I warned about this back when all those new TLDs were being considered. Single-word TLDs are not properly supported in browsers, in DNS, or even at the glibc level.
At the browser level, is it a keyword or a domain? Try "ai". "ai" is a real domain, and there's a web site at "http://ai", touting the advantages of starting an offshore company in Anguilla. Most browsers interpret "ai" as a search term by default. If you enter "ai.", though, you've specified a rooted domain name (a feature few people know about) and should get the "ai" web site. Firefox understands this, but Android doesn't. Try various browsers.
At the glibc level, there's an exploitable bug, which I reported in 2012.[1] It's still open. The bug was first seen in 2011 and reported on serverfault.[2] The problem is that glibc DNS lookup has a feature which is supposed to allow abbreviating domain names. The idea was that if you're on "something.harvard.edu" and you look up "law", it tries "law.harvard.edu". The exploit is that if you're on "foo.com", and you look up "baz.com, glibc tries "baz.com.com". There's a domain "com.com", and it has a wildcard DNS server, so it will resolve "baz.com.com". What's there? A scam. "You are selected by G00GLE to be among the first few persons to win an iPhone 7...".
This behavior is a problem for all single word domains. Whether it is active depends on the hostname of your local host. It's mostly a server problem, but some ISPs issue clients hostnames such as "12345678.comcast.net", which means that "google" gets tried as "google.comcast.net". Fortunately, "google.comcast.net" doesn't resolve in DNS. Neither does "com.comcast.net" ISPs need to be careful about this.
(It's a big problem if you're writing a web crawler, which is why I know about it.)
It's a feature that should be off by default. It's only useful in corporate intranets, where the corporate DHCP and DNS servers could provide a search list for finding local servers.
Concerning http://ai and other such single word domains (e.g. those in intranets), from my experience, typing 'ai' in the address bar will perform a search, while typing 'ai/' will go to the domain.
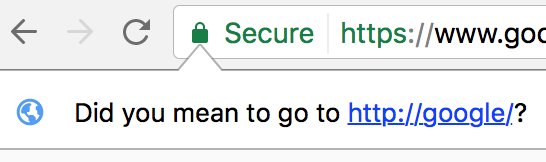
1) The prompt is pointing to the "Secure" icon; I thought it was asking me if I wanted to downgrade my protocol to HTTP.
2) The domain "google" made me and several others wonder if there was a hosts file entry for "google", which turns out there isn't.
No, of course, the real problem is much more complicated; a strange twist of omnibar meets DNS meets HSTS. This is definitely an edge case, but might be a glimpse into the complicated future of gTLDs and the emergence of ever-more web standards...
Or alternatively "the web is hard if you sacrifice any kind of structure to make a quick buck".
On the risk of sounding get-off-my-lawn-ish, but TLDs used to be assigned using some relatively simple, service-agnostic rules: A hierarchical system for ccTLDs, plus a small set of universal gTLDs plus some historic quirks. Nowadays assignment seems to be solely by who pays most.
I'm sure brands and attorneys love it. Now they have to defend Coke and Disney and their hundreds of associated domains across hundreds of TLDs. Think of the permutations.
Twenty years ago it was utterly unthinkable that anyone would get a corporate TLD. Today it's like "Why doesn't Coke have one?"
The ICANN has really gone into dark territory with this decision to open things up. It's fitting that their wiki logo is some unruly weed taking over the world: https://icannwiki.org
Now, let's make every program more user friendly by obscuring the meaning of our input fields and creating very complex rules for how they'll act... Oh, wait, our programmers aren't able to understand our rules anymore? Nah, we are an AI company, we can live with that.
/Insert grumblings about insecurity of the omnibox (leaking internal corporate data) and my personal preference for firefox-style URL box and search box.
Also, I find the firefox awesome bar much more powerful than Chrome's it does (fuzzy?) word search on every url and title in the history, and here always seem to give me more pertinent results than Chrome's (which seems to forget I visited a website in just a few days).
I've found this exact same thing as well - the FF awesome bar always seems to give me the results I want, whereas I have to do a lot more specific and manual typing to find what I want in the Chrome bar. This could be an interesting blog post I'd think: comparing the implementations of the matching algorithms of Chrome vs. FF vs. possible others.
You can get search suggestions in the Awesome bar (URL bar), but it asks you before it gets turned on.
(I personally always the Firefox search bar, but I also decline the search suggestions because they don't help me much. Instead I have 15–20 keyboard searches I use a lot.)
Honestly, although I use the Omnibox/Awesome Bar/whatever a lot, I think it is ultimately a mistake: there are too many search terms which end up resolving to domains, esp. for a developer — and it was never a problem to just click in the search bar before I ruined my muscle memory and started clicking in the location bar instead.
One of these days I'll just disable it altogether.
Technically yes, because like every other domain name, it can have an A record pointing to an address.
From a technical perspective, there's no difference between `www.example.com`, `example.com` and `com` having an A record.
From a best-practices standpoint, A records on TLDs aren't liked (just see this submission here when looking for a reason) and thus exist only very rarely.
Which spec is this? As far as I know `http://google` is completely fine, and the period at the end is only necessary for the browser address bar heuristics we're talking about. `http://to` was operated as a URL shortener for a while.
So if there was a host on my network named 'ai', http://ai would resolve there (The terminating dot being standard to indicate a fqdn, rather than a browser trick). This has been understood for a long time; rfc1049 gives us:
Relative names are either taken relative to a well known origin, or to a
list of domains used as a search list. Relative names appear mostly at
the user interface, where their interpretation varies from implementation to implementation[.]
I stress that last clause; dotless domains have no defined behaviour. "http://google/" may refer to google.example.com. (relative to my search list), google.com. (relative to a well-known origin), or google. (a fqdn). That's not browsers, or omnibars, it's been the vagueness of undotted-domains since the start.
Possibly. But with two complications - one is that there is no defined correct behaviour for undotted domains. All the RFC gives us is "implementation vary". Second is that this behaviour is inherited from gethostbyname(), so it's unlikely to change soon.
Technically the root zone has to have NS records. So even records without a label at all should work. of course you can not resolve them without a static zone configuration.
To whoever edited my title: The bug report title is inaccurate. It's specifically about HSTS preloads, which is why my original title stated that instead of "gTLDs".
If you changed a misleading title to make it accurate, then you were following the HN guidelines and we made a mistake in overwriting it. Sorry! We try hard but inevitably get it wrong sometimes. We've put your title back.
Regardless of the title editing discussion in the sibling comments, the title at the source was changed to "Omnibox hostname heuristics misunderstand internal redirects.", which accurately reflects the problem.
That's not what I understood of reading the posting guidelines [0] and especially "Otherwise please use the original title, unless it is misleading or linkbait."
If OP thought it was misleading, then he was right to adjust it?
Indeed the "title" of the original page is misleading (because the original bug submitter thought it was one issue, but was really another).
And that has had the effect that most of the conversation in this thread is about gTLDs instead of HSTS redirects, when the bug has nothing to do with the former (as noted by the comments where they specifically say that this does not happen to other gTLDs)
{kind=link}
At the browser level, is it a keyword or a domain? Try "ai". "ai" is a real domain, and there's a web site at "http://ai", touting the advantages of starting an offshore company in Anguilla. Most browsers interpret "ai" as a search term by default. If you enter "ai.", though, you've specified a rooted domain name (a feature few people know about) and should get the "ai" web site. Firefox understands this, but Android doesn't. Try various browsers.
At the glibc level, there's an exploitable bug, which I reported in 2012.[1] It's still open. The bug was first seen in 2011 and reported on serverfault.[2] The problem is that glibc DNS lookup has a feature which is supposed to allow abbreviating domain names. The idea was that if you're on "something.harvard.edu" and you look up "law", it tries "law.harvard.edu". The exploit is that if you're on "foo.com", and you look up "baz.com, glibc tries "baz.com.com". There's a domain "com.com", and it has a wildcard DNS server, so it will resolve "baz.com.com". What's there? A scam. "You are selected by G00GLE to be among the first few persons to win an iPhone 7...".
This behavior is a problem for all single word domains. Whether it is active depends on the hostname of your local host. It's mostly a server problem, but some ISPs issue clients hostnames such as "12345678.comcast.net", which means that "google" gets tried as "google.comcast.net". Fortunately, "google.comcast.net" doesn't resolve in DNS. Neither does "com.comcast.net" ISPs need to be careful about this.
(It's a big problem if you're writing a web crawler, which is why I know about it.)
[1] https://sourceware.org/bugzilla/show_bug.cgi?id=13935 [2] http://serverfault.com/questions/341383/possible-nxdomain-hi...