Mandos works with initramfs images created by both initramfs-tools and Dracut, and is present in Debian since 2011, so no need to use a third-party package.
Washington State “Enhanced ID” (which is also REALID compliant) was one of the first DHS-approved IDs from way back in 2005 . Ari Jeuls et al (see below) found a number of vulns including remote cloning and remote disablement, publishing their findings a few years after the launch.
I talked to WA DOL Privacy Officer about it a couple years ago, and found that the tech platform had remained unchanged. WA maintains the printed material and DHS maintains the RFID package which is over 20 years old now .
Think of other 20 year old tech and how safe you feel having that in your wallet.
For lightweight sandboxing on Linux you can use bubblewrap or firejail instead of Docker. They are faster and _simpler_. Here is a bwrap script I wrote to run Claude in a minimal sandbox an hour back:
NATS is very good. It's important to distinguish between core NATS and Jetstream, however.
Core NATS is an ephemeral message broker. Clients tell the server what subjects they want messages about, producers publish. NATS handles the routing. If nobody is listening, messages go nowhere. It's very nice for situations where lots of clients come and go. It's not reliable; it sheds messages when consumers get slow. No durability, so when a consumer disconnects, it will miss messages sent in its absence. But this means it's very lightweight. Subjects are just wildcard paths, so you can have billions of them, which means RPC is trivial: Send out a message and tell the receiver to post a reply to a randomly generated subject, then listen to that subject for the answer.
NATS organizes brokers into clusters, and clusters can form hub/spoke topologies where messages are routed between clusters by interest, so it's very scalable; if your cluster doesn't scale to the number of consumers, you can add another cluster that consumes the first cluster, and now you have two hubs/spokes. In short, NATS is a great "message router". You can build all sorts of semantics on top of it: RPC, cache invalidation channels, "actor" style processes, traditional pub/sub, logging, the sky is the limit.
Jetstream is a different technology that is built on NATS. With Jetstream, you can create streams, which are ordered sequences of messages. A stream is durable and can have settings like maximum retention by age and size. Streams are replicated, with each stream being a Raft group. Consumers follow from a position. In many ways it's like Kafka and Redpanda, but "on steroids", superficially similar but just a lot richer.
For example, Kafka is very strict about the topic being a sequence of messages that must be consumed exactly sequentially. If the client wants to subscribe to a subset of events, it must either filter client-side, or you have some intermediary that filters and writes to a topic that the consumer then consumes. With NATS, you can ask the server to filter.
Unlike Kafka, you can also nack messages; the server keeps track of what consumers have seen. Nacking means you lose ordering, as the nacked messages come back later. Jetstream also supports a Kafka-like strictly ordered mode. Unlike Kafka, clients can choose the routing behaviour, including worker style routing and deterministic partitioning.
Unlike Kafka's rigid networking model (consumers are assigned partitions and they consume the topic and that's it), as with NATS, you can set up complex topologies where streams get gatewayed and replicated. For example, you can streams in multiple regions, with replication, so that consumers only need to connect to the local region's hub.
While NATS/Jetstream has a lot of flexibility, I feel like they've compromised a bit on performance and scalability. Jetstream clusters don't scale to many servers (they recommend max 3, I think) and large numbers of consumers can make the server run really hot. I would also say that they made a mistake adopting nacking into the consuming model. The big simplification Kafka makes is that topics are strictly sequential, both for producing and consuming. This keeps the server simpler and forces the client to deal with unprocessable messages. Jetstream doesn't allow durable consumers to be strictly ordered; what the SDK calls an "ordered consumer" is just an ephemeral consumer. Furthermore, ephemeral consumers don't really exist. Every consumer will create server-side state. In our testing, we found that having more than a few thousand consumers is a really bad idea. (The newest SDK now offers a "direct fetch" API where you can consume a stream by position without registering a server-side consumer, but I've not yet tried it.)
Lastly, the mechanics of the server replication and connectivity is rather mysterious, and it's hard to understand when something goes wrong. And with all the different concepts — leaf nodes, leaf clusters, replicas, mirrors, clusters, gateways, accounts, domains, and so on — it's not easy to understand the best way to design a topology. The Kafka network model, by comparison, is very simple and straightforward, even if it's a lot less flexible. With Kafka, you can still build hub/spoke topologies yourself by reading from topics and writing to other topics, and while it's something you need to set up yourself, it's less magical, and easier to control and understand.
Where I work, we have used NATS extensively with great success. We also adopted Jetstream for some applications, but we've soured on it a bit, for the above reasons, and now use Redpanda (which is Kafka-compatible) instead. I still think JS is a great fit for certain types of apps, but I would definitely evaluate the requirements carefully first. Jetstream is different enough that it's definitely not just a "better Kafka".
What they do is ground the LLM to the AST with Babel to ensure you still get the same shape of AST out of your deobfuscation pass. Probably this tool could be cleaned up, made to work with multiple llm and parser backends, have its prompts improved, &c.
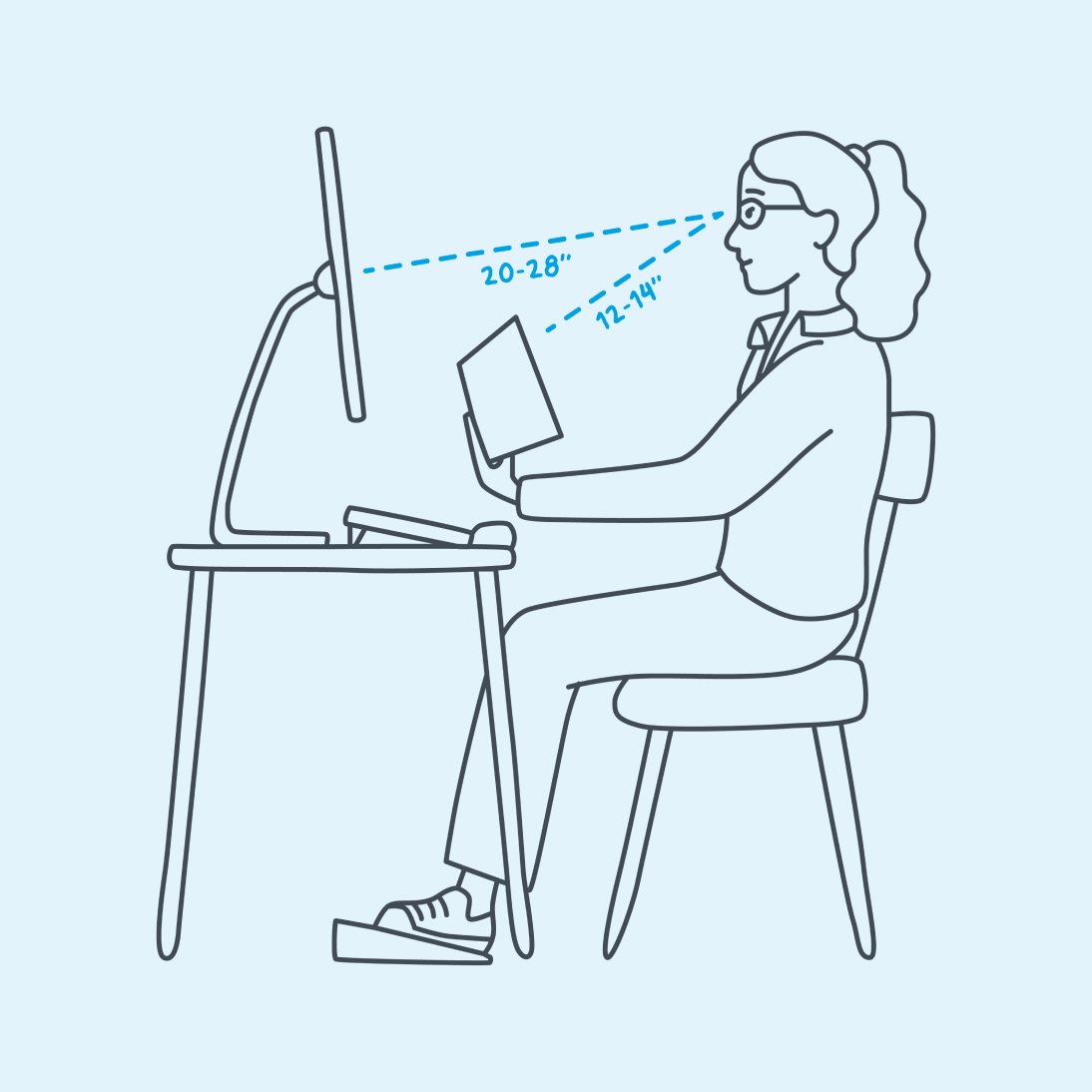
The solution for me to eliminate headaches when working at computer screens was getting an extra set of intermediate distance glasses specifically for computer work. The "computer screen distance" of 3 ft is in between book-reading distance of 1 feet and driving distance 20'+ feet. I also avoid progressive lenses or high-index lenses for computer work. I commented about how arrived at this solution previously: https://news.ycombinator.com/item?id=15375221
Reading glasses work fine when the screen is very close to your face such as a laptop screen. However if it's a separate monitor that's ~30 inches away, reading glasses are slightly blurry which can lead to eyestrain and headaches.
https://github.com/m-bain/whisperX looks promising - I'm hacking away on an always-on transcriber for my notes for later search&recall. It has support for diarization (the speaker detection you're looking for).
But overall it's pretty simple to do after you wrangle the Python dependencies - all you need is a sink for the text files (for example, create a new file for every Teams meeting, but that's another story...)
Here in Seattle the underground part of the city is open for tours (parts of it anyways). They built the current downtown on top of the old one, so it's pretty surreal down there.
Not even tunnels in this case, just like a whole-ass other set of streets and storefronts, all abandoned, partially buried, and covered on top.
So, I just did this recently. This is an ok article for beginners. I’d hesitate to even mention l2arc or slog devices to someone that isn’t an experienced technical user, though, as they will probably go buy the wrong drives and may not even need the added complexity. I’m not using them and I see high write and read speeds from a zpool with 2x2 mirrored vdevs (wd reds).
If the hardware is remotely capable I’d probably advise running proxmox and spinning up a turnkey Linux fileserver container with bind mounts to the underlying zfs filesystem to use as the main samba share manager. This makes it easier for less technical people to manage the users and permissions and stuff with a web gui. I had some trouble getting zfs sambasharing to work with sharesmb=on (not sure where those configs are stored on proxmox, and if it can do everything samba normally can), but you can try that route to or use sharenfs to set up NFS shares.
There are a bunch of options for ACLs in zfs you probably want turned on , acltype and aclmode, and xattr=sa. Also case sensitivity and the case normalization stuff. And atime=off. Does anyone ever actually use access time because I can’t think of any use case for that on my nas!?
To go beyond chmod, you probably want to learn about setfacl and getfacl and set some sane ACLs so your folders and files are created with the correct permissions. If you are sharing stuff with other users, this becomes a problem real quick unless you’ve got the ACLs set right and things get created with 775/664 perms. I like to also set chmod g+s so the default group of anything is the group of the parent, not the current users primary group.
Lastly, if you’re on zfs you can setup something like sanoid to automate snapshots. I just did that, hopefully it will save me next time I run rm -rf against the wrong folder by accident!
I left California for Nevada many years ago, and I subsequently sold stock I accumulated while in California without paying state income tax.
It is legal and you can do it, but there are a lot of legal hurdles. They're pretty well documented around page 5 of FTB 1031 [1].
In my case, I quit my W2 job in California, entered into a contract to lease a home in NV, got rid of all leased or owned real estate in CA, sold or re-titled all motor vehicles from CA, registered to vote in NV, surrendered my CA driver license for a new NV license, re-titled all my financial accounts at my new address, got a NV phone number, etc.
This was all easy because I was single without children. If my situation was more complicated, like I had a spouse or ex-spouse with children enrolled in CA schools, or decided to retain owned real estate in CA, the situation can quickly fall into a gray zone.
If you have a W2 job in CA while claiming you're in NV, it's very hard to escape the CA FTB.
CA is very aggressive about chasing down its former residents. It's important to check all the boxes to get them from chasing you.
After I left, I filed non-resident CA returns for three years basically saying, "I had income but I am not a resident and it was not from a CA source, therefore I owe no CA tax." This is important because it starts the statute of limitations running. If you don't file, the statute of limitations doesn't start.
And while I'm writing all this: what in the world is up with a 13.3% state tax bracket? Screw California.
Collections PSA: Collections is regulated under FDCPA/FCRA. If you as a reader are in a similar situation, please review the the below resources. Do not tolerate misreporting of information to CRAs (credit reporting agencies) by creditors, nor pursuit by collections firms. Do not communicate with phone calls or use apps to dispute. Do use certified mail return receipt for correspondence while building your paper trail. Do demand validation of an alleged debt in a timely fashion. Do file a CFPB complaint and/or consult with an attorney to sue a debt collector when warranted.
Fidelity Visa is 2% on everything, no cap, no annual fee.
Citi DoubleCash is 2% on everything, dunno if there's a cap, no annual fee. (you have to redeem into a bank account, not as statement credit, to get the full 2%)
USAA Limitless is 2.5% cash back on everything, no cap. (military only, no longer available), no annual fee.
If you have enough cash invested with Merrill Edge ($100,000, including IRAs) the Bank of America Travel Rewards earns 2.625% cash back on everything, not sure of a cap, no annual fee.
If you value Membership Rewards at more than a cent, the American Express Blue Business Plus earns 2 Membership Rewards per dollar spent on everything, $50,000 cap, no annual fee.
Discover IT Miles earns 3% cash back on everything the first year, churnable (you can get a new one every year), no cap, no annual fee.
Alliant Credit Union Cashback Visa earns 3% on everything the first year and 2.5% after that, $60 annual fee (waived the first year), dunno of a cap.
Capital One Venture is (basically) 2% cash back on everything, $95 fee (which they usually waive if you ask),no cap. Only redeemable towards travel. Has a fairly large signup bonus.
Barclaycard Arrival Plus is 2% on everything, $95 annual fee, not sure of the cap. Only redeemable towards travel. Has a fairly large signup bonus.
Paypal Mastercard is 2% on everything, no annual fee, dunno of a cap.
Those are your basic options for no-fuss 2%+ cash back cards. If ApplePay is required to earn 2%, then I'd say the majority of those cards are better; my biggest expenses every month are bills (phone, internet, insurance, oil, electricity, etc) and I don't think I can use ApplePay to pay any of those.
Add up all your monthly debt service obligations (credit cards, student loans, car payment, etc - use the minimum payment). This is your current debt obligation.
Your pretax monthly income is $5833. 36% of that is $2100. The maximum a lender will loan you will result in a monthly payment of ($2100 - your current debt obligation).
For example, if you have $1k/mo in debt service, you have $1100 margin left in your debt-to-income ratio for a mortgage. At 4%, that's a maximum mortgage amount of roughly $145k.
If you have all $2100 to allocate to the mortgage, that allows a mortgage in the $300k range, varying with property tax and insurance rates.
The number and seriousness of these errors and how easy it is to make them does raise questions about how sensible it is to use JWT, unless you're really sure about what you're doing.
Bog standard blockchain antidote, feel free to steal and reuse as needed (or disregard as usual):
If participants are willing trust some subset of other participants within the system for certain privileged tasks that are required by the design of this system, why would they not be willing to trust another subset of participant to operate data storage for the system? Note the potential that most any kind of datastore can underlie systems providing replication, operation of copies by multiple independent parties, consistency guarantees, availability through redundancy.
What potential byzantine faults exist in the design of the system such that providing fault tolerance benefits the system? Can those be eliminated by a better design? Can the risks posed by faults be absorbed or mitigated by the administrative/business/legal infrastructure for the system (which probably will have to exist, regardless)?
If byzantine fault tolerance is required, why is a ledger + immutable chain of history objects + Proof-of-* system the most suitable byzantine fault tolerance solution for the system, given inefficiencies (Cost of Proof-of-*, constraints on throughput), inconveniences (Immutability), and introduction of complexity which is auxiliary to the intended purpose of the system (a ledger of currency)?
Do participants have insufficient incentive to participate in the system such that providing them a balance of a currency is required? Can the system be redesigned to better incentivize those participants? If the system provides little incentive to participate in it from its primary purposes, is there any utility in creating the system at all? Does attracting participation from participants uninterested in the primary and ancillary functions of the system to speculate in the value of an auxillary currency pose a benefit to or liability upon the system?
If participants are motivated primarily due to the fashionableness of blockchain technology, do they realize it's not 2017 anymore, what will happen to the system when they catch up and get bored? Is there a way to use an "AI" instead?
I've never used GitLab, and I'm curious if it's something my company could use.
Almost all our Github projects use Docker. We don't use automatic deploys at the moment, but CI basically consists of building a Dockerfile, then running tests with "docker-compose run", then pushing the image to GCR.
We do have some projects that consist of multiple dockerfiles, but they're outliers. Everything else follows the same convention.
We currently use Semaphore, which has several downsides:
* Every project needs to be created and configured individually. We have many, many small projects. On Semaphore, setting up a project requires clicking through 4 or 5 screens to configure. I know Semaphore has an API (two incompatible ones, actually), but that means we have to write code for something that should be included in the box.
* To alleviate this burden, we have a single shell script, hosted with HTTPS and basic auth, that every project runs to build. It does things like log into GCR, set up secret build args, then do the build. Again, stuff that's identical across all projects. It's a bit silly to fetch this script every time rather than have it be shared across the whole organization.
* Semaphore's Docker layer caching (achieved with docker pull + docker build --cache-from) seems inconsistent. Some builds are fast, some don't get any caching.
* Semaphore is terrible at describing test failures. You'd think that a CI system would be great at doing things like show "4 failures/2 skipped/123 successful" on some kind of board. But instead you just get success/failure, and the entire build log. If the test is something like "go test", then you get 99% noise, and it's hard to zero in on what the failure was. I'd love to get the actual failing test in the Slack notification.
We've tried a few alternatives:
* Self-hosted Drone: Great, but too immature when we ran it, and development seems slow, with the organization behind apparently focused on a SaaS solution?
* Google Cloud Container Builder: Better, but requires each project to be "mirrored" within Google Cloud, which is a pain, and the mirroring is flaky. Also, no layer caching. And apparently not appropriate for running Docker Compose tests, and secrets management requires more tendrils into GCP, whereas we prefer things to be ore self-contained.
* CircleCI: Similar problems as Semaphore. Seemed a bit messy.
{kind=link}
Mandos works with initramfs images created by both initramfs-tools and Dracut, and is present in Debian since 2011, so no need to use a third-party package.