoft BASIC, circa 1980 or thereabouts (heck, if you want, use any BASIC from that era).
Well... anything without higher order functions & currying is gonna struggle with _beauty_ when it comes to Functional Programming... And Basics type system wouldn't be particularly enjoyable in the context of serious development...
That said, and supporting the OPs point: mapping the required functional data transformations, establishing a flow of transformed data, and producing code to support that transformation is highly achievable in typed imperative languages. In fact, it would be right at home in Basic...
Creating immutable, side-effect free functions in Basic that are then chained on matching output types and input types, and composing those functions in a control function, would look much closer to "bog standard" Basic than attempting OOP in Basic does. In fact, to a trained imperative Basic developer, it would look like very clean, composable, code that had logical and contained GOTOs and a well-reasoned strict relationship to changing data in incoming parameters...
You would not have any language support forcing you to Do The Right Thing, and there would be oodles of temp variables smart FP languages just compose away... but to do FP in MS Basic ca 1980? Just grab some imperative Basic, strip the side effects, and you're done. Basics later modules are a great conceptual match for Haskell and OCamls modules, too...
> I'm pretty sure FP would be easier to demonstrate using Logo from that period than using BASIC.
Logo is a LISP dialect created to teach (functional) programming and logic, so that claim would apply to lots of languages IMO :)
I think the idea that FP isn't highly grokable in imperative languages is a symptom of the biggest problem with functional programming: it's both far simpler than we imagine and more complex.
:) You sure you disagree? I said both, and the most important part is it works both ways. That's why I like the data-flow point of view; it more naturally gives rise to thinking about both immutability and explicit dependencies, and helps to avoid arguments over whether immutability is what defines functional programming.
Indeed I reacted a bit too quickly !
You are right.
You were even going straight to the point when saying that "These are two sides of the data-flow coin."
I would say that the opportunity to freely share values without needing to defensively copy is of greater benefit, especially with an increasingly multicore future. Updating in-place also requires memory barriers, which don't scale.
Surely immutability works well when sharing values that shouldn't change anyways, in functional or other styles of programming.
What we are talking about here are immutable data structures that replace mutable ones, where mutability is pushed off to a higher reference cell (so instead of having a mutable set, we have a mutable variable that points to a new immutable version of the set). In both cases, locking is required if thread safety is desired.
> so instead of having a mutable set, we have a mutable variable that points to a new immutable version of the set
This is not at all how functional data structures work. You're assuming that the data structures are the same as non-functional data structures, but merely without the ability to mutate them. That is not correct. Proper functional data structures are implemented completely differently.
One obvious exception to this is the Swift language, which is not really a functional programming language, and it does not have functional data structures. It uses copy-on-write which is somewhat similar to what you describe, but is not how functional programming languages do it.
If you want to keep track of world-current, then you need a variable that changes from world-0 to world-1 somewhere. Conceptual mutability (change over time) doesn't go away because you are using immutable data structures.
> If you want to keep track of world-current, then you need a variable that changes from world-0 to world-1 somewhere.
Putting on my FP hat: if you need the state of the current world then somewhere you need a side-effect free function that can report that state. If you're managing that state over time then you'll need other functions to handle that stream of immutable data.
Conceptual mutability very often isn't a change of data, it's a change in usage/reporting context.
And since we're in FP land we could compose those input and handling functions together and splay them across infinite vectors in both directions creating infinite functional chains of potential data interactions that are only calculated on demand based on incoming data. We can be highly confident that those calculations will scale from 1 to 1 million CPUs/machines. We can be highly confident about state-based testing of future states (a la Y2K bug). We can formally verify system behaviour and the underlying data flow. We can also safely and logically match those flows to new and interesting transformations through exhaustive pattern matching with guarantees that we are not impacting the current system behaviour...
Granted: there are likely mutable variables somewhere in that turtle-stack, but the overall systems relationship to state will not be impugned by them as long as they are appropriately contained.
In functional programming one should model change over time as a stream of immutable values, there is no "conceptual mutability" and no need for mutable variables.
Mathematics has successfully modelled change over time for hundreds of years without mutable memory cells in a computer.
Please don't build software that mutates my data. I want history/provenance and reproducibility. I don't mind the odd bit of optimisation, but your use of the phrase "conceptual mutability" would have me worried if I was a customer of yours :)
Of course, I'm a researcher who deals with this field daily, I'm not going to be your ideologue functional programmer who meets your ideological criteria for twisted language with a poor understanding of the wider field.
Less of the insults please, I've spent most of my career trying to escape the 'wider field'. The way we choose to model the world is clearly very different.
I did say they were rarely needed, if one does need interthread communication then yes an MVar or two will probably be used under the bonnet somewhere. Threads can however be used without MVars. Haskell offers many concurrency and parallel programming primitives.
Compare with C++ where every smartpointer holds mutable state (even if it points to a immutable value) and triggers a memory barrier whenever it is accessed.
You do not understand how immutable data structures work; you are thinking about them from the context of mutation when they are very much not based on that mode of change. They are entirely different ways to organize data, and the implementations are quite different from what you seem to think they are.
Strongly disagree. You can do radically less copying when GC is available. Yes, the graph needs to be traced eventually, but we know how to make GC fairly fast, especially if we can afford more memory.
A major benefit of immutable data is worry-free sharing, and it's how you make persistent data structures fast. You simply can't afford to copy the whole world on every update.
There are some performance implications with NUMA, but there aren't serious multi-threading problems with immutable structures. Immutability means there isn't anything to race with, as long as initial construction is retired properly before other threads see anything, which is a compiler / runtime implementation problem, not an end user programmer problem.
You really should read up on the implementation of FP data structures in languages like Clojure or Haskell before making statements like this. You sound silly. Clojure's immutable data structures are thread-safe, fast, and quite different than your apparent idea of what these kinds of data structures actually are.
That is not how functional data structures work. Check out Okasaki's book "Purely functional data structures" if you want to know what we are talking about here. There is not a whole copy of data being made. They use structural sharing and there is almost never a need for the implementation to make a data copy. You can have a piece of data that "changes" as it passes through the data flow, but in reality very tiny changes are actually happening behind the scenes, even if the perception to the programmer is that large changes are happening.
I know what you're talking about. I simply disagree with you. Not about "purely functional data structures", but about implementation details and how computation occurs in actual practice, in the context of their use.
> I've spent a small amount of time trying to convince people that FP is a byproduct of immutability and not much else.
I'm not sure that's true in general; although it seems to hold in FP languages and FP-style in imperative languages, where we have "function-like things" (functions/subroutines/methods/etc.), an implicit 'arrow of time' (a sequence of instructions, irreversible reduction rules, etc.), some notion of "values" which can be passed around, mechanisms for naming/referencing/substitution/etc. and other such "ambient" language features that we might not think about too much since they're present in most mainstream languages.
If we step back from this imperative(-like) mainstream though, we find things like Prolog, miniKanren, SQL, Joy, Pure, Maude, Eve, Church, Unlambda, etc. whose semantics are based on relational algebra, answer-set programming, probabilistic programming, theorem proving, term-rewriting, stack models, etc. If we consider mutable vs. immutable variants of these languages, I don't think we'd find that immutability gives rise to FP as a byproduct.
For example, relational languages don't have a construct corresponding to functions; they have relations, which are more general since they are many:many rather than many:one. They also don't distinguish between "inputs" and "outputs", which allows relations to be "run backwards" (e.g. using `plus(5, x, 8)` to perform subtraction, with the result `x = 3`); this muddies the 'arrow of time', allowing a single "reduction step" to expand an expression (and perform an arbitrary amount of search in the process!). Such things are perfectly immutable (AFAIK languages like miniKanren enforce immutability, in a similar way to Haskell), yet I wouldn't call them "functional programming".
Similarly, the idea of "values" (and therefore referential transparency) can become murky: do we mean that an expression always evaluate to the same object-level term, or that querying an expression always chooses from the same set of possible terms, or that sampling an expression always draws from the same distribution over terms?
I've come across this 'murkiness' in the real world via Haskell's popular QuickCheck library, which provides a `Gen` monad that violates the monad laws: when given the same random seed, functions which should be equal may return different values. Yet `Gen` is "morally" a monad, since the probability distribution of those functions across arbitrary seeds is equal: https://hackage.haskell.org/package/QuickCheck-2.10.0.1/docs...
From the point of view of "writing my language-X project in a more functional style", I think going after immutability captures most of the idea, assuming "language-X" is some popular imperative/FP language. From the point of view of "language-X is functional because...", I don't think immutability captures much of the essence of FP at all.
A very nice overview; whilst the author is right about having to 'linearise' the block diagram into lines of text, it might be worth mentioning that the diagram is a perfectly valid way of drawing a tree, and that tree is (as far as I can tell) exactly the syntax tree of the 'big expression' (the version which doesn't put intermediate values into variables)!
Another nice point about the 'big expression' version: even hardcore imperative programmers tend to avoid relying on "horizontal" order of execution, e.g. in `f(x, y)` it's frowned upon to rely on either `x` or `y` being evaluated first; the order is even undefined in some languages (e.g. C). Hence the dependencies are clear from the nesting, whilst adjacent expressions can be assumed to be independent.
FYI I wrote up my own advice at http://chriswarbo.net/blog/2015-01-18-learning_functional_pr... which echoes some of the points in this article (e.g. FP is a style applicable to many languages; there's a spectrum from "less functional" to "more functional", and it's fine to pick and choose for your situation; etc.)
I love programming in a functional-style in Python.
I create one-way functions. Every input will always give the same output.
Then I build out the test harness for that function, to unit test the function, and pathway test it. So I make sure that I have automated tests to capture every single extreme that can go into the function.
I do this for every single function created. Then I string together one function into another, and I put that into its own function. And I unit test that larger function. Then sometimes, I even put those 2nd level functions, into more functions. And I unit test that as well. In the end, I just have a function that calls a function, that calls a function, and so forth. The rabbit hole just goes deeper and deeper.
If I ever need to enhance a function, then I make my changes, add more unit tests, and re-execute it. The impact is always local, and I have full confidence in my unit tests and pathway tests.
I'm always incredibly amazed when I execute the program, and it works flawlessly, every time.
I keep iterating through the development cycle this way. And every version checked in, is fully tested, very accurate, with detailed test logs captured, and most importantly, it does not crash. It's beautiful.
With Object-oriented programming, I have to maintain an external state. This is like modifying a global variable within your object. Your methods have to load and manipulate an external variable. And then another method will modify it later.
However, I do like the organization and hiding ability of OOP. So in the end, I just make all my functions as a functional-style, one-way function. And my methods are just wrappers around it.
My main complaint about Python, is that it's just slow. I wish it had a compile to binary feature built in. Although, I get around that with my heavy unit tests, but some coding mistakes can be easily caught during compile time.
Check out Nim, it's got python style syntax, but it's statically typed and compiles down into performant C and then into a binary.
I've been converting a lambda function used at work from Python into Nim[0]: I've had very few issues so far and the performance gains are fantastic (Admittedly my lambda function is pretty straightforward, but still).
It's also got support for functional programming styles, with a function composition operator/first class functions etc[1] and a pragma to tell the compiler that a function has no side effects[2].
"With Object-oriented programming, I have to maintain an external state. This is like modifying a global variable within your object. Your methods have to load and manipulate an external variable. And then another method will modify it later."
I like to interprete state as just another input and/or output variable.
This way you can test your object member functions while pretending they are FP functions.
I've been paying attention to functional for the last 6 or so months and coming from a C background, its emphasis on immutability, data-oriented, readability, and safeness is really attractive if you're not worried about performance (which is allowed to take a back seat in most apps these days). I can't wait for software to be improved harboring the benefits of functional programming.
There's no reason you can't realize some of these benefits in C. I wrote a program recently that produces a new struct every time the state changes (any function that changes the state is passed the current state struct by value and returns a new state struct.) While part of the state is a multi-gigabyte memory allocation, this is represented as a pointer, so copying it from state to state is very cheap. This means that all of the structs point to the same chunk of memory, so only one of them can be considered valid at a time. I found that this approach made it very easy to keep track of what state my program was in. It greatly simplified error handling because I could just discard a failed update rather than trying to unwind it.
You're correct. I've been writing C lately with functional concepts in mind and noticed an improvement in cleanliness with state and style. I'd definitely recommend trying it to other C developers.
In 1962, the IBM 704 was the first computer running Lisp.
So given the hardware we have nowadays, unless we are doing some critical real time stuff, there is little reason for FP like programming not to be fast enough for 99% of most use cases.
The articles emphasises that one of the main arguments in favour of FP is that it's easy to see what part of the recipe can be done in parallel. Why can't the runtime automatically leverage multiple cores and speed up the process ?
Immutable persistent data structures used in FP tend to perform slightly worse than their "conventional" counterparts. So if you can manage to run your non-FP program in parallel with a shared mutable data structure and no synchronisation you should see better performance.
In practice, however, you'll almost certainly need synchronisation on mutable shared state and it might very well be slower. So neither approach is per se faster than the other.
There are ways to encode imperative mutable updates to data structures in a functional style with tail calls and sufficient compiler smartness. I don't think you really come out ahead if you go down that route though.
To sum it up, it's a kind of chicken-and-egg. Imperative/OO is tied to the physical implementation of processors, whereas FP is tied to a mathematical construct for which conventional CPUs are not optimized.
Modern hardware struggles to impersonate a C/C++ abstract machine too. Machines with multiple cores and distributed memory hierarchies are difficult to program effectively with old OO/imperative languages.
It's easier to move an object 1 cm to the left than it is to bootstrap a universe where the object happens to 1 cm to the left.
> Why can't the runtime automatically leverage multiple cores and speed up the process ?
That is more related to proper dataflow analysis than immutability, and this is much more mature in VM runtimes that are actually used (hundreds of man-centuries vs. the odd PhD thesis).
Erlang/elixir's runtime, OTP (open telecom platform) will do this. It can scale to multiple cores, or across multiple machines in a network, almost effortlessly.
No. The reason? In the nano second to 1 microsecond range your CPU already automatically parallelises your code by using out of order execution. Unless you're wastefully busy waiting, the latency of issuing a new job to a second thread is in the 10s of microseconds. You can't just issue new job without first knowing how much time the job is going to take and whether it's even worth it to parallelise it. Profiling every line of code at runtime will introduce even more overhead. It's far simpler to just let the developer annotate the parts of the codebase that should run in parallel.
Example: r=a/b + c*d can in theory be parallelised but you'd have to pay 10 microseconds in overhead which is likely more than 5000 times slower than just running it on a single core.
TL;DR automatically parallelising a program is trivial, making a parallelised program run faster than a non parallelised program is not
In principle pure functional programs can be freely parallelized, but in practice it's hard to do it completely automatically without losing more in overheads than you gain through parallelism.
In Haskell I think the standard approach is still to annotate your code, indicating which parts should be evaluated in parallel. See https://wiki.haskell.org/Parallelism
Even if all of your functions are pure they can still have data dependence with one another. So you obviously can't parallelize foo(bar()) automatically. There are other things that can make a real mess of paraellizability too, like error checking.
Say you have some code like:
comprehend all item in list,
verify(item) or errorout("failed at ", stringify(name(item)))
The compiler can't auto parallelize it because the exit condition is unknowable, at least if you want there to only be a single exit from the function.
You can get around this with even more strict requirements, but after enough of these restrictions even simple tasks start to get hard.
Some do. But more importantly, if your runtime doesn't, then it's still more obvious how to add parallelism, and more self-contained when you do.
Let's say you were using asynchronous IO in a functional style; not even full-on monads, just async/await like in C#. Since you have explicit data dependencies, you can easily see where the `await` is unnecessary, or coalesce multiple calls into await Task.WhenAll(...).
var slow = await conn.Query(@"slow query");
var fast = await conn.Query(@"select top 1 * from some_table");
var emailresult = await SendEmail(fast);
return (slow, emailresult);
Instead of awaiting `slow` before continuing with `fast`, it's fairly obvious that you could start the task and not await it until the others have already kicked off:
var slowTask = conn.Query(@"slow query");
var fast = await conn.Query(@"select top 1 * from some_table");
var emailresult = await SendEmail(fast);
return (await slowTask, emailresult);
That way, your email sends almost immediately, since line 1 never relinquishes control flow and just continues straight on. Then your `await slowTask` only blocks the return, instead of the entire function. This is pretty big if you're lining up a hundred slow IO tasks.
Note: while async IO gives you the actual parallelism, it's only because of the explicit dependencies that we are able to see which parts can be done simultaneously. I've been coding like this for so long I can barely imagine how to do it imperatively, but if you exposed an interface like `async Task GetSlowQueryResults()` and `async Task SendEmail()` using internal fields for intermediate results, it's utterly opaque and you can't tell which has to complete first.
Edit to respond better to your actual question:
There's a kinda big problem with auto-parallelizing, which is that in FP, outside of IO, everything is parallelizable. Spinning up threads or even shuffling data within a thread pool is pretty costly, so most attempts at micro-parallelizing everything haven't gone anywhere. You can annotate things in Haskell to run in parallel, or simply choose a parallel map or parallel reduce instead of a sequential one.
On the other hand, when spinning up threads/processes/jobs is relatively inexpensive compared with the cost of actually computing things, the idea is very successful. Take Apache Spark. You write a program in functional Scala or Python, and the scheduler will automatically distribute work over your cluster if it's big enough to warrant it. The scheduler also makes note of where intermediate results are, and will happily cache, reuse, shuffle or partition them around to continue on with the work. The engine essentially evaluates a DAG, with some optimizations for transport/persistence costs.
It seems obvious to me. All the copying of immutable data.
To turn the question on its head you could ask, "why are GPUs or DSPs so blazingly fast?" Part of the answer is they do a lot of operations "in-place", treating data as mutable wherever possible, in parallel, using heavy pipeline optimization to trawl through and update memory in place, sometimes using "modulo addressing" modes to make hardware-supported FIFO structures.
These techniques are all aimed at reducing the number of memory fetches, cache misses, etc. I don't know how FP languages are implemented at the runtime, but I'm guessing they don't go to these extremes.
Immutable data does not necessitate copying the entire structure when it is shared or changed. I encourage you to take a look at persistent data structures[0]. Okasaki's "Purely Functional Data Structures"[1] is a good resource if you'd like to look at this in more depth. Rich Hickey's talk about the implementation of persistent data structures in Clojure is also a nice introduction[2].
Only skim-read so far but that's interesting stuff. I had no idea FP data structures were implemented like this: I consider myself duly educated, thanks!
Because sometimes this is a win, but sometimes the overhead of forking off a separate thread and synchronising on the result costs more than the benefit. Compilers are very bad at figuring out which is which. Haskell lets you add parallelisation instructions to tell the compiler which is which without changing the semantics of the program.
Yep. I wanted to try some immutable data work so I looked into using an immutable library in Ruby (Hamster) but it was so much slower... so I went to Elixir and never looked back
Functional programming makes compilers nicer to work with, because you can tell them explicitly when locality can be assumed.
All compilers which do any kind of optimization have to reason about the code as if it were functional. Otherwise, they couldn't rearrange mathematical expressions and do things like common subexpression elimination or constant folding or even simple algebraic rearrangements we expect to happen because we, as humans, know that mathematical operators are are functions and therefore side-effect-free and therefore can be switched around arbitrarily as long as the end result is correct, because the end result is all that matters.
But a compiler which could only optimize arithmetical and algebraic code would be worthless. How about memory accesses? How about function calls in tight loops? And that's where you run into problems in a language like C, where strong assumptions about who gets to look at what generally don't hold. Optimizing memory accesses is hard because you don't know who's looking at the memory in a global sense. Spooky action-at-a-distance crops up, the kinds of things humans don't cope with well because the effect could be many pages of code removed from the cause. C has the volatile keyword for some instances of this, which basically kills optimizations for certain variables, but the general problem stands: C is unphysical. Locality cannot be assumed. Humans don't deal with that very well.
In a language like C, therefore, there's a tension between generating optimized code and generating predictable code, and that tension comes from the fact the compiler doesn't know which code could have side-effects and, therefore, invoke spooky action-at-a-distance if it's optimized too aggressively.
In Haskell, or any other language where side-effects must be explicitly marked, that problem goes away. Most code is purely local in its effects, and only special code, written inside a special monad, can invoke nasal demons if the optimizer gets too frisky. The compiler can trace its data-flow graphs and do all kinds of tricks secure in the knowledge that nobody outside can peek in to see how the sausage is being made. Only in special, marked locations do the values get exposed to the outside world, which must be done in an orderly fashion.
So all code is potentially functional. Functional languages just make it possible for the developer and the compiler to agree about precisely which code that is.
> ...Optimizing memory accesses is hard because you don't know who's looking at the memory in a global sense...In a language like C, therefore, there's a tension between generating optimized code and generating predictable code, and that tension comes from the fact the compiler doesn't know which code could have side-effects and, therefore, invoke spooky action-at-a-distance if it's optimized too aggressively.
I get this argument for functional languages and Haoyi's description for functional style, by writing down the expression tree not just one possible serialization the expression tree, was excellent); both the freedom to access memory and the lack of richer information about possible execution orders makes it more difficult for automatic compiler optimizations. I have definitely bought into writing C in a functional way when using local variables.
However, the lack of some compiler optimizations due to memory aliasing guarantees is not always a disadvantage. Like bootstrapping a compiler, taking advantage of new processor features, doing an inherently sequential task like state machine parsing, or even if you just enjoy thinking about data and algorithms at a low level.
What imperative languages need to remain competitive is richer type systems regarding objects with pointers into the heap. And this is no secret; languages have been experimenting with this forever. C++'s attempt with object oriented programming was a good stab in the dark but clearly has limitations, with the explosion of type information regarding things like exceptions and wart covers like move semantics.
What I would like to see is a language with weak typing and free pointers like C, but with a more capable, generic type system with concepts, like that described by Alexander Stepanov in Elements of Programming. Also object orientation as a language feature should be replaced by [some syntactic sugar + generic functions + function overloading + linearish? types] to make OO style easier than it is in C.
Things like memory aliasing optimizations would be managed by generic functions and type concepts provided by STL like libraries.
Perhaps it makes me a slower, less productive programmer but I like imperative programming and access to memory. That is the part I enjoy.
I fully agree that there's a time and place for explicitly sequential code. I just think that it's safer for everyone if it's explicitly marked as being sequential, so compilers know that most optimizations are now off-limits.
This seems like a reasonable compromise if people are interested in a language that can do both. Using C's syntax, a language could modify the semantics of terminators , ; : to indicate strict/total ordering of statements.
Eh, er, em, I kinda want to concede the point, but no.
I'm trying to draw attention to the algebra of programs. The subtitle of Backus' paper is "A Functional Style and its Algebra of Programs". I just skimmed the wikipedia article on Functional programming and it's not really mentioned at all that I saw.
Everyone seems to leave it out, but it's arguably the most important part of FP.
You can do wonderful things in Joy (Manfred von Thun's language) which is very close to Backus' FP system. This algebraic stuff is possible in most languages that are considered Functional, but it's much easier in a language designed for it.
My whole point is that defining FP as "programming with functions" or "programming with immutable data" or whatever is incomplete without the idea of being able to do algebra to derive programs.
Now, you can kinda do algebra with LISP and ML but they do not lend themselves to the algebraic approach with quite the ease of (Backus') FP or (Von Thun's) Joy. Backus introduced the terminology and the "higher-order" functions in that paper. I don't think people were talking about "functional programming" prior to that. To me, with my admittedly limited understanding and knowledge, it feels a little "revisionist" to go back and retro-actively anoint LISP as the origin of FP.
(LISP and ML have their own greatness, they don't need to steal John Backus' glory.)
If FP style becomes popular but everyone omits the algebra then it's not going to fulfill its potential.
The algebra of programs is the thing that Backus' FP emphasizes that's new from the context of LISP, et. al..
Let me try another tack: Why do you suppose Backus didn't write the paper in terms of LISP or ML? He knew all that, as you say, and this was his Turing Award lecture. Are we all really going to try to maintain that John Backus didn't have something new and interesting to talk about on this occasion?
I'm always surprised at the continued confusion of what FP is. I think that a lot of it is defensiveness about not wanting to lose whatever someones's favorite OO feature is.
In FP, nearly everything you like about OO exists except for one critical thing: global mutation. Even James Gosling, the creator of Java, encourages programmers to use mutation as a last option.
In other words, if you are programming well, you are nearly doing FP anyways.
>> In FP, nearly everything you like about OO exists
Is there an FP pattern that's analogous to an immutable object? The reason I like objects has nothing to do with mutability or state, it's the convenience of organizing a bunch of related functionality into a named class. When I instantiate it, I effectively get a named value through which I can access a bunch of functions that have all been closed over the same immutable values.
I dunno, I agree that data flow is important and maybe the most important part of functional programming. But the ability to sling program fragments (partial application, pointless functions, etc.) around as if they were data seems pretty important to me. I think of it as Lego-blocks for programs. If the program parts snap together real easy and the data moves seamlessly (or seemlessly-ish) from end-to-end then you're on the right track.
But I suppose there are many paths to functional programming... I have only followed one so far.
Therw actually are people that do program in such a 2D diagram type, it's called LabVIEW.
I recently had to work with it and while it was a pain to drag around these blocks instead of just using my keyboard, it really did give you a better idea of the data flow and made it incredibly easy to execute things in parallel. Just place two blocks on top of each other.
Its really just a practical application of the lambda calculus. Making it a different model of computation proven to be equivalent in power to the turing model.
Its requirements are to have functions of input variables to output variables, where variables can be functions themselves. And the ability to apply functions to values.
It contrast the turing model, which says instead that you have infinite variables that can be uniquely accessed. And a set of instructions which can read the values of variables at a given location, transform it, and write it back at a given location.
Functional programming made me start using static classes for manipulation and instances for basic array containers and cleaners. Besides that my job has memory heavy processing we try to keep low so to this date I can't see how immutable data wouldn't be more of a burden with lingering objects that are no longer used or need to be milled out. I did like how this article showed how returning a new variable represented the variables manipulation through name change.
I can speak for Erlang when coming to immutable data structures and the memory issue. Since erlang's processes are basicaly a recursive function, once the process dies or it calls itself (with tail-call optimization), unused structures dies out quickly. Also changing an immutable data structure does not make a whole copy but rather a "diff".
And since processes are completely isolated, garbage collection is easy (and doesn't hang the whole runtime), so the memory argument has been solved for some time, not by the language, but by the runtime.
I liked this article, but I feel like it's just a bit too. . .matter of fact. "FP _will_ make your linter do your work for you", things like that.
("Even if you haven't already-made a mistake, and are just thinking of making a change to a codebase, the # FP version of the code is a lot easier to think about than the # Imperative version" was particularly bad about this. I have never had a problem paralellizing a procedural program that would have been solved using FP)
It is _much_ better at being inclusive and not preachy than other articles of similar scope. But I would prefer if posts like this tried to explain functional programming without feeling the need to put down other paradigms. And, to be clear, I'm a big fan of FP, and have been using many of its tenants for a long time now.
Functional programming is just a different way to structure a code base. Some people are better able to grasp how data flows through a maze of functions. Some people are better able to grasp how an object interacts with other objects.
In the end, it's all just a sequence of instructions executed, in order, by a machine. The true correct way of writing code is: However you can get that machine to do what you want it to do, while still being able to make changes to its behavior.
Interesting perspective. After reading this article, if you want to use FP in your python projects, definitely check out the toolz library. It's got great API and really good documentation.
How come immutability is never mentioned? The only technical requirement for your program to be functional is for every variable to be immutable. That's really it. Every other functional concept is derived from this one rule.
If you genuinely think that then either the guy next to you is smarter than you, or is being a dick about what he knows instead of helping you understand.
I think the opposite. The smart people I knew from the old days could manage enormous imperative code bases in their minds and perform feats that seemed impossible to my lesser mortal mind.
Functional style was like a secret weapon I could use to keep up with them even with my lesser mental horsepower.
1) People feel, through experience, that writing code that minimizes mutable state and side effects leads to building systems that are more easily reasoned about, composed, and debugged, which is the job of the people thinking about FP.
2) Those people just want to look smart.
Geez--I know which of these makes a heck of a lot more sense.
There are people who act that way, yes. (They're not just in FP, unfortunately.)
But the value of FP doesn't depend on everybody using it being a wonderful human being. The value of FP depends on its ability to help you write (and maintain) programs. That value is real, even if some proponents are just wanting to feel smarter than you.
I think it's about gaining a different view of one's craft, a new way of looking at existing problems in a way that potentially provides an advantageous approach. And even if it never pans out professionally, well then, hopefully it's been a fun detour into a new way of thinking.
Oddly enough, I got the opposite impression: FP is about making complicated things simple.
There's some sort of epiphany that naturally occurs after fiddling with FP for a certain amount of time. After it winds down, your perception of how to solve problems changes drastically.
If only because of the increased awareness is worth the trouble to play with it a bit. I sincerely encourage you to do so.
Frankly, it's just a different way to think about structuring a code base.
Some people think better functionally, some people think better procedurally, but, in the end, it's all just a list of instructions, executed in order by a machine.
I'll never understand the need to poopoo all over someone else's way of thinking (not you, the guy you're replying to).
That's like saying monarchy and democracy are just different ways of structuring a society. Some people think better monarchically, some people think better democratically. Why poopoo all over someone else's way of thinking?
Honestly, I wouldn't respond to anyone who compares political systems with software development paradigms. Realistically, it's just really hard to compare the two directly, and anyone who says otherwise is trying to sell you something.
{kind=link}
{kind=link}
Why do functions and functional programming matter?
- Functions are a very nice abstraction. Looking at the input and output values gives you the complete information about the data flow. This makes functions very easy to reason about.
- With the absence of side effects, you also have no unintended side effects, which plague all code which modifies state.
- Functions are easily testable, they do not depend on an environment but just the function parameters.
- For the same input a function necessarily always returns the same result, this also makes reasoning about a programs behavior easier.
- As a consequence that they only depend on their inputs, functions usually are very composeable.
While for certain tasks, modifying a global state can be the most efficient way of performing a computation, functional programming does not have to be slow, and in many cases the resulting program might even be faster. There are several reasons for this:
- With the lack of side-effects, functional programs can be relatively easy parallelized.
- With only local state involved, compilers can optimize the code inside functions more aggressively.
There are pure functional languages, but most modern languages allow you to write your program in a functional style. So it is possible to mix functional with object oriented programming.