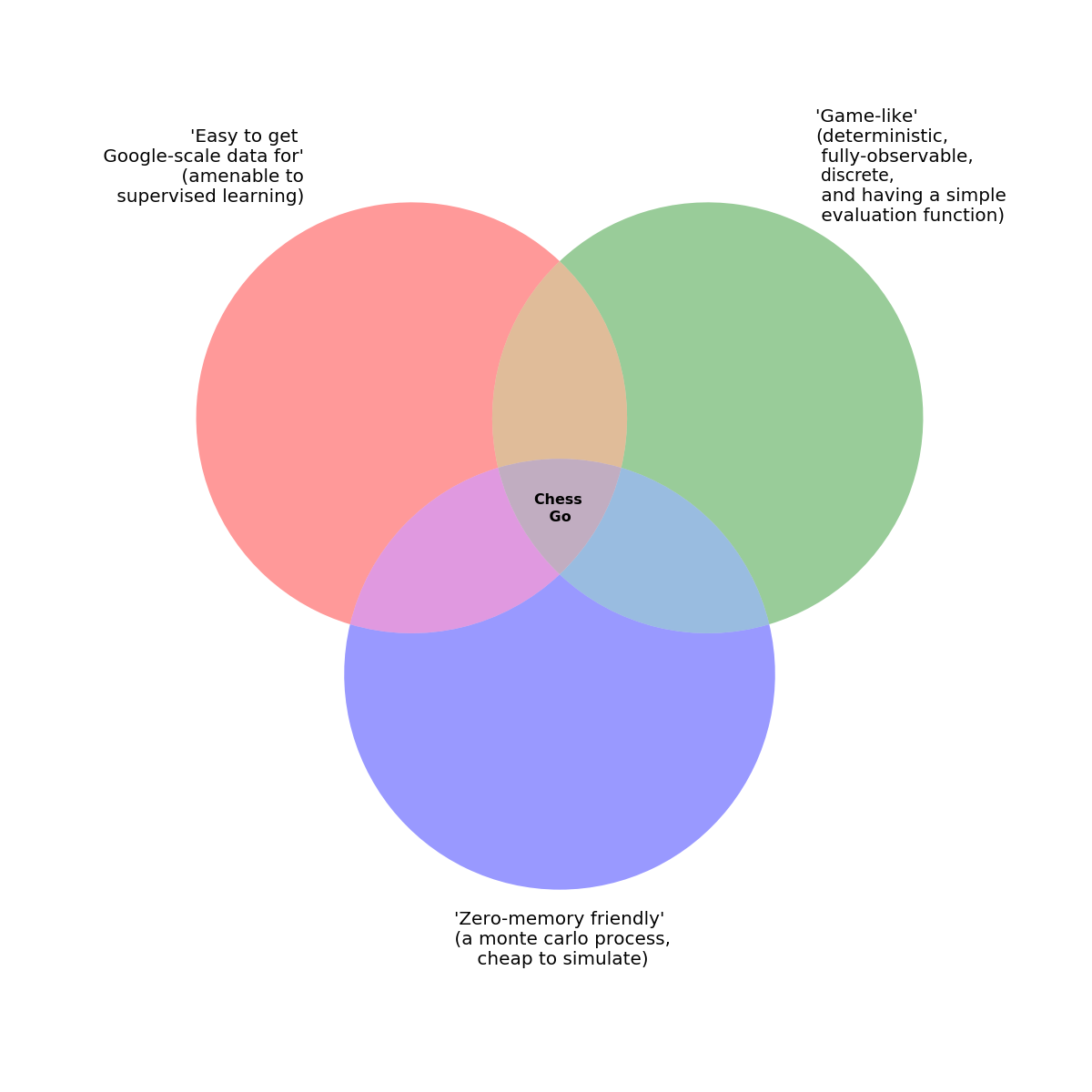
I suppose the question one could then ask is "will AlphaGo's approach wind-up being emulated over time or is it going to be something like a cul-de-sac?
How many single algorithmic challenges are worth expending this much effort on? Could AlphaGo's approach be applied to other such problems? Will increasing processor speed just make all this effort moot? Is AlphaGo something like Deep Blue (the custom computer that beat Kasparov and then was dismantled rather than being developed further)?
Still, the general ideas of supervised learning followed by reinforcement learning, training multiple models of varying complexities from the same dataset, and combining tree search with learned models as they did are useful general ideas. Hybrid methods as a whole will become increasingly common, I think (no doubt self driving cars already are very complicated hybrid models).
{kind=link}
I suppose the question one could then ask is "will AlphaGo's approach wind-up being emulated over time or is it going to be something like a cul-de-sac?
How many single algorithmic challenges are worth expending this much effort on? Could AlphaGo's approach be applied to other such problems? Will increasing processor speed just make all this effort moot? Is AlphaGo something like Deep Blue (the custom computer that beat Kasparov and then was dismantled rather than being developed further)?