This is so cool. Real-time accent feedback is something language learners have never had throughout all of human history, until now.
Along similar lines, it would be useful to map a speaker's vowels in vowel-space (and likewise for consonants?) to compare native to non-native speakers.
I can't wait until something like this is available for Japanese.
The approach in the article is roughly equivalent to having someone listen to you speak and then repeating back in their own voice so you can attempt to copy their accent. Certainly nice to have available on demand without needing to coordinate schedules with another human.
A good accent coach would be able to do much better by identifying exactly how you're pronouncing things differently, telling you what you should be doing in your mouth to change that, and giving you targeted exercises to practice.
Presumably a model that predicts the position of various articulators at every timestamp in a recording could be useful for something similar.
> something language learners have never had throughout all of human history
.. unless they had access to a native speaker and/or vocal coach? While an automated Henry Higgins is nifty, it's not something humans haven't been able to do themselves.
Native speakers are less helpful at this than you might think. Speech coaches are absolutely the way to go, but they're outside the price range for most people ($200+/hr for a good coach). BoldVoice gives coach-level feedback and instruction at a price point that everyone can access, on demand.
Not yet - this was our first technical blog post. You can check out the BoldVoice app and test out the sound-level feedback yourself. Or watch this app walkthrough video - https://www.youtube.com/watch?v=3Sv5K4Z9P4c
You can take a language class rather than have a personal instructor. Although accents are a sensitive topic so I don't remember mine going into it much.
As someone who took English classes for years growing up, I wish that were the case. In fact, most teachers don't really know how to teach pronunciation. Also, in a typical group class setting, it's challenging to give each student one-on-one feedback. On BoldVoice, we solve that with 1) unlimited instant feedback from sound-level AI - your most patient coach. 2) in-depth video lessons from the best coaches in the world (Hollywood accent coaches). I'm a cofounder of BoldVoice, by the way. :)
Try learning a language where they won't understand you with a foreign accent. I assume tonal languages are like this but haven't tried learning any.
Japanese is sort of like this - you have to say foreign words the Japanese way very forcibly, to the point that Americans will think you're being racist if they hear you do it.
That's a fascinating idea! Definitely something to try out for our team. We actively and continuously do all sorts of experiments with our machine learning models to be able to extract the most useful insights. We will definitely share if we find something useful here.
This is partly completely misleading and partly simplified, when it comes to SOTA LLMs.
Subject–Verb–Object triples, POS tagging and dependency structures are not used by LLMs. One of the fundamental differences between modern LLMs and traditional NLP is that heuristics like those are not defined.
And assuming that those specific heuristics are the ones which LLMs would converge on after training is incorrect.
Yes, tokenization and embeddings are exactly how LLMs process input—they break text into tokens and map them to vectors. POS tags and SVOs aren't part of the model pipeline but help visualize structures the models learn implicitly.
The non-novamin Sensodyne was tested at 116ppb for lead and the tester listed the concerning ingredients: hydrated silica and titanium dioxide, which both are in the Sensodyne with Novamin tube I have from the UK.
Novamin toothpaste is only sold & mfg in the UK. There are some conspiracy theories going around that the ingredient is so good they won't sell it to us in the US! [1]
I actually buy it off Amazon and use it myself because I have teeth sensitivity and it contains no SLS, which causes some irritation for me. It is quite interesting stuff. I doubt it would have lead since a synthetic compound. [2]
The pair of animations on the page are beautifully done, not just technically but aesthetically as well. If the rest of the book is like that I'll be getting a copy.
I would wager a sizeable chunk of the people here have no idea about the nature of this site's ownership/origin. This crowd finds this sort of thing to be a sort of astro-turfing - not communal.
The MIT license is basically the license of choice for growth hacking these days. Many VC backed companies follow this strategy - it serves to grow your userbase, a free-tier for developers using your ecosystem and last but not least, a chance for volunteers to do free work for you.
This is perhaps too cynical for this specific instance, but it's not overly cynical more broadly. Considering users of the site have to evaluate many of these offerings frequently, I don't blame them for having a negative gut reaction.
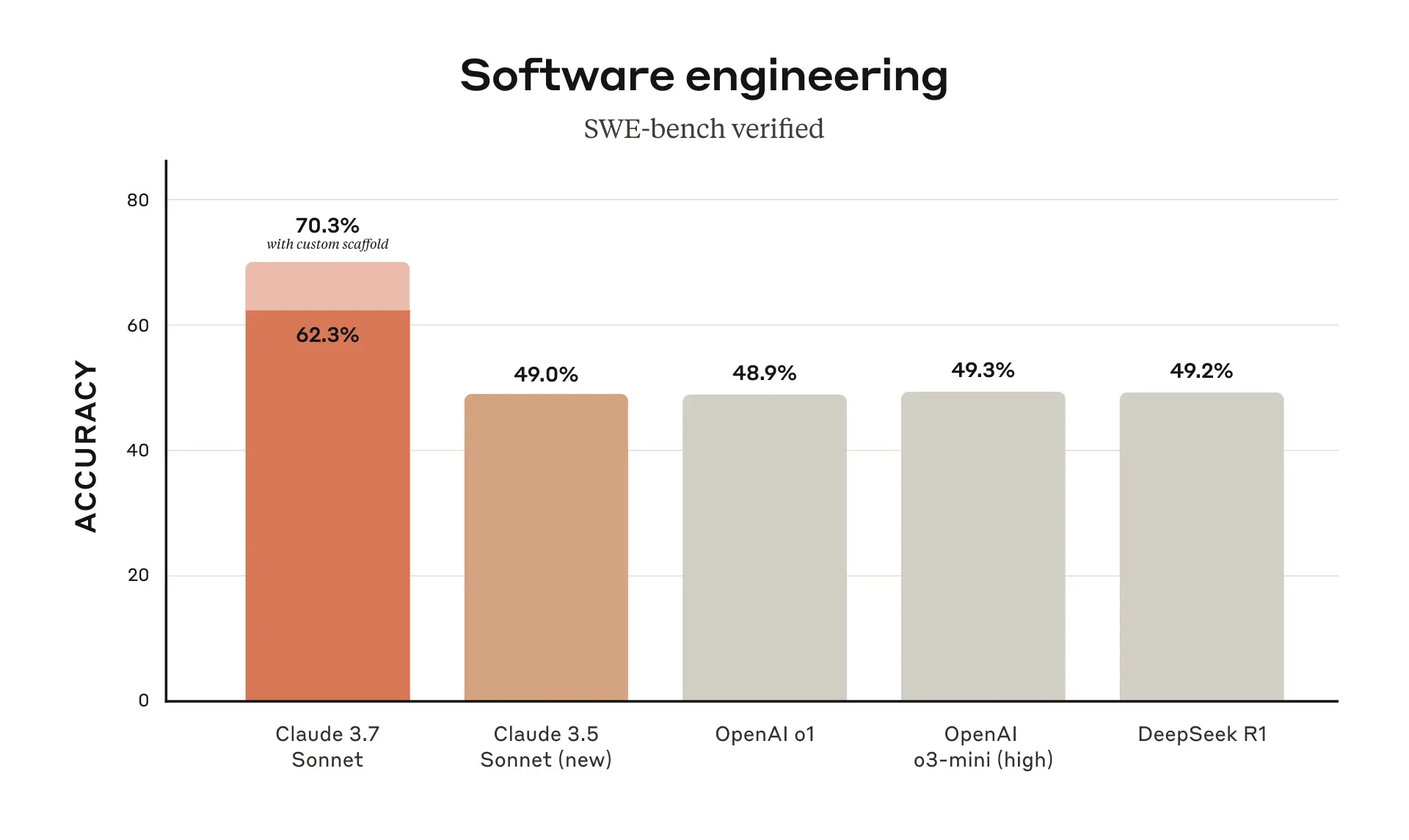
Very impressive! But under arguably the most important benchmark -- SWE-bench verified for real-world coding tasks -- Claude 3.7 still remains the champion.[1]
Incredible how resilient Claude models have been for best-in-coding class.
[1] But by only about 1%, and inclusive of Claude's "custom scaffold" augmentation (which in practice I assume almost no one uses?). The new OpenAI models might still be effectively best in class now (or likely beating Claude with similar augmentation?).
Gemini 2.5 Pro is widely considered superior to 3.7 Sonnet now by heavy users, but they don't have an SWE-bench score. Shows that looking at one such benchmark isn't very telling. Main advantage over Sonnet being that it's better at using a large amount of context, which is enormously helpful during coding tasks.
Sonnet is still an incredibly impressive model as it held the crown for 6 months, which may as well be a decade with the current pace of LLM improvement.
This was incredibly irritating at first, though over time I've learned to appreciate this "extra credit" work. It can be fun to see what Claude thinks I can do better, or should add in addition to whatever feature I just asked for. Especially when it comes to UI work, Claude actually has some pretty cool ideas.
If I'm using Claude through Copilot where it's "free" I'll let it do its thing and just roll back to the last commit if it gets too ambitious. If I really want it to stay on track I'll explicitly tell it in the prompt to focus only on what I've asked, and that seems to work.
And just today, I found myself leaving a comment like this:
//Note to Claude: Do not refactor the below. It's ugly, but it's supposed to be that way.
Never thought I'd see the day I was leaving comments for my AI agent coworker.
Claude is almost comically good outside of copilot. When using through copilot it’s like working with a lobotomized idiot (that complains it generated public code about half the time).
It used to be good, or at least quite decent in GH Copilot, but it all turned into poop (the completions, the models, everything) ever since they announced the pricing changes.
Considering that M$ obviously trains over GitHub data, I'm a bit pissed, honestly, even if I get GH Copilot Pro for free.
What language / framework are you using? I ask because in a Node / Typescript / React project I experience the opposite- Claude 3.7 usually solves my query on the first try, and seems to understand the project's context, ie the file structure, packages, coding guidelines, tests, etc, while Gemini 2.5 seems to install packages willy-nilly, duplicate existing tests, create duplicate components, etc.
Oh, that must’ve been in the last few days. Weird that it’s only in 2.5 Pro preview but at least they’re headed in the right direction.
Now they just need a decent usage dashboard that doesn’t take a day to populate or require additional GCP monitoring services to break out the model usage.
I do find it likes to subtly reformat every single line thereby nuking my diff and making its changes unusable since I can’t verify them that way, which Sonnet doesn’t do.
I keep seeing this sentiment so often here and on X that I have to wonder if I'm somehow using a different Gemini 2.5 Pro. I've been trying to use it for a couple of weeks already and without exaggeration it has yet to solve a single programming task successfully. It is constantly wrong, constantly misunderstands my requests, ignores constraints, ignores existing coding conventions, breaks my code and then tells me to fix it myself.
Eh, I wouldn't say that's accurate, I think it's situational. I code all day using AI tools and Sonnet 3.7 is still the king. Maybe it's language dependent or something, but all the engineers I know are full on Claude-Code at this point.
The image generation improvement with o4-mini is incredible. Testing it out today, this is a step change in editing specificity even from the ChatGPT 4o LLM image integration just a few weeks ago (which was already a step change). I'm able to ask for surgical edits, and they are done correctly.
There isn't a numerical benchmark for this that people seem to be tracking but this opens up production-ready image use cases. This was worth a new release.
Thanks for sharing that. that was more interesting then their demo. I tried it and it was pretty good! I have felt that the ability to iterate from images blocked this from any real production use I had. This may be good enough now.
also another addition: i previously tried to upload an image for chatgpt to edit and it was incapable under the previous model i tried. Now its able to change uploaded images using o4mini.
Claude got 63.2% according to the swebench.com leaderboard (listed as "Tools + Claude 3.7 Sonnet (2025-02-24)).[0]
OpenAI said they got 69.1% in their blog post.
Yes, however Claude advertised 70.3%[1] on SWE bench verified when using the following scaffolding:
> For Claude 3.7 Sonnet and Claude 3.5 Sonnet (new), we use a much simpler approach with minimal scaffolding, where the model decides which commands to run and files to edit in a single session. Our main “no extended thinking” pass@1 result simply equips the model with the two tools described here—a bash tool, and a file editing tool that operates via string replacements—as well as the “planning tool” mentioned above in our TAU-bench results.
I think you may have misread the footnote. That simpler setup results in the 62.3%/63.7% score. The 70.3% score results from a high-compute parallel setup with rejection sampling and ranking:
> For our “high compute” number we adopt additional complexity and parallel test-time compute as follows:
> We sample multiple parallel attempts with the scaffold above
> We discard patches that break the visible regression tests in the repository, similar to the rejection sampling approach adopted by Agentless; note no hidden test information is used.
> We then rank the remaining attempts with a scoring model similar to our results on GPQA and AIME described in our research post and choose the best one for the submission.
> This results in a score of 70.3% on the subset of n=489 verified tasks which work on our infrastructure. Without this scaffold, Claude 3.7 Sonnet achieves 63.7% on SWE-bench Verified using this same subset.
I think reading this makes it even clearer that the 70.3% score should just be discarded from the benchmarks. "I got a 7%-8% higher SWE benchmark score by doing a bunch of extra work and sampling a ton of answers" is not something a typical user is going to have already set up when logging onto Claude and asking it a SWE style question.
Personally, it seems like an illegitimate way to juice the numbers to me (though Claude was transparent with what they did so it's all good, and it's not uninteresting to know you can boost your score by 8% with the right tooling).
I haven't been following them that closely, but are people finding these benchmarks relevant? It seems like these companies could just tune their models to do well on particular benchmarks
The benchmark is something you can optimize for, doesn't mean it generalize well. Yesterday I tried for 2 hours to get claude to create a program that would extract data from a weird adobe file. 10$ later, the best I had is a program that was doing something like:
switch(testFile) {
case "test1.ase": // run this because it's a particular case
case "test2.ase": // run this because it's a particular case
default: // run something that's not working but that's ok because the previous case should
// give the right output for all the test files ...
}
Also, if you're using Cursor AI, it seems to have much better integration with Claude where it can reflect on its own things and go off and run commands. I don't see it doing that with Gemini or the O1 models.
{kind=link}
1. Software engineering isn't "real" engineering.
2. Nobody cares about bugs when they write software in the first place.
3. Software is hard.
4. Software is early.